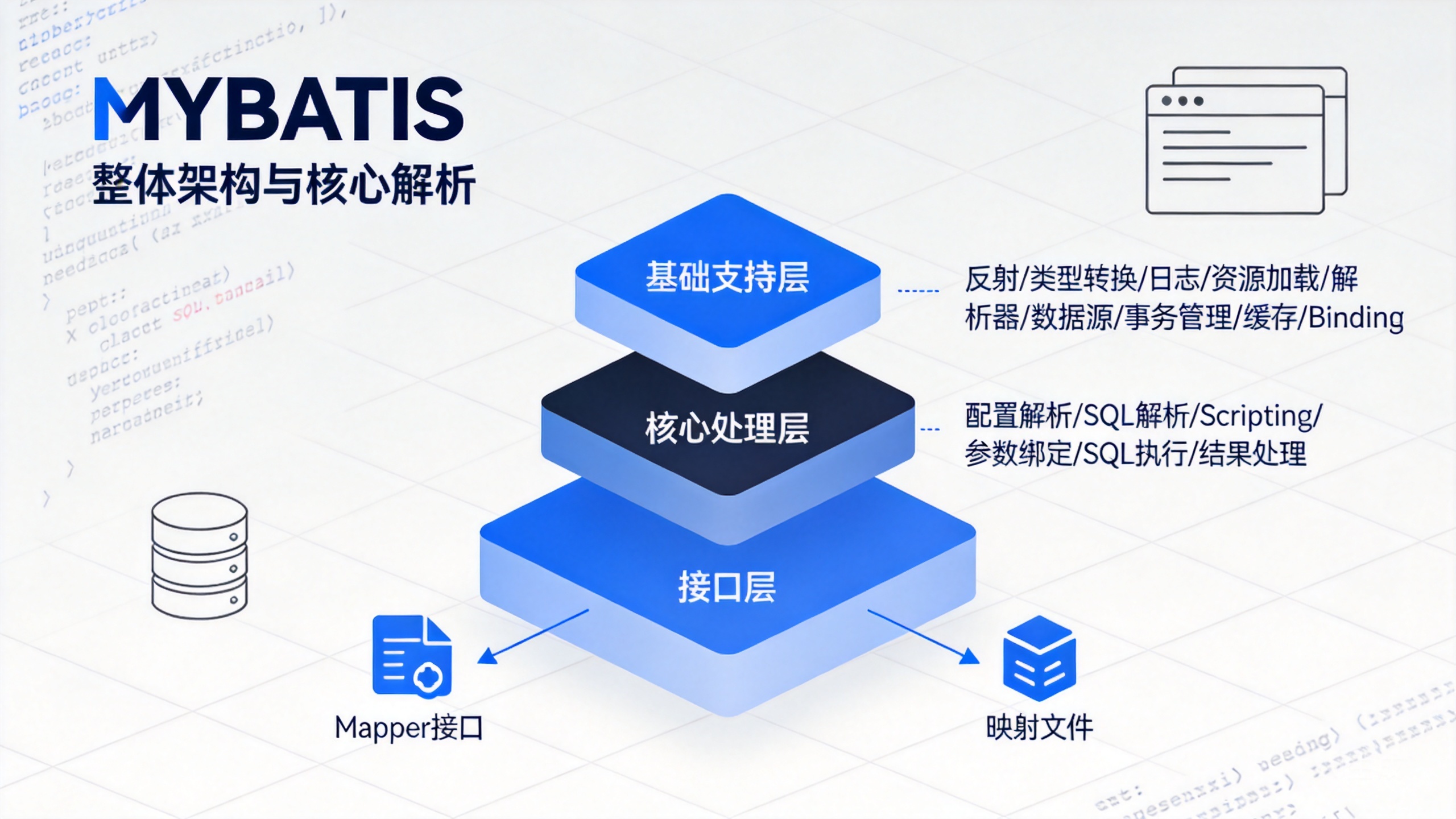

1 Mybatis的整体架构
Mybatis的整体架构分三层,分别是基础支持层,核心处理层和接口层。

1.1 基础支持层
基础支持层包含整个Mybatis的基础模块,这些模块为核心处理层的功能提供了良好支撑,包括
- 反射模块:封装了反射的API
- 类型转换模块:实现JDBC类型与Java类型的转换
- 日志模块:提供日志输出信息、集成第三方框架
- 资源加载模块:对类加载器进行封装,确定类加载器的使用顺序
- 解析器模块:包含XML的解析(XPath)和动态SQL占位符支持
- 数据源模块:提供数据源实现、封装第三方数据源集成的接口
- 事物管理:提供事物相应接口和简单实现
- 缓存模块:提供两级缓存
- Binding模块:将用户自定义Mapper接口与映射文件配置关联
1.2 核心处理层
核心处理层中实现了Mybatis的核心处理流程,包括Mybatis的初始化以及完成一次数据库操作设计的全部流程,包括
- 配置解析:加载
mybatis-config.xml配置文件、映射配置文件以及Mapper接口中的注解信息,解析后的配置信息会形成相应的对象保存到Configuration对象中。 - SQL解析以及Scripting模块:Scripting模块会根据用户传入的实参,解析映射文件中定义的动态SQL节点,并形成数据库可执行的SQL语句,之后会处理SQL语句中的占位符,绑定用户传入的实参
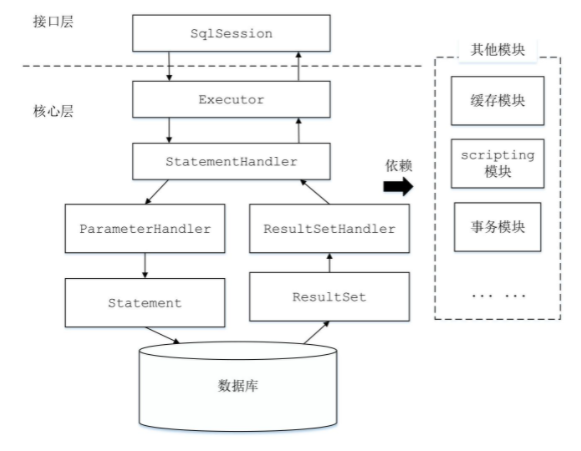
- SQL执行:SQL语句的执行涉及多个组件,其中重要的有
Executor、StatementHandler、ParameterHandler和ResultSetHandler。Executor主要维护一级缓存和二级缓存,并提供事物管理的相关操作,它会将数据库相关操作委托给StatementHandler完成。StatementHandler首先通过ParameterHandler完成SQL语句的实参绑定,然后通过java.sql.Statement对象执行SQL语句并得到结果集,最后通过ResultSetHandler完成结果集的映射。
- 插件:提供用户自定义扩展
1.3 接口层
接口层相对简单,核心是SqlSession接口,该接口中定义了Mybatis暴露给应用调用的API
2 基础支持层
2.1 解析器模块
Mybatis在初始化过过程中处理mybatis-config.xml配置文件以及映射文件时,使用的是DOM解析方式,并结合使用XPath解析XML配置文件。DOM会将整个XML文档加载到内存中并形成树状数据接口。而XPath是一种为查询XML文档而涉及的语言,使用路径表达式来选取XML文档中指定的节点或者节点集合。它可以与DOM解析方式配合使用,实现对XML文档的解析。
public class XPathParser {
private final Document document;
private boolean validation;
private EntityResolver entityResolver; // 用于加载本地DTD文件
private Properties variables; // mybatis-config.xml中<properties>标签定义的键值对集合
private XPath xpath; // XPath对象
}
默认情况下,对XML文档进行验证时,会根据XML文档开始位置的指定网址加载默认的DTD文件或XSD文件。如果解析mybatis-config.xml配置文件,默认加载http://mybatis.org/dtd/mybatis-3-config.dtd。实践中往往提前设置EntityResolver接口对象加载本地的DTD文件。Mybatis提供的EntityResolver默认实现类如下:
public class XMLMapperEntityResolver implements EntityResolver {
// 指定mybatis-config文件和映射文件对应的DTD的systemId
private static final String IBATIS_CONFIG_SYSTEM = "ibatis-3-config.dtd";
private static final String IBATIS_MAPPER_SYSTEM = "ibatis-3-mapper.dtd";
private static final String MYBATIS_CONFIG_SYSTEM = "mybatis-3-config.dtd";
private static final String MYBATIS_MAPPER_SYSTEM = "mybatis-3-mapper.dtd";
// 指定mybatis-config文件和映射文件对应的DTD的具体位置
private static final String MYBATIS_CONFIG_DTD = "org/apache/ibatis/builder/xml/mybatis-3-config.dtd";
private static final String MYBATIS_MAPPER_DTD = "org/apache/ibatis/builder/xml/mybatis-3-mapper.dtd";
@Override
public InputSource resolveEntity(String publicId, String systemId) throws SAXException {
try {
if (systemId != null) {
String lowerCaseSystemId = systemId.toLowerCase(Locale.ENGLISH);
// 查找systemId对应的DTD文档,并读取
if (lowerCaseSystemId.contains(MYBATIS_CONFIG_SYSTEM) || lowerCaseSystemId.contains(IBATIS_CONFIG_SYSTEM)) {
return getInputSource(MYBATIS_CONFIG_DTD, publicId, systemId);
} else if (lowerCaseSystemId.contains(MYBATIS_MAPPER_SYSTEM) || lowerCaseSystemId.contains(IBATIS_MAPPER_SYSTEM)) {
return getInputSource(MYBATIS_MAPPER_DTD, publicId, systemId);
}
}
return null;
} catch (Exception e) {
throw new SAXException(e.toString());
}
}
}
XPathParser封装了Document对象的过程并触发了加载XML文档的过程
// XPathParser的初始化
private void commonConstructor(boolean validation, Properties variables, EntityResolver entityResolver) {
this.validation = validation;
this.entityResolver = entityResolver;
this.variables = variables;
XPathFactory factory = XPathFactory.newInstance();
this.xpath = factory.newXPath();
}
// 创建Document对象
private Document createDocument(InputSource inputSource) {
// important: this must only be called AFTER common constructor
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// ...配置factory,略
DocumentBuilder builder = factory.newDocumentBuilder();
builder.setEntityResolver(entityResolver);
builder.setErrorHandler(new ErrorHandler() {
// 空方法
});
// 加载XML文档
return builder.parse(inputSource);
} catch (Exception e) {
throw new BuilderException("Error creating document instance. Cause: " + e, e);
}
}
XPathParser提供了一系列eval*()用于解析boolean、short等类型的信息,通过XPath.evaluate()方法查找指定路径的节点或属性,并进行相应的类型转换
public String evalString(Object root, String expression) {
String result = (String) evaluate(expression, root, XPathConstants.STRING);
result = PropertyParser.parse(result, variables);
return result;
}
PropertyParser.parse方法中会创建GenericTokenParser解析器,并将默认值处理委托给GenericTokenParser.parse方法。GenericTokenParser解析器是一个通用字占位符解析器,处理方法就是顺序查找openToken和closeToken,解析的带占位符字面值,交给TokenHandler处理,然后将解析结果重新拼接成字符串返回。GenericTokenParser不仅在这里默认值解析用到,还用用于后面对SQL语句的解析。
public class GenericTokenParser {
private final String openToken; // 占位符的开始标记
private final String closeToken; // 占位符的结束标记
private final TokenHandler handler; // TokenHandler实现会按照一定逻辑解析占位符
}
``PropertyParser是通过VariableTokenHandler和GenericTokenParser实现的,VariableTokenHandler实现了TokenHandler接口,该方法首先会安装defaultValueSeparator字段指定的分隔符对整个占位符切分,得到占位符的名称和默认值,然后安装切分的带的占位符名称查找对应的值,如果在`节点下未定义相应的键值对,则将默认值作为解析结果返回
public String handleToken(String content) {
if (variables != null) {
String key = content;
if (enableDefaultValue) {
// 查找分隔符
final int separatorIndex = content.indexOf(defaultValueSeparator);
String defaultValue = null;
if (separatorIndex >= 0) {
