

1 kubernetes 概述
1.1 kubernetes 基本介绍
kubernetes,简称K8s,是用8 代替8个字符“ubernete”而成的缩写。是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes 的目标是让部署容器化的应用简单并且高效(powerful),Kubernetes 提供了应用部署,规划,更新,维护的一种机制。
传统的应用部署方式是通过插件或脚本来安装应用。这样做的缺点是应用的运行、配置、管理、所有生存周期将与当前操作系统绑定,这样做并不利于应用的升级更新/回滚等操作,当然也可以通过创建虚拟机的方式来实现某些功能,但是虚拟机非常重,并不利于可移植性。
新的方式是通过部署容器方式实现,每个容器之间互相隔离,每个容器有自己的文件系统,容器之间进程不会相互影响,能区分计算资源。相对于虚拟机,容器能快速部署,由于容器与底层设施、机器文件系统解耦的,所以它能在不同云、不同版本操作系统间进行迁移。
容器占用资源少、部署快,每个应用可以被打包成一个容器镜像,每个应用与容器间成一对一关系也使容器有更大优势,使用容器可以在build 或release 的阶段,为应用创建容器镜像,因为每个应用不需要与其余的应用堆栈组合,也不依赖于生产环境基础结构,这使得从研发到测试、生产能提供一致环境。类似地,容器比虚拟机轻量、更“透明”,这更便于监控和管理。
Kubernetes 是Google 开源的一个容器编排引擎,它支持自动化部署、大规模可伸缩、应用容器化管理。在生产环境中部署一个应用程序时,通常要部署该应用的多个实例以便对应用请求进行负载均衡。
在Kubernetes 中,我们可以创建多个容器,每个容器里面运行一个应用实例,然后通过内置的负载均衡策略,实现对这一组应用实例的管理、发现、访问,而这些细节都不需要运维人员去进行复杂的手工配置和处理。
1.2 kubernetes 功能和架构
1.2.1 K8s 功能
Kubernetes 是一个轻便的和可扩展的开源平台,用于管理容器化应用和服务。通过Kubernetes 能够进行应用的自动化部署和扩缩容。在Kubernetes 中,会将组成应用的容器组合成一个逻辑单元以更易管理和发现。Kubernetes 积累了作为Google 生产环境运行工作负载15 年的经验,并吸收了来自于社区的最佳想法和实践。
- 自动装箱:基于容器对应用运行环境的资源配置要求自动部署应用容器
- 自我修复(自愈能力):当容器失败时,会对容器进行重启当所部署的Node 节点有问题时,会对容器进行重新部署和重新调度当容器未通过监控检查时,会关闭此容器直到容器正常运行时,才会对外提供服务
- 水平扩展:通过简单的命令、用户UI 界面或基于CPU 等资源使用情况,对应用容器进行规模扩大或规模剪裁
- 服务发现:用户不需使用额外的服务发现机制,就能够基于Kubernetes 自身能力实现服务发现和负载均衡
- 滚动更新:可以根据应用的变化,对应用容器运行的应用,进行一次性或批量式更新
- 版本回退:可以根据应用部署情况,对应用容器运行的应用,进行历史版本即时回退
- 密钥和配置管理:在不需要重新构建镜像的情况下,可以部署和更新密钥和应用配置,类似热部署。
- 存储编排:自动实现存储系统挂载及应用,特别对有状态应用实现数据持久化非常重要存储系统可以来自于本地目录、网络存储(NFS、Gluster、Ceph 等)、公共云存储服务
- 批处理:提供一次性任务,定时任务;满足批量数据处理和分析的场景
1.2.2 k8s集群架构
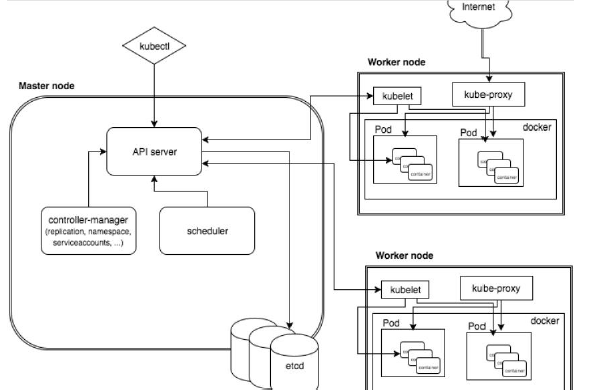
k8s 集群架构包括Master(主控结点)和Node(工作节点)
Master组件:
- API Server:集群统一入口,以Restful方式,交给Etcd存储
- Scheduler:节点调度,选择node结点应用部署
- Controller MangerServer:处理集群中常规后台任务,一个资源对应一个控制出去
- ClusterState Store(ETCD 数据库):存储系统,用于保存集群相关的数据
Node组件:
- kubelet:Master在Node中的Agent,管理容器中各个操作
- kube proxy:提供网络代理,实现负载均衡等操作
1.2.3 k8s核心概念
这里简要介绍一下,具体后面会提到
- Pod
Pod 是k8s 系统中可以创建和管理的最小单元,是一组容器的集合,同一个Pod共享网络,生命周期较为短暂
- Controller 控制器
Controller用于确保预期的Pod的副本数量,可以使用两种状态应用部署,确保所有的node运行同一个pod,支持一次性任务和定时任务
- Service
定义一组pod的访问规则
过程大概是:
通过Service统一入口进行访问,然后由Controller创建Pod
2 kubernetes集群搭建
2.1 部署方式
目前生产部署Kubernetes 集群主要有两种方式:
- kubeadm
Kubeadm 是一个K8s 部署工具,提供kubeadm init 和kubeadm join,用于快速部署Kubernetes 集群。官方地址:https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm/
- 二进制包
从github 下载发行版的二进制包,手动部署每个组件,组成Kubernetes 集群。Kubeadm 降低部署门槛,但屏蔽了很多细节,遇到问题很难排查。如果想更容易可控,推荐使用二进制包部署Kubernetes 集群,虽然手动部署麻烦点,期间可以学习很多工作原理,也利于后期维护。