// 获取占位符的名称
key = content.substring(0, separatorIndex);
// 获取默认值
defaultValue = content.substring(separatorIndex + defaultValueSeparator.length());
}
if (defaultValue != null) {
// variables集合中查找指定的占位符
return variables.getProperty(key, defaultValue);
}
}
if (variables.containsKey(key)) {
return variables.getProperty(key);
}
}
// variables集合为空
return "${" + content + "}";
}
示例:假如在配置
${username:root},其中:是占位符和默认值的分隔符。PropertyParser会在解析后使用username在集合中查找相应的值,如果查不到,则使用root作为数据库用户名的默认值
2.2 反射工具箱
Mybatis在进行参数处理、结果映射等操作时,会涉及大量的反射操作,Mybatis提供了专门的反射模块,对其进行封装
2.2.1 Reflector&ReflectorFactory
Reflector是Mybatis反射模块的基础,每个Reflector对象都对应一个类,缓存了反射操作需要使用的类的元信息
public class Reflector {
private static final MethodHandle isRecordMethodHandle = getIsRecordMethodHandle();
private final Class<?> type; // 对应的Class类型
private final String[] readablePropertyNames; // 可读属性的名称集合, 即存在getter方法的属性
private final String[] writablePropertyNames; // 可写属性的名称集合, 即存在setter方法的属性
private final Map<String, Invoker> setMethods = new HashMap<>(); // 记录了相应属性的setter方法
private final Map<String, Invoker> getMethods = new HashMap<>(); // 记录了相应属性的getter方法
private final Map<String, Class<?>> setTypes = new HashMap<>(); // 记录了属性相应的setter方法的参数值类型
private final Map<String, Class<?>> getTypes = new HashMap<>(); // 记录了属性相应的getter方法的参数值类型
private Constructor<?> defaultConstructor; // 记录了默认的构造方法
private Map<String, String> caseInsensitivePropertyMap = new HashMap<>(); // 记录了所有属性名称的集合
}
在构造方法中会解析对应的Class对象,并填充上述集合
public Reflector(Class<?> clazz) {
type = clazz; // 初始化type字段
addDefaultConstructor(clazz); // 查找clazz的默认构造方法(无参)
Method[] classMethods = getClassMethods(clazz); // 获得类的所有方法
if (isRecord(type)) {
addRecordGetMethods(classMethods);
} else {
addGetMethods(classMethods); // 处理clazz中的getter方法, 填充getMethods集合和getTypes集合
addSetMethods(classMethods); // 处理clazz中的setter方法, 填充setMethods集合和setTypes集合
addFields(clazz); // 处理没有getter/setter方法的字段
}
// 根据getMethods/setMethods集合, 初始化可读/写的属性的名称集合
readablePropertyNames = getMethods.keySet().toArray(new String[0]);
writablePropertyNames = setMethods.keySet().toArray(new String[0]);
// 初始化caseInsensitivePropertyMap集合, 其中记录了所有大写格式的属性名称
for (String propName : readablePropertyNames) {
caseInsensitivePropertyMap.put(propName.toUpperCase(Locale.ENGLISH), propName);
}
for (String propName : writablePropertyNames) {
caseInsensitivePropertyMap.put(propName.toUpperCase(Locale.ENGLISH), propName);
}
}
获得类的所有方法如下:
private Method[] getClassMethods(Class<?> clazz) {
// 用于记录指定类中定义的全部方法的唯一签名以及对应的Method对象
Map<String, Method> uniqueMethods = new HashMap<>();
Class<?> currentClass = clazz;
while (currentClass != null && currentClass != Object.class) {
// 记录currentClass这个类中定义的全部方法
addUniqueMethods(uniqueMethods, currentClass.getDeclaredMethods());
// we also need to look for interface methods -
// because the class may be abstract
Class<?>[] interfaces = currentClass.getInterfaces();
for (Class<?> anInterface : interfaces) {
addUniqueMethods(uniqueMethods, anInterface.getMethods());
}
currentClass = currentClass.getSuperclass(); // 获取父类, 继续while循环
}
Collection<Method> methods = uniqueMethods.values();
return methods.toArray(new Method[0]); // 转换成Method数组返回
}
其中addUniqueMethods方法会为每个方法生成唯一签名, 并记录到uniqueMethods集合中
private void addUniqueMethods(Map<String, Method> uniqueMethods, Method[] methods) {
for (Method currentMethod : methods) {
if (!currentMethod.isBridge()) {
// 通过getSignature得到方法的签名是: 返回值类型#方法名称:参数列表
// 例如Reflector.getSignature(Method)方法的唯一签名是
// java.lang.String#getSignature:java.lang.reflect.Method
String signature = getSignature(currentMethod);
// check to see if the method is already known
// if it is known, then an extended class must have
// overridden a method
if (!uniqueMethods.containsKey(signature)) {
uniqueMethods.put(signature, currentMethod);
}
}
}
}
回头来看,addGetMethods和addSetMethods都经过两个步骤:
在之前版本, getClassMethods调用是在getClassMethods/setMethods中的,在后面直接提到制造函数了,因此,如果是三个步骤的话,第一个步骤就是getClassMethods。
- 按照JavaBean的规范, 从getClassMethods返回的Method数组中查找该类中定义的getter方法,将其记录到conflictingGetter集合中。
- 当子类覆盖了父类的getter方法并且返回值发生变化时,在getClassMethods中就会产生两个签名不通的方法,所以会调用resolveGetterConflicts方法对覆写的方法进行处理,同时将得到的getter方法记录到getMethods集合,并将其的返回值类型填充到getTypes集合。
private void resolveGetterConflicts(Map<String, List<Method>> conflictingGetters) {
for (Entry<String, List<Method>> entry : conflictingGetters.entrySet()) {
Method winner = null;
String propName = entry.getKey();
boolean isAmbiguous = false;
for (Method candidate : entry.getValue()) {
if (winner == null) {
// 如果没有候选方法, 当前方法直接成为候选方法
winner = candidate;
continue;
}
Class<?> winnerType = winner.getReturnType();
Class<?> candidateType = candidate.getReturnType();
if (candidateType.equals(winnerType)) {
// 返回值相同, 而这种情况应该已经过滤掉了
// 但如果是bool值, 可能存在getXXX 和 isXXX, 这个时候isXXX当选
if (!boolean.class.equals(candidateType)) {
isAmbiguous = true;
break;
}
if (candidate.getName().startsWith("is")) {
winner = candidate;
}
} else if (candidateType.isAssignableFrom(winnerType)) {
// 当前最适合方法的返回值是当前方法返回值的子类, 什么都不做
} else if (winnerType.isAssignableFrom(candidateType)) {