2.2 使用kubeadm搭建k8s集群
2.2.1 准备环境
| 角色 | IP |
|---|---|
| master | 192.168.18.131 |
| node1 | 192.168.18.132 |
| node2 | 192.168.18.133 |
# 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
# 关闭selinux
sed -i 's/enforcing/disabled/' /etc/selinux/config # 永久
setenforce 0 # 临时
# 关闭swap
swapoff -a # 临时
sed -ri 's/.*swap.*/#&/' /etc/fstab # 永久
# 根据规划设置主机名
hostnamectl set-hostname <hostname>
# 在master添加hosts
cat >> /etc/hosts << EOF
192.168.18.131 master
192.168.18.132 node1
192.168.18.133 node2
EOF
# 将桥接的IPv4流量传递到iptables的链
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system # 生效
# 时间同步
yum install ntpdate -y
ntpdate time.windows.com
2.2.2 安装软件
2.2.2.1 安装Docker
Docker CE 支持 64 位版本 CentOS 7,并且要求内核版本不低于 3.10, CentOS 7 满足最低内核的要求,所以我们在CentOS 7安装Docker。
如果之前安装过旧版本的Docker,可以使用下面命令卸载:
yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-selinux \
docker-engine-selinux \
docker-engine \
docker-ce
首先需要大家虚拟机联网,安装yum工具
yum install -y yum-utils \
device-mapper-persistent-data \
lvm2 --skip-broken
然后更新本地镜像源:
# 设置docker镜像源
yum-config-manager \
--add-repo \
https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
sed -i 's/download.docker.com/mirrors.aliyun.com\/docker-ce/g' /etc/yum.repos.d/docker-ce.repo
yum makecache fast
然后输入命令:
yum install -y docker-ce
docker-ce为社区免费版本。稍等片刻,docker即可安装成功。
通过命令启动docker:
systemctl start docker # 启动docker服务
systemctl stop docker # 停止docker服务
systemctl restart docker # 重启docker服务
然后输入命令,可以查看docker版本:
docker -v
docker官方镜像仓库网速较差,我们需要设置国内镜像服务:
参考阿里云的镜像加速文档:https://cr.console.aliyun.com/cn-hangzhou/instances/mirrors
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["加速器地址"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
设置docker开机自启
systemctl enable docker.service
2.2.2.2 安装kubeadm,kubelet和kubectl
由于版本更新频繁,这里指定版本号部署:
yum install -y kubelet-1.18.0 kubeadm-1.18.0 kubectl-1.18.0
systemctl enable kubelet
2.2.3 部署Kubernetes Master
在192.168.18.131(Master)执行。
kubeadm init \
--apiserver-advertise-address=192.168.18.131 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.18.0 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16
可以看到提示,告诉我们要执行什么命令
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.18.131:6443 --token zui1ov.w8yz2q0zy4383loz \
--discovery-token-ca-cert-hash sha256:e120cc1e8da1ff293c0916ae613b1c627d0f481d06f729bb06fe215910928730
执行
[root@localhost ~]# mkdir -p $HOME/.kube
[root@localhost ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@localhost ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
[root@localhost ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
localhost.localdomain NotReady master 3m53s v1.18.0
将node节点加入到master
kubeadm join 192.168.18.131:6443 --token zui1ov.w8yz2q0zy4383loz \
--discovery-token-ca-cert-hash sha256:e120cc1e8da1ff293c0916ae613b1c627d0f481d06f729bb06fe215910928730
若报错
[root@node1 ~]# kubeadm join 10.5.1.5:6443 --token 1a8fot.izehoikcbfm6vcj6 --discovery-token-ca-cert-hash sha256:41498e76da4b483ec99963948303e3df1d0a4308bb096d33f77d6f8f42e53e63 W0203 17:56:00.454059 11793 join.go:346] [preflight] WARNING: JoinControlPane.controlPlane settings will be ignored when control-plane flag is not set. [preflight] Running pre-flight checks error execution phase preflight: [preflight] Some fatal errors occurred: [ERROR FileAvailable--etc-kubernetes-kubelet.conf]: /etc/kubernetes/kubelet.conf already exists [ERROR FileAvailable--etc-kubernetes-pki-ca.crt]: /etc/kubernetes/pki/ca.crt already exists [preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...` To see the stack trace of this error execute with --v=5 or higher删除相关配置重新加入
[root@localhost ~]# rm -f /etc/kubernetes/kubelet.conf [root@localhost ~]# rm -f /etc/kubernetes/pki/ca.crt [root@localhost ~]# kubeadm join 192.168.18.131:6443 --token zui1ov.w8yz2q0zy4383loz \ --discovery-token-ca-cert-hash sha256:e120cc1e8da1ff293c0916ae613b1c627d0f481d06f729bb06fe215910928730
2.2.4 部署CNI网络插件
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
默认镜像地址无法访问,sed命令修改为docker hub镜像仓库。
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
kube-flannel-ds-amd64-2pc95 1/1 Running 0 72s
2.2.5 测试kubernetes集群
在Kubernetes集群中创建一个pod,验证是否正常运行:
$ kubectl create deployment nginx --image=nginx
$ kubectl expose deployment nginx --port=80 --type=NodePort
$ kubectl get pod,svc
访问地址:http://NodeIP:Port
3 kubectl
kubectl 是Kubernetes 集群的命令行工具,通过kubectl 能够对集群本身进行管理,并能够在集群上进行容器化应用的安装部署。
3.1 kubectl 命令的语法
kubectl [command] [Type] [Name] [flags]
- command:指定要对资源执行的操作,例如create、get、describe 和delete
- TYPE:指定资源类型,资源类型是大小写敏感的,开发者能够以单数、复数和缩略的形式
- NAME:指定资源的名称,名称也大小写敏感的。如果省略名称,则会显示所有的资源
- flags:指定可选的参数。例如,可用-s 或者–server 参数指定Kubernetes API server 的地址和端口。
获取更多信息可以用
kubectl --help
3.2 kubectl 子命令使用分类
3.2.1 基础命令
| 命令 | 解释 |
|---|---|
| create | 通过文件名或标准输入创建资源 |
| expose | 将一个资源公开为一个新的Service |
| run | 在集群中运行一个特定的镜像 |
| set | 在对象上设定特定的功能 |