// 当前方法的返回值是当前最适合方法的返回值的之类, 当前的getter方法为最适合的getter方法
winner = candidate;
} else {
isAmbiguous = true;
break;
}
}
addGetMethod(propName, winner, isAmbiguous);
}
}
ReflectorFactory接口主要实现了对Reflector对象的创建和缓存
public interface ReflectorFactory {
boolean isClassCacheEnabled(); // 检测ReflectorFactory对象是否会缓存Reflector对象
void setClassCacheEnabled(boolean classCacheEnabled); // 设置是否缓存Reflector对象
Reflector findForClass(Class<?> type); // 创建指定Class对应的Reflector对象
}
Mybatis提供了DefaultReflectorFactory实现, 它的findForClass方法会为指定的Class创建Reflector对象, 并将Reflector对象缓存到reflectorMap中
public Reflector findForClass(Class<?> type) {
if (classCacheEnabled) {
// synchronized (type) removed see issue #461
return MapUtil.computeIfAbsent(reflectorMap, type, Reflector::new);
}
return new Reflector(type);
}
这里是Mybatis的一个扩展点, 可以实现自定义的ReflectorFactory,配置在mybatis-config.xml中,实现功能上的扩展
2.2.2 TypeParameterResolver
TypeParameterResolver中通过resolveFieldType, resolveReturnType, resolveParamTypes分别解析字段类型、方法返回值类型和方法参数列表中各个参数的类型。这三个方法逻辑基本类似, 以resolveFieldType为例
public static Type resolveFieldType(Field field, Type srcType) {
Type fieldType = field.getGenericType(); // 获取字段的声明类型
Class<?> declaringClass = field.getDeclaringClass(); // 获取字段定义所在的类的Class对象
return resolveType(fieldType, srcType, declaringClass); // 后续处理
}
resolveType方法会根据第一个参数的类型,即字段、方法返回值或方法参数的类型,选择合适的方法进行解析。第二个参数表示查找该字段、返回值或方法参数的起始位置。第三个参数表示该方法、定义所在的类型。
private static Type resolveType(Type type, Type srcType, Class<?> declaringClass) {
if (type instanceof TypeVariable) { // 解析TypeVariable类型
return resolveTypeVar((TypeVariable<?>) type, srcType, declaringClass);
}
if (type instanceof ParameterizedType pt) { // 解析ParameterizedType类型
return resolveParameterizedType(pt, srcType, declaringClass);
} else if (type instanceof GenericArrayType gt) { // 解析GenericArrayType类型
return resolveGenericArrayType(gt, srcType, declaringClass);
} else {
return type; // Class类型
}
}
2.2.3 ObjectFactory
Mybatis中很多模块都会用到ObjectFactory,该接口提供了多个create()方法的重载,通过这些方法可以创建指定类型的对象。
public interface ObjectFactory
default void setProperties(Properties properties) { // 设定配置信息
// NOP
}
<T> T create(Class<T> type); // 通过无参构造器创建指定类的对象
// 根据参数列表, 从指定类型中选择合适的构造器创建对象
<T> T create(Class<T> type, List<Class<?>> constructorArgTypes, List<Object> constructorArgs);
// 检测指定类型是否为集合类型(Collection类型)
<T> boolean isCollection(Class<T> type);
}
这里是Mybatis的一个扩展点, 可以实现自定义的ObjectFactory,配置在mybatis-config.xml中,实现功能上的扩展
2.2.4 Property工具集
反射模块中用到的三个属性工具类: PropertyTokenizer、PropertyNamer、PropertyCopier
PropertyTokenizer会对传入的表达式进行分析,并初始化字段,PropertyTokenizer继承了Iterator接口,它可以迭代处理多层表达式。next方法会创建新的PropertyTokenizer对象并解析children字段记录的子表达式。
public class PropertyTokenizer implements Iterator<PropertyTokenizer> {
private String name; // 当前表达式的名称
private final String indexedName; // 当前表达式的索引名
private String index; // 索引下标
private final String children; // 子表达式
public PropertyTokenizer(String fullname) {
int delim = fullname.indexOf('.');
if (delim > -1) {
name = fullname.substring(0, delim);
children = fullname.substring(delim + 1);
} else {
name = fullname;
children = null;
}
indexedName = name;
delim = name.indexOf('[');
if (delim > -1) {
index = name.substring(delim + 1, name.length() - 1);
name = name.substring(0, delim);
}
}
@Override
public boolean hasNext() {
return children != null;
}
@Override
public PropertyTokenizer next() {
return new PropertyTokenizer(children);
}
}
PropertyNamer提供了下列方法帮助方法名到属性名的转换,以及多种检测操作
public final class PropertyNamer {
// 将方法名转换为属性名
public static String methodToProperty(String name) {
// 简单说就是将is、get、set截掉,并将首字母小写
}
// 方法名是否对应属性名
public static boolean isProperty(String name) {
// 简单说就是方法名是否以is、get、set开头
}
public static boolean isGetter(String name) {
return name.startsWith("get") && name.length() > 3 || name.startsWith("is") && name.length() > 2;
}
public static boolean isSetter(String name) {
return name.startsWith("set") && name.length() > 3;
}
}
PropertyCopier是一个属性拷贝的工具类,核心方法是copyBeanProperties,实现两个对象之间的属性值拷贝
public static void copyBeanProperties(Class<?> type, Object sourceBean, Object destinationBean) {
Class<?> parent = type;
while (parent != null) {
final Field[] fields = parent.getDeclaredFields();
for (Field field : fields) {
try {
try {
field.set(destinationBean, field.get(sourceBean));
} catch (IllegalAccessException e) {
if (!Reflector.canControlMemberAccessible()) {
throw e;
}
field.setAccessible(true);
field.set(destinationBean, field.get(sourceBean));
}
} catch (Exception e) {
// Nothing useful to do, will only fail on final fields, which will be ignored.
}
}
// 继续拷贝父类定义的字段
parent = parent.getSuperclass();
}
}
2.2.5 MetaClass
MetaClass通过Reflector和PropertyTokenizer组合使用,实现了对复杂属性表达式的解析,并实现了获取指定属性描述信息的功能
MetaClass中比较重要的是findProperty方法,它是通过buildProperty方法实现的,而buildProperty方法会通过PropertyTokenizer解析复杂属性表达式
private StringBuilder buildProperty(String name, StringBuilder builder) {
PropertyTokenizer prop = new PropertyTokenizer(name);
if (prop.hasNext()) { // 是否还有子表达式
// 查找PropertyTokenizer.name对应的属性
String propertyName = reflector.findPropertyName(prop.getName());
if (propertyName != null) {
builder.append(propertyName); // 追加属性名
builder.append(".");
// 创建对应的MetaClass对象
MetaClass metaProp = metaClassForProperty(propertyName);
// 递归解析PropertyTokenizer的children字段, 并将解析结果保存到builder中
metaProp.buildProperty(prop.getChildren(), builder);
}
} else { // 递归出口
String propertyName = reflector.findPropertyName(name);
if (propertyName != null) {
builder.append(propertyName);
}
}
return builder;
}
2.2.6 ObjectWrapper
MetaClass是Mybatis对类级别元信息的封装和处理,对对象级别的元信息处理使用ObjectWrapper。ObjectWrapper接口是对对象的包装,抽象了对象的属性信息,它定义了一系列查询对象属性信息的方法,以及更新属性的方法
public interface ObjectWrapper {
// 如果ObjectWrapper中封装是普通Bean对象, 则调用相应属性的getter方法
// 如果封装的是集合类, 则获取指定key下标对应的value值
Object get(PropertyTokenizer prop);
// 如果ObjectWrapper中封装是普通Bean对象, 则调用相应属性的setter方法
// 如果封装的是集合类, 则设置指定key下标对应的value值
void set(PropertyTokenizer prop, Object value);
// 查找属性表达式指定的属性, 第二个参数表示是否忽略属性表达式中的下划线
String findProperty(String name, boolean useCamelCaseMapping);
// 查找可写的属性名称集合
String[] getGetterNames();
// 查找可读属性的名称集合
String[] getSetterNames();
// 解析属性表达式指定属性的setter/getter参数类型
Class<?> getSetterType(String name);
Class<?> getGetterType(String name);
// 判断属性表达式指定属性是否有getter/setter方法
boolean hasSetter(String name);
boolean hasGetter(String name);
// 为属性表示指定的属性创建相应的MetaObject对象
MetaObject instantiatePropertyValue(String name, PropertyTokenizer prop, ObjectFactory objectFactory);
// 封装的对象是否为Collection类型
boolean isCollection();
// 调用Collection类型的add方法
void add(Object element);
// 调用Collection类型的addAll方法
<E> void addAll(List<E> element);
}
而ObjectWrapperFactory负责创建ObjectWrapper对象,它的实现类是DefaultObjectWrapperFactory,但它实现的hasWrapperFor始终返回false,getWrapperFor抛出异常,因此实际上是不可用的,我们可以自定义ObjectWrapperFactory,作为一个扩展点。
2.2.7 MetaObject
ObjectWrapper提供了获取/设置对象中指定的属性值,检测getter/setter等常用功能,而MetaObject,就负责属性表示的解析。
MetaObject的构造方法会根据传入的原始对象的类型以及ObjectFactory工厂的实现,创建对应的ObjectWrapper对象
private MetaObject(Object object, ObjectFactory objectFactory, ObjectWrapperFactory objectWrapperFactory,
ReflectorFactory reflectorFactory) {
// 初始化上述字段
this.originalObject = object;
this.objectFactory = objectFactory;
this.objectWrapperFactory = objectWrapperFactory;
this.reflectorFactory = reflectorFactory;
if (object instanceof ObjectWrapper) { // 若已经是ObjectWrapper对象,直接使用
this.objectWrapper = (ObjectWrapper) object;
} else if (objectWrapperFactory.hasWrapperFor(object)) {
// 若ObjectWrapperFactory能够为该原始对象创建对应的ObjectWrapper对象,则优先使用ObjectWrapperFactory
// 而DefaultObjectWrapperFactory始终为null, 所以这块其实是用户自定义的扩展点
this.objectWrapper = objectWrapperFactory.getWrapperFor(this, object);
} else if (object instanceof Map) {
// 若原始对象为Map类型,则创建MapWrapper对象
this.objectWrapper = new MapWrapper(this, (Map) object);
} else if (object instanceof Collection) {
// 若原始对象为Collection类型,则创建CollectionWrapper对象
this.objectWrapper = new CollectionWrapper(this, (Collection) object);
} else {
// 若原始对象为普通的JavaBean类型,则创建BeanWrapper对象
this.objectWrapper = new BeanWrapper(this, object);
}
}
// 由于构造参数是私有化的,因此只能通过这个方法创建MetaObject对象
public static MetaObject forObject(Object object, ObjectFactory objectFactory,
ObjectWrapperFactory objectWrapperFactory, ReflectorFactory reflectorFactory) {
if (object == null) {
return SystemMetaObject.NULL_META_OBJECT;
}
return new MetaObject(object, objectFactory, objectWrapperFactory, reflectorFactory);
}
2.3 类型转换
JDBC数据类型与Java语言中的数据类型并不是完全对应的,所以在PreparedStatement为SQL语句绑定参数时,需要从Java类型转换成JDBC类型,而从结果集中获取数据时,则需要从JDBC类型转换成Java类型。MyBatis使用类型处理器完成上述两种转换。
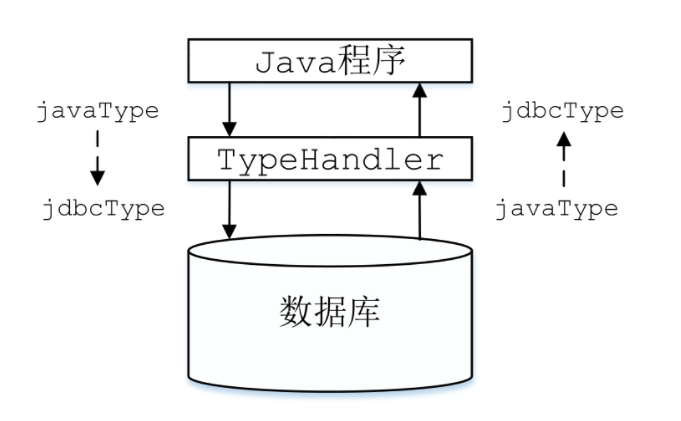
2.3.1 TypeHandler
MyBatis中所有的类型转换器都继承了TypeHandler接口
public interface TypeHandler<T> {
/**
* setParameter方法负责将数据由JdbcType类型转换为Java类型
*/
void setParameter(PreparedStatement ps, int i, T parameter, JdbcType jdbcType) throws SQLException;
/**
* getResult方法负责将数据由Java类型转换为JdbcType类型
*/
T getResult(ResultSet rs, String columnName) throws SQLException;
T getResult(ResultSet rs, int columnIndex) throws SQLException;
T getResult(CallableStatement cs, int columnIndex) throws SQLException;
}
为方便用户自定义TypeHandler实现,MyBatis提供了BaseTypeHandler这个抽象类,它实现了TypeHandler接口,并继承了TypeReference抽象类。在BaseTypeHandler中setParameter方法和getResult方法对于非空数据的处理都交给了子类实现。
public abstract class BaseTypeHandler<T> extends TypeReference<T> implements TypeHandler<T> {
@Override
public void setParameter(PreparedStatement ps, int i, T parameter, JdbcType jdbcType) throws SQLException {
if (parameter == null) {
if (jdbcType == null) {
throw new TypeException("......");
}
try {
ps.setNull(i, jdbcType.TYPE_CODE); // 绑定参数为null的处理
} catch (SQLException e) {
throw new TypeException("...");
}
} else {
try {
// 绑定非空参数, 该方法为抽象方法, 由子类实现
setNonNullParameter(ps, i, parameter, jdbcType);
} catch (Exception e) {
throw new TypeException("...");
}
}
}
@Override
public T getResult(ResultSet rs, String columnName) throws SQLException {
try {
return getNullableResult(rs, columnName);
} catch (Exception e) {
throw new ResultMapException("...");
}
}
public abstract T getNullableResult(ResultSet rs, String columnName) throws SQLException;
public abstract T getNullableResult(ResultSet rs, int columnIndex) throws SQLException;