| get | 显示一个或多个资源 |
| explain | 文档参考资料 |
| edit | 使用默认的编辑器编辑一个资源 |
| delete | 通过文件名、标准输入、资源名称或标签选择器来删除资源 |
3.2.2 部署和集群管理命令
| 命令 | 解释 |
|---|---|
| rollout | 管理资源的发布 |
| rolling-update | 对给定的复制控制器滚动更新 |
| scale | 扩容或缩容Pod数量,Deployment、ReplicaSet、IRC或Job |
| autoscale | 创建一个自动选择扩容或缩容并设置Pod数量 |
| certificate | 修改证书资源 |
| cluster-info | 显示集群信息 |
| top | 显示资源(CPU/Memory/Storage)使用。需要Heapster运行 |
| cordon | 标记节点不可调度 |
| uncordon | 标记节点可调度 |
| drain | 驱逐节点上的应用,准备下线维护 |
| taint | 修改节点taint标记 |
3.2.3 故障和调试命令
| 命令 | 解释 |
|---|---|
| describe | 显示特定资源或资源组的详细信息 |
| logs | 在一个Pod中打印一个容器日志。如果Pod只有一个容器,容器名称是可选的 |
| attach | 附加到一个运行的容器 |
| exec | 执行命令到容器 |
| port-forward | 转发一个或多个本地端口到一个pod |
| proxy | 运行一个proxy到Kubernetes Api server |
| cp | 拷贝文件或目录到容器中 |
| auth | 检查授权 |
3.2.4 其他命令
| 命令 | 解释 |
|---|---|
| apply | 通过文件名或标准输入对资源应用配置 |
| patch | 使用补丁修改、更新资源的字段 |
| replace | 通过文件名或标准输入替换一个资源 |
| convert | 不同Api版本之间转换配置文件 |
| label | 更新资源上的标签 |
| annotate | 更新资源上的注释 |
| completion | 用于实现kubectl工具自动补全 |
| api-versions | 打印受支持的API版本 |
| config | 修改kubeconfig文件(用于访问API,比如配置认证信息) |
| help | 所有命令帮助 |
| plugin | 运行一个命令行插件 |
| version | 打印客户端和服务版本信息 |
4 资源编排
4.1 YAML 文件概述
k8s 集群中对资源管理和资源对象编排部署都可以通过声明样式(YAML)文件来解决,也就是可以把需要对资源对象操作编辑到YAML 格式文件中,我们把这种文件叫做资源清单文件,通过kubectl 命令直接使用资源清单文件就可以实现对大量的资源对象进行编排部署了。
4.2 YAML 文件书写格式
4.2.1 YAML 介绍
YAML :仍是一种标记语言。为了强调这种语言以数据做为中心,而不是以标记语言为重点。
YAML 是一个可读性高,用来表达数据序列的格式。
4.2.2 YAML 基本语法
- 使用空格做为缩进
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
- 低版本缩进时不允许使用Tab 键,只允许使用空格
- 使用#标识注释,从这个字符一直到行尾,都会被解释器忽略
4.2.3 YAML 的组成部分
- 控制器的定义
- 被控制的对象
4.2.4 常用字段含义
| 参数名 | 类型 | 说明 |
|---|---|---|
| apiVersion | String | K8S API版本,目前基本是v1,可以用kubectl api-version查询 |
| kind | String | yaml文件定义的资源类型和角色,比如Pod |
| metadata | Object | 资源的元数据对象,固定值写metadata |
| Spec | Object | 详细定义对象,资源规格等 |
| replicas | Integer | 副本的数量 |
| selector | Object | 标签选择器 |
| template | Object | Pod模板 |
| metadata | Object | Pod元数据 |
| spec | Object | Pod规格 |
| containers | List | 容器配置 |
4.2.5 举例说明
创建一个namespace
apiVersion: v1
kind: Namespace
metadata:
name:test
创建一个Pod
apiVersion: v1
kind: pod
metadata:
name: pod1
spec:
containers:
- name: nginx-containers
image: nginx:latest
4.3 如何快速编写yaml文件
- 使用
kubectl create命令生成yaml文件
[root@master ~]# kubectl create deployment web --image=nginx -o yaml --dry-run
W0101 23:04:40.229410 38116 helpers.go:535] --dry-run is deprecated and can be replaced with --dry-run=client.