public abstract T getNullableResult(CallableStatement cs, int columnIndex) throws SQLException;
}
BaseTypeHandler的实现比较多,但大多是直接调用PreparedStatement和ResultSet或者CallableStatement的对应方法,实现较为简单。
一般情况下,TypeHandler用于完成单个参数以及单个列值的类型转换,如果存在多列值转换成一个Java对象的需求,应该优先考虑使用在映射文件中定义合适的映射规则(resultMap节点)完成映射。
2.3.2 TypeHandlerRegistry
在MyBatis初始化过程中,会为所有已知的TypeHandler创建对象,并实现注册到TypeHandlerRegistry中,由TypeHandlerRegistry负责管理这些TypeHandler对象。
public final class TypeHandlerRegistry {
// 记录JDBCType和TypeHandler之间的对应关系, 其中JdbcType是一个枚举类型
// 该集合主要用于从结果集读取数据时, 将数据从Jdbc类型转换成Java类型
private final Map<JdbcType, TypeHandler<?>> jdbcTypeHandlerMap = new EnumMap<>(JdbcType.class);
// 记录了Java类型单向指定JdbcType转换时,需要使用的TypeHandler对象
// 例如String可以转换为varchar、char等多种类型,所以存在一对多关系
private final Map<Type, Map<JdbcType, TypeHandler<?>>> typeHandlerMap = new ConcurrentHashMap<>();
// 记录了全部TypeHandler类型以及该类型相应的TypeHandler对象
private final Map<Class<?>, TypeHandler<?>> allTypeHandlersMap = new HashMap<>();
// 空TypeHandler集合的标识
private static final Map<JdbcType, TypeHandler<?>> NULL_TYPE_HANDLER_MAP = Collections.emptyMap();
}
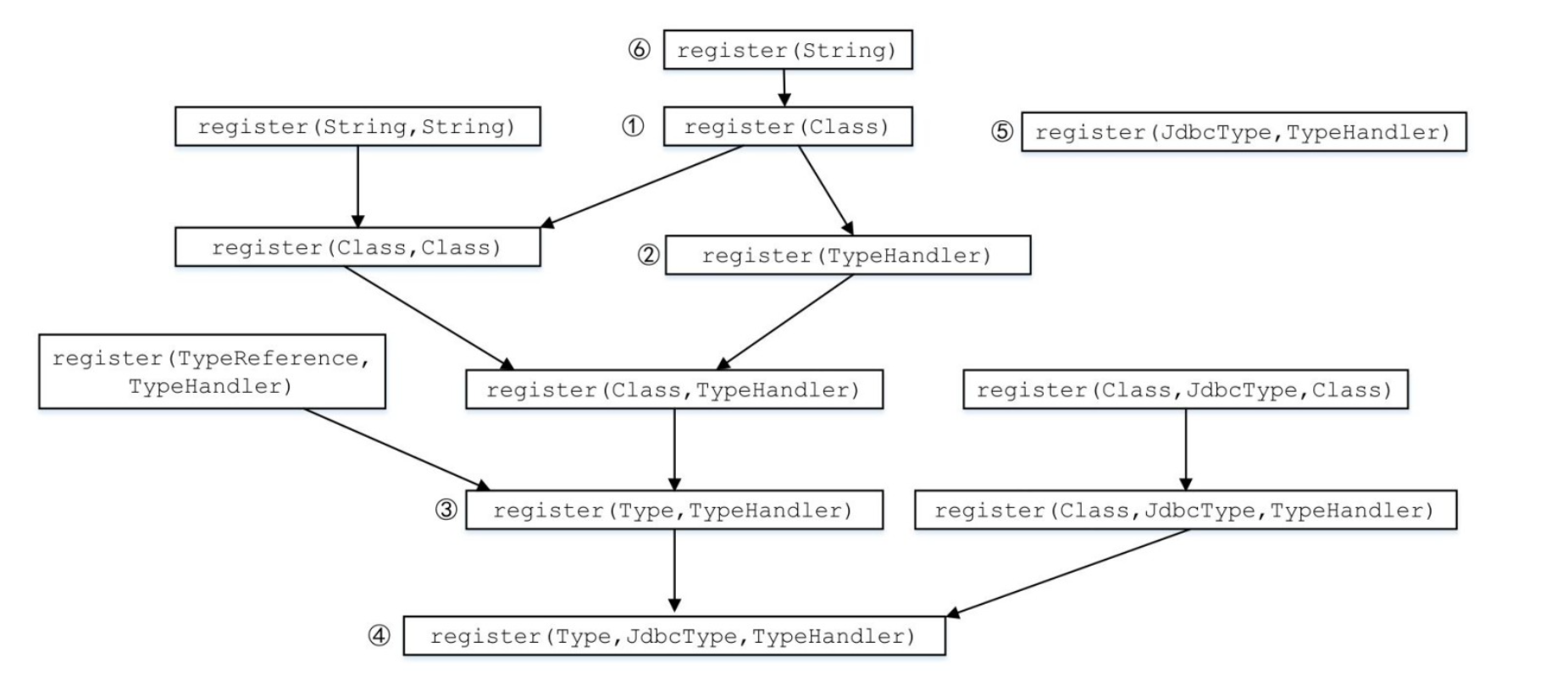
2.3.2.1 注册TypeHandler对象
TypeHandler的registry方法实现了注册TypeHandler对象的功能,该注册过程会向上述四个集合添加TypeHandler对象
// 方法④的重载
private void register(Type javaType, JdbcType jdbcType, TypeHandler<?> handler) {
if (javaType != null) { // 检测是否明确指定了TypeHandler能够处理的Java类型
// 获取指定Java类型再typeHandlerMap中对应的TypeHandler集合
Map<JdbcType, TypeHandler<?>> map = typeHandlerMap.get(javaType);
if (map == null || map == NULL_TYPE_HANDLER_MAP) { // 创建新的集合,并添加到typeHandlerMap中
map = new HashMap<>();
}
map.put(jdbcType, handler);
typeHandlerMap.put(javaType, map);
}
// allTypeHandlersMap中添加TypeHandler类型和对应的TypeHandler对象
allTypeHandlersMap.put(handler.getClass(), handler);
}
在①~③这个三个register方法重载中会尝试读取TypeHandler类中定义的@MappedTypes注解和@MappedJdbcTypes注解,@MappedTypes注解用于指明该TypeHandler实现类能够处理的Java类型的集合,@MappedJdbcTypes注解用于指明该TypeHandler实现类能够处理的JDBC类型集合
// 方法①的重载
public void register(Class<?> typeHandlerClass) {
boolean mappedTypeFound = false;
// 获取MappedTypes注解
MappedTypes mappedTypes = typeHandlerClass.getAnnotation(MappedTypes.class);
if (mappedTypes != null) {
// 根据MappedTypes注解中指定的Java类型进行注册
for (Class<?> javaTypeClass : mappedTypes.value()) {
// 经由强制类型转换以及反射创建TypeHandler对象后,交由③进行处理
register(javaTypeClass, typeHandlerClass);
mappedTypeFound = true;
}
}
if (!mappedTypeFound) {
// 未指定MappedTypes注解,由②处理
register(getInstance(null, typeHandlerClass));
}
}
// 方法②的重载
public <T> void register(TypeHandler<T> typeHandler) {
boolean mappedTypeFound = false;
// 获取MappedTypes注解,逻辑与①类似
MappedTypes注解, mappedTypes = typeHandler.getClass().getAnnotation(MappedTypes.class);
if (mappedTypes != null) {
for (Class<?> handledType : mappedTypes.value()) {
register(handledType, typeHandler);
mappedTypeFound = true;
}
}
// 从3.1.0开始,如果typeHandler同时继承了TypeReference
// 就可以根据TypeHandler的类型自动查找对应的Java类型
if (!mappedTypeFound && typeHandler instanceof TypeReference) {
try {
TypeReference<T> typeReference = (TypeReference<T>) typeHandler;
// 由③处理
register(typeReference.getRawType(), typeHandler);
mappedTypeFound = true;
} catch (Throwable t) {
// maybe users define the TypeReference with a different type and are not assignable, so just ignore it
}
}
if (!mappedTypeFound) {
// 转换类型后 交由③处理
register((Class<T>) null, typeHandler);
}
}
// 方法③的重载
private <T> void register(Type javaType, TypeHandler<? extends T> typeHandler) {
// 获取MappedTypes注解
MappedJdbcTypes mappedJdbcTypes = typeHandler.getClass().getAnnotation(MappedJdbcTypes.class);
if (mappedJdbcTypes != null) {
// 根据MappedTypes注解指定的类型进行注册
for (JdbcType handledJdbcType : mappedJdbcTypes.value()) {
// 由④进行注册
register(javaType, handledJdbcType, typeHandler);
}
if (mappedJdbcTypes.includeNullJdbcType()) {
// 由④进行注册
register(javaType, null, typeHandler);
}
} else {
// 由④进行注册
register(javaType, null, typeHandler);
}
}
上述全部的register方法重载都是在向typeHandlerMap集合和allTypeHandlersMap集合注册TypeHandler对象而⑤就是向jdbcTypeHandlerMap集合注册
// 方法⑤的重载
public void register(JdbcType jdbcType, TypeHandler<?> handler) {
jdbcTypeHandlerMap.put(jdbcType, handler);
}
TypeHandlerRegistry除了提供注册单个TypeHandler的register()重载,还可以扫描整个包下的TypeHandler接口实现类,并将完成这些TypeHandler实现类的注册
public void register(String packageName) {
ResolverUtil<Class<?>> resolverUtil = new ResolverUtil<>();
// 查找指定包下的TypeHandler接口实现类
resolverUtil.find(new ResolverUtil.IsA(TypeHandler.class), packageName);
Set<Class<? extends Class<?>>> handlerSet = resolverUtil.getClasses();
for (Class<?> type : handlerSet) {
// 过滤掉内部类、接口以及抽象类
if (!type.isAnonymousClass() && !type.isInterface() &&
!Modifier.isAbstract(type.getModifiers())) {
// 交由①进行注册操作
register(type);
}
}
}
TypeHandlerRegistry的构造方法会注册基础类型对象
public TypeHandlerRegistry(Configuration configuration) {
this.unknownTypeHandler = new UnknownTypeHandler(configuration);
register(Boolean.class, new BooleanTypeHandler());
register(boolean.class, new BooleanTypeHandler());
......
}
2.3.2.2 查找TypeHandler
TypeHandlerRegistry.getTypeHandler方法实现了从上述四个集合中获取对应TypeHandler对象的功能