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: web
name: web
spec:
replicas: 1
selector:
matchLabels:
app: web
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: web
spec:
containers:
- image: nginx
name: nginx
resources: {}
status: {}
- 使用
kubectl get命令导出yaml文件
[root@master ~]# kubectl get deploy nginx -o=yaml --export > my2.yaml
Flag --export has been deprecated, This flag is deprecated and will be removed in future.
[root@master ~]# ls
anaconda-ks.cfg my2.yaml
5 Pod
5.1 Pod概述
基本概念:
- Pod 是k8s 系统中可以创建和管理的最小单元
- 包含多个容器(一组容器的集合)
- 一个Pod中容器共享网络命名空间
- Pod是短暂的
存在意义:
- 创建容器使用docker,一个docker对应一个容器,一个容器有进程,一个容器运行一个应用程序。
- Pod是多进程设计,可以运行多个应用程序
- 一个Pod有多个容器,一个容器里面运行一个应用程序
- Pod的存在也是为了亲密性应用
- 网络直接的调用
- 两个应用之间进行交互
- 两个应用需要频繁调用
5.2 Pod实现机制
5.2.1 共享网络
容器本身是相互隔离的,一个Pod 里的多个容器可以共享存储和网络,可以看作一个逻辑的主机。共享的如namespace,cgroups 或者其他的隔离资源。
Pod 是Kubernetes 的最重要概念,每一个Pod 都有一个特殊的被称为”根容器“的Pause容器,当用户业务容器加入后,会加入到Pause容器中,这个Pause容器会有独立的IP、MAC、PORT,多个容器共享同一network namespace,由此在一个Pod 里的多个容器共享Pod 的IP 和端口namespace,所以一个Pod 内的多个容器之间可以通过localhost 来进行通信,所需要注意的是不同容器要注意不要有端口冲突即可。不同的Pod 有不同的IP,不同Pod 内的多个容器之前通信,不可以使用IPC(如果没有特殊指定的话)通信,通常情况下使用Pod的IP 进行通信。
5.2.2 共享存储
一个Pod 里的多个容器可以共享存储卷,这个存储卷会被定义为Pod 的一部分,并且可以挂载到该Pod 里的所有容器的文件系统上。
5.3 镜像拉取策略
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: nginx
image: nginx: 1.14
imagePullPolicy: Always
# IfNotPresent: 默认值,镜像在宿主机上不存在时才拉取
# Always: 每次创建Pod都会重新拉取一次镜像
# Never: Pod永远不会主动拉取这个镜像
5.4 Pod资源限制
每个Pod 都可以对其能使用的服务器上的计算资源设置限额,Kubernetes 中可以设置限额的计算资源有CPU 与Memory 两种,其中CPU 的资源单位为CPU 数量,是一个绝对值而非相对值。Memory 配额也是一个绝对值,它的单位是内存字节数。
Kubernetes 里,一个计算资源进行配额限定需要设定以下两个参数: Requests 该资源最小申请数量,系统必须满足要求Limits 该资源最大允许使用的量,不能突破,当容器试图使用超过这个量的资源时,可能会被Kubernetes Kill 并重启
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: db
image: mysql
imagePullPolicy: Always
env:
- name: MYSQL_ROOT_PASSWORD
value: "password"
resources:
requests:
cpu: "250m"
memory: "64Mi"
limits:
cpu: "500m"
memory: "128Mi"
5.5 Pod重启策略
apiVersion: v1
kind: Pod
metadata:
name: dns-test
spec:
containers:
- name: busybox
image: busybox:1.28.4
args:
- /bin/sh
- -c
- sleep 36000
restartPolicy: Never
# Always: 当容器终止推出后,总是重启容器,默认策略
# OnFailure: 当容器异常退出(退出状态码非0时),才重启容器
# Never: 当容器终止退出,从不重启容器
5.6 Pod健康检查
容器层面
kubectl get pods