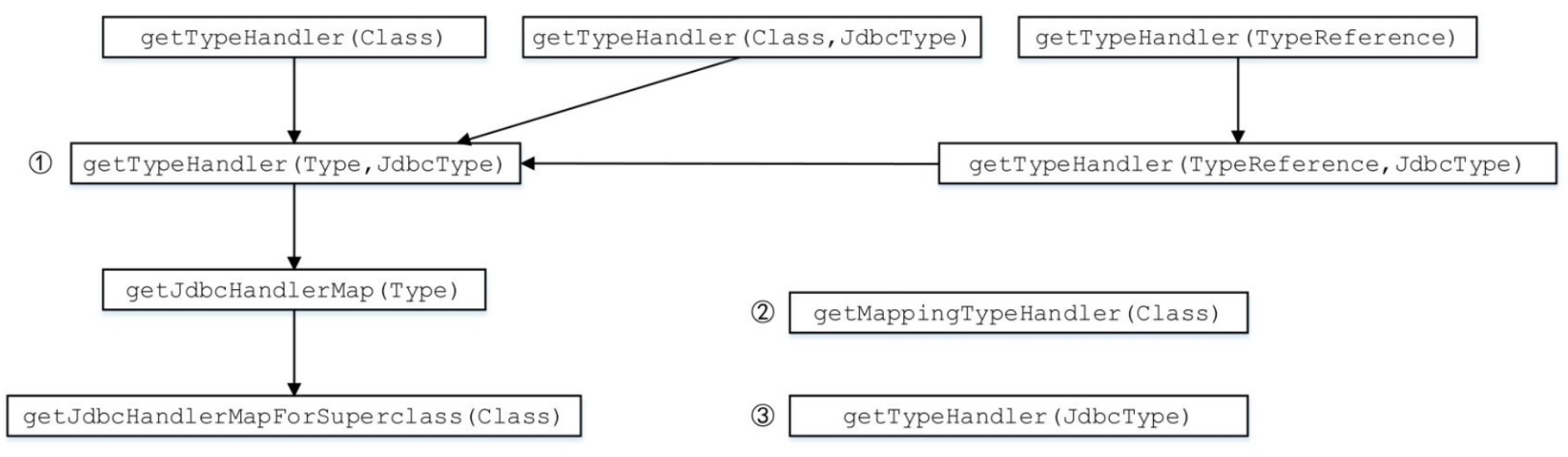
经过一系列类型转换之后,TypeHandlerRegistry.getTypeHandler方法的多个重载都会调用①这个重载方法,它会根据指定的Java类型和JdbcType类型查找相应的TypeHandler对象
private <T> TypeHandler<T> getTypeHandler(Type type, JdbcType jdbcType) {
if (ParamMap.class.equals(type)) {
return null;
}
// 查找(或初始化)Java类型对应的TypeHandler集合
Map<JdbcType, TypeHandler<?>> jdbcHandlerMap = getJdbcHandlerMap(type);
TypeHandler<?> handler = null;
if (jdbcHandlerMap != null) {
// 根据jdbcType查找TypeHandler对象
handler = jdbcHandlerMap.get(jdbcType查找);
if (handler == null) {
handler = jdbcHandlerMap.get(null);
}
if (handler == null) {
// 如果jdbcHandlerMap只注册了一个TypeHandler,就用这个对象
handler = pickSoleHandler(jdbcHandlerMap);
}
}
// type drives generics here
return (TypeHandler<T>) handler;
}
在TypeHandlerRegistry.getJdbcHandlerMap方法中,会检测typeHandlerMap集合中指定Java类型对应的TypeHandler集合是否已经初始化。如果未初始化,则尝试以该Java类型的、已初始化的父类对应的TypeHandler集合为初始集合;如不存在已初始化的父类,则将其对应的TypeHandler集合初始化为NULL_TYPE_HANDLER_MAP标识
private Map<JdbcType, TypeHandler<?>> getJdbcHandlerMap(Type type) {
// 查找Java类型对应的TypeHandler集合
Map<JdbcType, TypeHandler<?>> jdbcHandlerMap = typeHandlerMap.get(type);
if (jdbcHandlerMap != null) {
// 检测是否为空集合标识
return NULL_TYPE_HANDLER_MAP.equals(jdbcHandlerMap) ? null : jdbcHandlerMap;
}
// 初始化指定Java类型对应的TypeHandler集合
if (type instanceof Class) {
Class<?> clazz = (Class<?>) type;
if (Enum.class.isAssignableFrom(clazz)) {
if (clazz.isAnonymousClass()) {
return getJdbcHandlerMap(clazz.getSuperclass());
}
jdbcHandlerMap = getJdbcHandlerMapForEnumInterfaces(clazz, clazz);
if (jdbcHandlerMap == null) {
register(clazz, getInstance(clazz, defaultEnumTypeHandler));
return typeHandlerMap.get(clazz);
}
} else {
// 查找父类对应的TypeHandler集合,并作为初始集合
jdbcHandlerMap = getJdbcHandlerMapForSuperclass(clazz);
}
}
typeHandlerMap.put(type, jdbcHandlerMap == null ? NULL_TYPE_HANDLER_MAP : jdbcHandlerMap);
return jdbcHandlerMap;
}
除了MyBatis本身提供的TypeHandler实现,我们也可以添加自定义的TypeHandler接口实现,添加方式是在mybatis-config.xml配置文件中的typeHandlers节点下,添加相应的typeHandler节点配置,并指定自定义的TypeHandler接口实现类。在MyBatis初始化时会解析该节点,并将该TypeHandler类型的对象注册到TypeHandlerRegistry中,供MyBatis后续使用。
2.3.3 TypeAliasRegistry
在编写SQL语句时,使用别名可以方便理解以及维护,例如表名或列名很长时,我们一般会为其设计易懂易维护的别名。MyBatis将SQL语句中别名的概念进行了延伸和扩展,MyBatis可以为一个类添加一个别名,之后就可以通过别名引用该类。
MyBatis通过TypeAliasRegistry类完成别名注册和管理的功能,TypeAliasRegistry的结构比较简单,它通过TYPE_ALIASES字段管理别名与Java类型之间的对应关系,通过TypeAliasRegistry.registerAlias方法完成注册别名
public class TypeAliasRegistry {
private final Map<String, Class<?>> typeAliases = new HashMap<>();
public void registerAlias(String alias, Class<?> value) {
if (alias == null) { // 别名是空
throw new TypeException("...");
}
String key = alias.toLowerCase(Locale.ENGLISH);
if (typeAliases.containsKey(key) && typeAliases.get(key) != null
&& !typeAliases.get(key).equals(value)) { // 别名已经存在
throw new TypeException("...");
}
// 注册别名
typeAliases.put(key, value);
}
}
在TypeAliasRegistry的构造方法中,默认为Java的基本类型及其数组类型、基本类型的封装类及其数组类型、Date、BigDecimal、BigInteger、Map、HashMap、List、ArrayList、Collection、Iterator、ResultSet等类型添加了别名,registerAliases(String, Class)重载会扫描指定包下所有的类,并为指定类的子类添加别名;registerAlias(Class)重载中会尝试读取@Alias注解
2.4 日志模块
在Java开发中常用的日志框架有Log4j、Log4j2、Apache Commons Log、java.util.logging、slf4j等,这些工具对外的接口不尽相同。为了统一这些工具的接口,MyBatis定义了一套统一的日志接口供上层使用,并为上述常用的日志框架提供了相应的适配器。
2.4.1 日志适配器
前面描述的多种第三方日志组件都有各自的Log级别,且都有所不同,例如java.util.logging提供了All、FINEST、FINER、FINE、CONFIG、INFO、WARNING等9种级别,而Log4j2则只有trace、debug、info、warn、error、fatal这6种日志级别。MyBatis统一提供了trace、debug、warn、error四个级别,这基本与主流日志框架的日志级别类似,可以满足绝大多数场景的日志需求。
MyBatis的日志模块位于org.apache.ibatis.logging包中,该模块中通过Log接口定义了日志模块的功能,当然日志适配器也会实现此接口。LogFactory工厂类负责创建对应的日志组件适配器。在LogFactory类加载时会执行其静态代码块,其逻辑是按序加载并实例化对应日志组件的适配器,然后使用LogFactory.logConstructor这个静态字段,记录当前使用的第三方日志组件的适配器
public final class LogFactory {
// 记录当前使用的第三方日志组件所对应的适配器的构造方法
private static Constructor<? extends Log> logConstructor;
static {
// 针对每种日志组件调用tryImplementation方法进行尝试加载
tryImplementation(LogFactory::useSlf4jLogging);
tryImplementation(LogFactory::useCommonsLogging);
tryImplementation(LogFactory::useLog4J2Logging);
tryImplementation(LogFactory::useLog4JLogging);
tryImplementation(LogFactory::useJdkLogging);
tryImplementation(LogFactory::useNoLogging);
}
}
tryImplementation方法首先会检测logConstructor字段,若为空则调用Runnable.run方法,其中会调用use*Logging()方法。这里以useJdkLogging ()为例
public static synchronized void useJdkLogging() {
setImplementation(org.apache.ibatis.logging.jdk14.Jdk14LoggingImpl.class);
}
private static void setImplementation(Class<? extends Log> implClass) {
try {
// 获取指定适配器的构造方法
Constructor<? extends Log> candidate = implClass.getConstructor(String.class);
Log log = candidate.newInstance(LogFactory.class.getName());
// 初始化logConstructor字段
logConstructor = candidate;
} catch (Throwable t) {
throw new LogException("Error setting Log implementation. Cause: " + t, t);
}
}
public class Jdk14LoggingImpl implements Log {
private final Logger log; // 底层封装的Logger对象
public Jdk14LoggingImpl(String clazz) {
log = Logger.getLogger(clazz); // 初始化Logger对象
}
@Override
public void error(String s) {
log.log(Level.SEVERE, s); // 委托给Logger对象
}
......