应用层面
- livenessProbe(存活检查):如果检查失败,将杀死容器,根据Pod的restartPolicy来操作
- readinessProbe(就绪检查),如果检查失败,Kubernetes会把Pod从Service endpoints中剔除
Probe支持下面三种检查方法
- httpGet:发送Http请求,返回200-400范围状态码为成功
- exec:执行shell命令返回状态码是0为成功
- tcpSocket:发起TCP Socket建立成功
apiVersion: v1
kind: Pod
metadata:
label:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: busybox:1.28.4
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
5.7 调度策略
5.7.1 创建Pod的过程
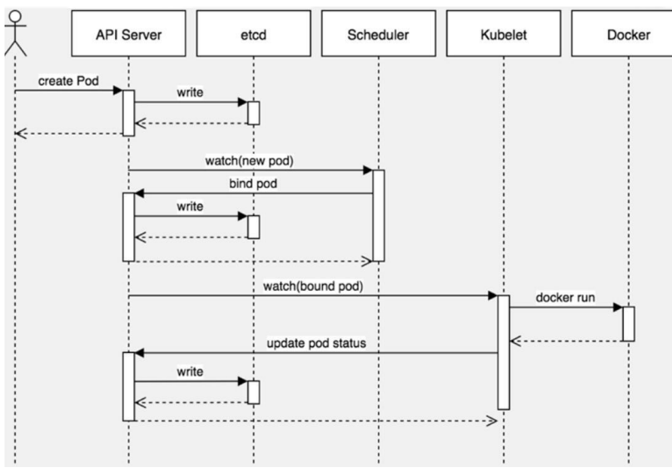
首先,客户端通过API Server 的REST API 或者kubectl 工具创建Pod 资源,API Server 收到用户请求后,存储相关数据到etcd 数据库中,调度器监听API Server 查看为调度(bind)的Pod 列表,循环遍历地为每个Pod 尝试分配节点。kubectl 工具读取etcd 数据接库分配给当前节点Pod,采用Docker创建容器。
5.7.2 影响Pod调度的属性
5.7.2.1 Pod资源限制对Pod调用产生影响
resources:
requests:
memory: "64Mi"
cpu: "250m"
5.7.2.2 节点选择器标签影响pod调度
spec:
nodeSelector:
env_role:dev
containers:
- name: nginx
image: nginx:1.15
5.7.2.3 节点亲和性影响pod调度
亲和性包含两个,硬亲和性和软亲和性
硬亲和性则约束条件必须满足
spec:
affinity:
podAffinity:
# 硬亲和调度
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
#集合选择器
matchExpressions:
# 选择被依赖Pod, 当前pod 要跟标签为app 值为tomcat 的pod 在一起
-{key:app,operator:In,values:["tomcat"]}
# 根据挑选出的Pod 所有节点的hostname作为同一位置的判定
topologyKey:kubernetes.io/hostname
软亲和性指尝试满足,并不保证一定完成
spec:
affinity:
podAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight:80
podAffinityTerm:
labelSelector:
matchExpressions:
-{key:app,operator:In,values:["cache"]}
topologyKey:zone
- weight:20
podAffinityTerm:
labelSelector:
matchExpressions:
-{key:app,operator:In,values:["db"]}
5.7.2.4 污点和污点容忍
污点taints 是定义在节点上的键值型属性数据,用于让节点拒绝将Pod 调度运行于其上,除非Pod 有接纳节点污点的容忍度容忍度tolerations 是定义在Pod 上的键值属性数据,用于配置可容忍的污点,且调度器将Pod 调度至其能容忍该节点污点的节点上或没有污点的节点上
nodeSelector和nodeAffinity:Pod调度到某些节点上,是Pod属性,调度的时候实现
tains: 节点不做普通分配调度,是节点的属性
- 查看节点污点情况

污点值有三个
- NoSchedule: 一定不被调度
- PreferNoSchedule: 尽量不被调度
- NoExecute: 不会调度,并且还会驱逐Node到已有Pod
- 为节点添加污点
# kubectl taint node [node] key=value:[taintValue]
kubectl taint node node1 env_role=yes:PreferNoSchedule
- 删除污点
# kubectl taint node [node] key:[taintValue]-
kubectl taint node node1 env_role:NoSchedule-
- 污点容忍
tolerations:
- key:"key1"
#判断条件为Equal
operator:"Equal"
value:"value1"
effect:"NoExecute"
6 Controller
6.1 Controller概述
controller是在集群上管理和运行容器的对象