}
2.4.2 JDBC调试
在MyBatis的日志模块中有一个Jdbc包,它并不是将日志信息通过JDBC保存到数据库中,而是通过JDK动态代理的方式,将JDBC操作通过指定的日志框架打印出来。这个功能通常在开发阶段使用,它可以输出SQL语句、用户传入的绑定参数、SQL语句影响行数等等信息,对调试程序来说是非常重要的。
BaseJdbcLogger是一个抽象类,它是Jdbc包下其他Logger类的父类

在BaseJdbcLogger中定义了SET_METHODS和EXECUTE_METHODS两个Set类型的集合,用于记录绑定SQL参数相关的set*方法名称以及执行SQL语句相关的方法名称
public abstract class BaseJdbcLogger {
// 记录了PreparedStatement接口中定义的常用的set*方法
protected static final Set<String> SET_METHODS;
// 记录了Statement接口和PreparedStatement接口中执行SQL语句相关的方法
protected static final Set<String> EXECUTE_METHODS = new HashSet<>();
// 记录了PreparedStatement的set*方法设置的键值对
private final Map<Object, Object> columnMap = new HashMap<>();
// 记录了PreparedStatement的set*方法设置的key值
private final List<Object> columnNames = new ArrayList<>();
// 记录了PreparedStatement的set*方法设置的value值
private final List<Object> columnValues = new ArrayList<>();
// 用于输出日志的Log对象
protected final Log statementLog;
// 记录了SQL的层数,用于格式化输出SQL
protected final int queryStack;
static {
SET_METHODS = Arrays.stream(PreparedStatement.class.getDeclaredMethods())
.filter(method -> method.getName().startsWith("set"))
.filter(method -> method.getParameterCount() > 1)
.map(Method::getName)
.collect(Collectors.toSet());
EXECUTE_METHODS.add("execute");
EXECUTE_METHODS.add("executeUpdate");
EXECUTE_METHODS.add("executeQuery");
EXECUTE_METHODS.add("addBatch");
}
}
ConnectionLogger继承了BaseJdbcLogger抽象类,其中封装了Connection对象并同时实现了InvocationHandler接口。ConnectionLogger.newInstance方法为会为其封装的Connection对象创建相应的代理对象,invoke方法是代理对象的核心方法,它为prepareStatement、prepareCall、createStatement等方法提供了代理
public final class ConnectionLogger extends BaseJdbcLogger implements InvocationHandler {
public static Connection newInstance(Connection conn, Log statementLog, int queryStack) {
// 使用JDK动态代理的方法创建代理对象
InvocationHandler handler = new ConnectionLogger(conn, statementLog, queryStack);
ClassLoader cl = Connection.class.getClassLoader();
return (Connection) Proxy.newProxyInstance(cl, new Class[] { Connection.class }, handler);
}
@Override
public Object invoke(Object proxy, Method method, Object[] params) throws Throwable {
try {
// 如果是从Object继承的方法,则直接调用,不做其他任何处理
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, params);
}
// 如果调用的是prepareStatement、prepareCall或createStatement
// 则再创建相应Statement对象后,为其创建代理对象并返回该代理对象
if ("prepareStatement".equals(method.getName()) || "prepareCall".equals(method.getName())) {
if (isDebugEnabled()) {
debug(" Preparing: " + removeExtraWhitespace((String) params[0]), true);
}
PreparedStatement stmt = (PreparedStatement) method.invoke(connection, params);
return PreparedStatementLogger.newInstance(stmt, statementLog, queryStack);
}
if ("createStatement".equals(method.getName())) {
Statement stmt = (Statement) method.invoke(connection, params);
return StatementLogger.newInstance(stmt, statementLog, queryStack);
}
// 其他方法则直接调用底层Connection对象的相应方法
return method.invoke(connection, params);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
}
ResultSetLogger中封装了ResultSet对象,也继承了BaseJdbcLogger抽象类并实现了InvocationHandler接口。
public final class ResultSetLogger extends BaseJdbcLogger implements InvocationHandler {
// 记录了超大长度的类型
private static final Set<Integer> BLOB_TYPES = new HashSet<>();
// 是否是ResultSet结果集的第一行
private boolean first = true;
// 统计行数
private int rows;
// 真正的ResultSet对象
private final ResultSet rs;
// 记录了超大字段的列编号
private final Set<Integer> blobColumns = new HashSet<>();
@Override
public Object invoke(Object proxy, Method method, Object[] params) throws Throwable {
try {
// 如果是从Object继承的方法,则直接调用,不做其他任何处理
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, params);
}
Object o = method.invoke(rs, params);
// 针对ResultSet.next方法的处理
if ("next".equals(method.getName())) {
if ((Boolean) o) { // 是否还存在下一行数据
rows++;
if (isTraceEnabled()) {
ResultSetMetaData rsmd = rs.getMetaData();
final int columnCount = rsmd.getColumnCount(); // 获取结果集的列数
if (first) { // 如果是第一行数据,则输出表头
first = false;
// 除了输出表头还会记录超大字段的列
printColumnHeaders(rsmd, columnCount);
}
// 输出该行记录,会过滤掉blobColumns中记录的列,这些列数据较大,不会输出到日志
printColumnValues(columnCount);
}
} else {
// 遍历完ResultSet后,会输出总行数
debug(" Total: " + rows, false);
}
}
// 情况BaseJdbcLogger中的column*集合
clearColumnInfo();
return o;
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
}
2.5 资源加载
在MyBatis的IO包中封装了ClassLoader以及读取资源文件的相关API
2.5.1 ClassLoaderWrapper
在IO包中提供的ClassLoaderWrapper是一个ClassLoader的包装器,其中包含了多个ClassLoader对象。通过调整多个类加载器的使用顺序,ClassLoaderWrapper可以确保返回给系统使用的是正确的类加载器。使用ClassLoaderWrapper就如同使用一个ClassLoader对象,ClassLoaderWrapper会按照指定的顺序依次检测其中封装的ClassLoader对象,并从中选取第一个可用的ClassLoader完成相关功能。
public class ClassLoaderWrapper {
ClassLoader defaultClassLoader; // 应用指定的默认类加载器
ClassLoader systemClassLoader; // 系统的ClassLoader
ClassLoaderWrapper() {
try {
// 初始化系统的ClassLoader字段
systemClassLoader = ClassLoader.getSystemClassLoader();
} catch (SecurityException ignored) {
// AccessControlException on Google App Engine
}
}
}
ClassLoaderWrapper的主要功能可以分为三类,分别是getResourceAsURL方法、classForName方法、getResourceAsStream方法,这三个方法都有多个重载,这三类方法最终都会调用参数为String和ClassLoader[]的重载。
public URL getResourceAsURL(String resource) {
return getResourceAsURL(resource, getClassLoaders(null));
}
// getClassLoaders返回ClassLoader数组,该数组指明了类加载器的使用顺序
ClassLoader[] getClassLoaders(ClassLoader classLoader) {
return new ClassLoader[] { classLoader, defaultClassLoader, Thread.currentThread().getContextClassLoader(),
getClass().getClassLoader(), systemClassLoader };
}
URL getResourceAsURL(String resource, ClassLoader[] classLoader) {
URL url;
for (ClassLoader cl : classLoader) { // 遍历ClassLoader数组
if (null != cl) {
// 调用ClassLoader.getResource方法查找指定的资源
url = cl.getResource(resource);
if (null == url) {
// 尝试以"/"开头,再次查找
url = cl.getResource("/" + resource);
}
if (null != url) { // 查找到指定的资源
return url;
}
}
}
// didn't find it anywhere.
return null;
}
Resources是一个提供了多个静态方法的工具类,其中封装了一个ClassLoaderWrapper类型的静态字段,Resources提供的这些静态工具都是通过调用该ClassLoaderWrapper对象的相应方法实现的。
2.5.2 ResolverUtil
ResolverUtil可以根据指定的条件查找指定包下的类,其中使用的条件由Test接口表示。ResolverUtil中使用classLoader字段记录了当前使用的类加载器,默认情况下,使用的是当前线程上下文绑定的ClassLoader,我们可以通过setClassLoader方法修改使用类加载器。
MyBatis提供了两个常用的Test接口实现,分别是IsA和AnnotatedWith。IsA用于检测类是否继承了指定的类或接口,AnnotatedWith用于检测类是否添加了指定的注解。开发人员也可以自己实现Test接口,实现指定条件的检测。
Test接口中定义了matches方法,它用于检测指定类是否符合条件
public interface Test {
// 参数type是待检测的类,返回该类是否满足检测的条件
boolean matches(Class<?> type);
}
IsA和AnnotatedWith的具体实现如下
public static class IsA implements Test { // 用于检测类是否继承了parent指定的类
private final Class<?> parent;
public IsA(Class<?> parentType) {
this.parent = parentType;
}
@Override
public boolean matches(Class<?> type) {
return type != null && parent.isAssignableFrom(type);
}
@Override
public String toString() {
return "is assignable to " + parent.getSimpleName();
}
}
public static class AnnotatedWith implements Test { // 用于检测指定类是否添加了annotation注解
private final Class<? extends Annotation> annotation;
public AnnotatedWith(Class<? extends Annotation> annotation) {
this.annotation = annotation;
}
@Override
public boolean matches(Class<?> type) {
return type != null && type.isAnnotationPresent(annotation);
}
@Override
public String toString() {
return "annotated with @" + annotation.getSimpleName();
}
}
默认情况下,使用Thread.currentThread.getContextClassLoader这个类加载器加载符合条件的类,我们可以在调用find方法之前,调用setClassLoader设置需要使用的ClassLoader,这个ClassLoader可以从ClassLoaderWrapper中获取合适的类加载器。
2.5.3 VFS
VFS表示虚拟文件系统(Virtual File System),它用来查找指定路径下的资源。VFS是一个抽象类,MyBatis中提供了JBoss6VFS 和 DefaultVFS两个VFS的实现,用户也可以提供自定义的VFS实现类
public abstract class VFS {
// 记录了MyBatis提供的两个VFS实现类
public static final Class<?>[] IMPLEMENTATIONS = { JBoss6VFS.class, DefaultVFS.class };
// 记录了用户自定义的VFS实现类
// VFS.addImplClass方法会将指定的VFS实现对应的Class对象添加到这哥集合中
public static final List<Class<? extends VFS>> USER_IMPLEMENTATIONS = new ArrayList<>();
}
VFS.getInstance方法会创建VFS对象,并初始化instance字段,该VFS对象是单例模式的使用静态内部类的写法
public static VFS getInstance() {
return VFSHolder.INSTANCE;
}
private static class VFSHolder {
static final VFS INSTANCE = createVFS();
@SuppressWarnings("unchecked")
static VFS createVFS() {
// 先用用户自定义的VFS实现,然后才用Mybatis提供的VFS实现
List<Class<? extends VFS>> impls = new ArrayList<>(USER_IMPLEMENTATIONS);
impls.addAll(Arrays.asList((Class<? extends VFS>[]) IMPLEMENTATIONS));
VFS vfs = null;
// 遍历impls集合,依次实例化VFS对象是否有效,一旦得到有效的VFS对象则结束循环
for (int i = 0; vfs == null || !vfs.isValid(); i++) {
Class<? extends VFS> impl = impls.get(i);
try {
vfs = impl.getDeclaredConstructor().newInstance();
} catch (InstantiationException | IllegalAccessException | NoSuchMethodException
| InvocationTargetException e) {
log.error("...");
return null;
}
}
return vfs;
}
private VFSHolder() {
}
}
VFS中定义了list和isValid两个抽象方法,isValid负责检测当前VFS对象在当前环境下是否有效,list方法负责查找指定的资源名称列表,在ResolverUtil.find方法查找类文件时会调用list方法的重载方法,该重载最终会调用list(URL,String)这个重载。DefaultVFS的list方法实现如下
@Override
public List<String> list(URL url, String path) throws IOException {
InputStream is = null;
try {
List<String> resources = new ArrayList<>();
// 如果url指向的资源在一个jar包中,则获取Jar包对应的URL,否则返回null
URL jarUrl = findJarForResource(url);
if (jarUrl != null) {
is = jarUrl.openStream();
// 遍历Jar中的资源,并返回以path开头的资源列表
resources = listResources(new JarInputStream(is), path);
} else {
// 遍历url指向的目录,将其资源名称记录到childern集合中,略
// ...