Controller用于确保预期的Pod的副本数量,可以使用两种状态应用部署,确保所有的node运行同一个pod,支持一次性任务和定时任务
6.2 Pod和Controller的关系
Pod是通过Controller实现应用的运维,比如伸缩,滚动升级等
6.3 Deployment控制器应用场景
- 部署无状态应用(web、微服务)
- 管理Pod和ReplicaSet副本集数量
- 部署、滚动升级
6.4 无状态和有状态区别
无状态:
- 认为Pod都是一样的
- 没有顺序要求
- 不用考虑哪个Node运行
- 随意进行伸缩扩展
有状态
- 上面的因素都需要考虑到
- 让每个Pod都是独立的,保持Pod启动顺序和唯一性
6.5 Deployment控制器部署无状态应用
kubectl create deployment web --image=nginx --dry-run -o yaml > web.yaml
上面命令的意思是生成一个名字为web的nginx镜像,--dry-run -o yaml指的是暂时不执行,只生成一个yaml文件
执行yaml文件
kubectl apply -f web.yaml
对外暴露端口
kubectl expose deployment web --port=80 -- type=NodePort --target-port=80 --name=web1
6.6 部署有状态应用
部署有状态应用需要使用SatefulSet
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
# 无头Service,部署有状态应用需要指定
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1beta1
# 使用SatefulSet
kind: StatefulSet
metadata:
name: nginx-statefulset
namespace: default
spec:
serviceName: nginx
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
执行yaml文件
kubectl apply -f sts.yaml
Deployment和Statefueset区别:唯一标识的身份
唯一域名:
主机名称.service名称.名称空间.svc.cluster.local
6.7 部署守护进程
在每个node节点上运行的是同一个pod,新加入的node也统一运行在一个pod里面
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: ds-test
labels:
app: filebeat
spec:
selector:
matchLabels:
app: filebeat
template:
metadata:
labels:
app: filebeat
spec:
containers:
- name: logs
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: varlog
mountPath: /tmp/log
volumes:
- name: varlog
hostPath:
path: /var/log
6.8 升级回滚
版本升级
kubectl set image deployment web nginx=nginx:1.15
查看升级状态
kubectl roolout status deployment web
查看历史版本
kubectl roolout history deployment web
回退到上一个版本
kubectl roolout undo deployment web
回退到指定版本
kubectl roolout undo deployment web --to-revision=2
6.9 弹性伸缩
当请求访问过多时,可以提供更多的应用来提供服务
kubectl scale deployment web --replicas=10
6.10 一次任务和定时任务
6.10.1 一次任务
下面演示的是一个计算pi的任务
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4
启动任务
kubectl create -f job.yaml
查看任务
kubectl get jobs
查看日志得到结果
kubectl logs pi-qpqff
6.10.2 定时任务
下面演示的是一个定时任务
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
启动任务
kubectl create -f cronjob.yaml
查看日志得到结果
kubectl logs hellp-1599100140-wkn79
7 Service
7.1 Service概述
Service 是Kubernetes 最核心概念,通过创建Service,可以为一组具有相同功能的容器应用提供一个统一的入口地址,并且将请求负载分发到后端的各个容器应用上
- 防止Pod失联(服务发现)
- 定义一组Pod访问策略(负载均衡)
7.2 Pod和Service的关系
我们都知道,不同的Pod他们的Ip是不同的,当Pod如下线重启后,他们的IP也是不同的,那要访问Pod该如何实现呢?这就用到了Service的服务发现功能,当Pod上线后,会在Service中注册自己的Ip地址,他们通过Label和Selector标签建立关联
通过Service实现Pod的负载均衡和服务发现
7.3 常用的Service的类型
- ClusterIP:集群内部使用
- NodePort:对外访问应用
- LoadBalancer:对外访问应用,适用于公有云
通常内网部署Node应用,外网一版不能访问到的,有两种方案
- 找到一台可以进行外网访问的机器,安装Nginx反向代理
- 手动把可以访问节点添加到Nginx里面
而LoadBalancer可以手动指定公有云,自动添加负载均衡,实际上是添加了控制器执行上述操作。
8 配置管理
8.1 Secret
Secret作用是加密数据存在etcd里面,让Pod容器以挂载Volume方式进行访问
Secret 有三种类型
- Service Account :用来访问Kubernetes API,由Kubernetes 自动创建,并且会自动挂载到Pod 的
/run/secrets/kubernetes.io/serviceaccount目录中 - Opaque : base64 编码格式的Secret,用来存储密码、密钥等
- kubernetes.io/dockerconfigjson :用来存储私有docker registry 的认证信息
使用方式如下:
8.1.1 以变量形式
- 创建加密数据
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
password: MWYyZDFlMmU2N2Rm
kubectl apply -f secret.yaml
kubectl get secret
- 以变量形式挂载到Pod容器中
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: nginx
image: nginx
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: mysecret
key: username
- name: SECRET_PASSWORD
valueFrom:
secretKeyRef:
name: mysecret
key: password
- 查看变量中对应的值
kubectl exec -it mypod bash
echo $SECRET_USERNAME
echo $SECRET_PASSWORD
8.1.2 以数据卷方式
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- name: foo
mountPath: "/etc/foo"
readOnly: true
volumes:
- name: foo
secret:
secretName: mysecret
kubectl apply -f secret.yaml
kubectl exec -it mypod bash
ls /etc/foo
username password
cat password
cat username
8.2 ConfigMap
ConfigMap 功能在Kubernetes1.2 版本中引入,许多应用程序会从配置文件、命令行参数或环境变量中读取配置信息。ConfigMap API给我们提供了向容器中注入配置信息的机制,ConfigMap 可以被用来保存单个属性,也可以用来保存整个配置文件或者JSON 二进制大对象
创建configmap
kubectl create configmap redis-config --from-file=redis.properties
查看已有的configmap
kubectl get cm
查看详细信息
kubectl describe cm redis-config
- 挂载到数据卷
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: busybox
image: busybox
command: [ "/bin/sh","-c","cat /etc/config/redis.properties" ]
volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
name: redis-config
restartPolicy: Never
kubectl apply -f cm.yaml
kubectl logs mypod
- 以变量形式进行挂载
apiVersion: v1
kind: ConfigMap
metadata:
name: myconfig
namespace: default
data:
special.level: info
special.type: hello