// 遍历children集合,递归查找符合条件的资源名称
for (String child : children) {
String resourcePath = path + "/" + child;
resources.add(resourcePath);
URL childUrl = new URL(prefix + child);
resources.addAll(list(childUrl, resourcePath));
}
}
return resources;
} finally {
// 关闭流
// ...
}
}
protected List<String> listResources(JarInputStream jar, String path) throws IOException {
// 如果path不是以"/"开始和结束,则在其开始和结束位置添加"/"
// ...
// 遍历整个Jar包,将以path开头的资源记录到resources集合中并返回
List<String> resources = new ArrayList<>();
for (JarEntry entry; (entry = jar.getNextJarEntry()) != null;) {
if (!entry.isDirectory()) {
// Add leading slash if it's missing
StringBuilder name = new StringBuilder(entry.getName());
if (name.charAt(0) != '/') {
name.insert(0, '/');
}
// Check file name
if (name.indexOf(path) == 0) { // 检测name是否以path开头
// Trim leading slash
resources.add(name.substring(1));
}
}
}
return resources;
}
2.6 DataSource
在数据持久层中,数据源是一个非常重要的组件,其性能直接关系到整个数据持久层的性能。在实践中比较常见的第三方数据源组件有Apache Common DBCP、C3P0、Proxool等,MyBatis不仅可以集成第三方数据源组件,还提供了自己的数据源实现。
常见的数据源组件都实现了javax.sql.DataSource接口,MyBatis自身实现的数据源实现也不例外。MyBatis提供了两个javax.sql.DataSource接口实现,分别是PooledDataSource和UnpooledDataSource。Mybatis使用不同的DataSourceFactory接口实现创建不同类型的DataSource,这是工厂方法模式的一个典型应用
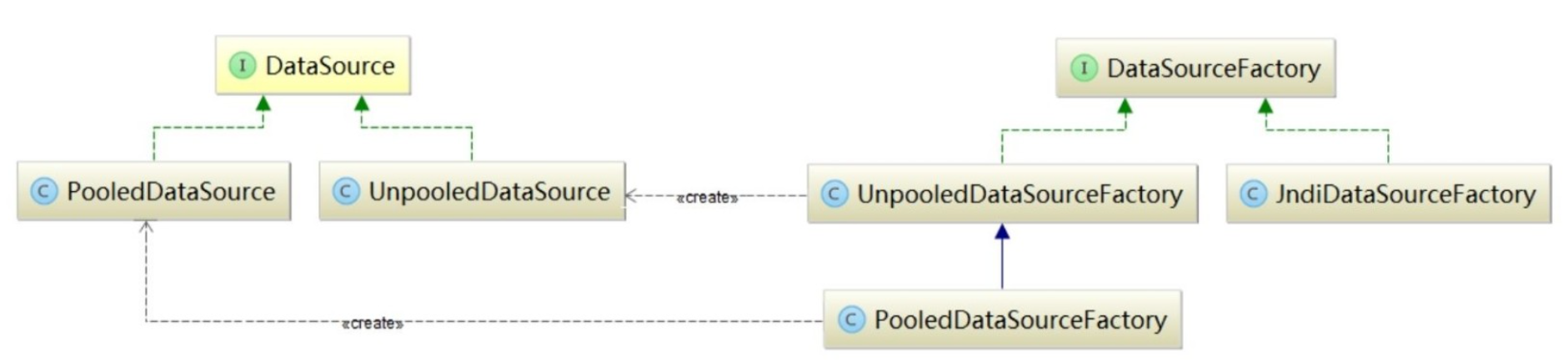
2.6.1 DataSourceFactory
在数据源模块中,DataSourceFactory接口扮演工厂接口的角色。UnpooledDataSourceFactory 和PooledDataSourceFactory则扮演着具体工厂类的角色
public interface DataSourceFactory {
// 设置DataSource的相关属性, 一般紧跟在初始化完成之后
void setProperties(Properties props);
// 获取DataSource对象
DataSource getDataSource();
}
在UnpooledDataSourceFactory的构造函数中会直接创建UnpooledDataSource对象,并初始化UnpooledDataSourceFactory.dataSource字段。UnpooledDataSourceFactory.setProperties()方法会完成对UnpooledDataSource对象的配置
public UnpooledDataSourceFactory() {
this.dataSource = new UnpooledDataSource();
}
@Override
public DataSource getDataSource() {
return dataSource;
}
@Override
public void setProperties(Properties properties) {
Properties driverProperties = new Properties();
// 创建DataSource相应的MetaObject
MetaObject metaDataSource = SystemMetaObject.forObject(dataSource);
// 遍历Properties集合,该集合中配置乐数据源需要的信息
for (Object key : properties.keySet()) {
String propertyName = (String) key;
if (propertyName.startsWith(DRIVER_PROPERTY_PREFIX)) {
String value = properties.getProperty(propertyName);
// 以"driver."开头的配置项是对DataSource的配置,记录到driverProperties
driverProperties.setProperty(propertyName.substring(DRIVER_PROPERTY_PREFIX_LENGTH), value);
} else if (metaDataSource.hasSetter(propertyName)) { // 是否有该属性的setter方法
String value = (String) properties.get(propertyName);
// 根据属性进行类型转换
Object convertedValue = convertValue(metaDataSource, propertyName, value);
// 记录DataSource的相关属性值
metaDataSource.setValue(propertyName, convertedValue);
} else {
throw new DataSourceException("Unknown DataSource property: " + propertyName);
}
}
if (driverProperties.size() > 0) {
// 设置DataSource.driverProperties属性值
metaDataSource.setValue("driverProperties", driverProperties);
}
}
PooledDataSourceFactory继承了UnpooledDataSourceFactory,但并没有覆盖setProperties方法和getDataSource方法。两者唯一的区别是PooledDataSourceFactory的构造函数会将其dataSource字段初始化为PooledDataSource对象。
2.6.2 UnpooledDataSource
javax.sql.DataSource接口在数据源模块中扮演了产品接口的角色,MyBatis提供了两个DataSource接口的实现类,分别是UnpooledDataSource和PooledDataSource,它们扮演着具体产品类的角色。
UnpooledDataSource实现了javax.sql.DataSource接口中定义的getConnection方法及其重载方法,用于获取数据库连接。每次通过UnpooledDataSource.getConnection方法获取数据库连接时都会创建一个新连接,它的属性如下所示:
public class UnpooledDataSource implements DataSource {
// 加载Driver类的类加载器
private ClassLoader driverClassLoader;
// 数据库连接驱动的相关配置
private Properties driverProperties;
// 缓存所有已经注册的数据库连接驱动
private static final Map<String, Driver> registeredDrivers = new ConcurrentHashMap<>();
private String driver; // 驱动连接的驱动名称
private String url; // 数据库URL
private String username; // 数据库用户名
private String password; // 数据库密码
private Boolean autoCommit; // 是否自动提交
private Integer defaultTransactionIsolationLevel; // 事物隔离级别
private Integer defaultNetworkTimeout; // 超时时间
}
创建数据库连接之前,需要先向DriverManager注册JDBC驱动类,DriverManager中定义了registeredDrivers字段用于记录注册的JDBC驱动,UnpooledDataSource中定义了如下静态代码块,在UnpooledDataSource加载时会通过该静态代码块将已在DriverManager中注册的JDBC Driver复制一份到UnpooledDataSource.registeredDrivers集合中
static {
Enumeration<Driver> drivers = DriverManager.getDrivers();
while (drivers.hasMoreElements()) {
Driver driver = drivers.nextElement();
registeredDrivers.put(driver.getClass().getName(), driver);
}
}
UnpooledDataSource.getConnection方法的所有重载最终会调用UnpooledDataSource.doGetConnection方法获取数据库连接
private Connection doGetConnection(Properties properties) throws SQLException {
// 初始化数据库驱动
initializeDriver();
// 创建真正的数据库连接
Connection connection = DriverManager.getConnection(url, properties);
// 配置数据库连接的autoCommit和隔离级别
configureConnection(connection);
return connection;
}
UnpooledDataSource.initializeDriver方法主要负责数据库驱动的初始化,该方法会创建配置中指定的Driver对象,并将其注册到DriverManager以及上面介绍的UnpooledDataSource. registeredDrivers集合中保存。
private synchronized void initializeDriver() throws SQLException {
if (!registeredDrivers.containsKey(driver)) { // 检测驱动是否已经注册
Class<?> driverType;
try {
if (driverClassLoader != null) {
driverType = Class.forName(driver, true, driverClassLoader); // 注册驱动
} else {
driverType = Resources.classForName(driver);
}
Driver driverInstance = (Driver) driverType.getDeclaredConstructor().newInstance(); // 创建Driver对象
// 注册驱动,DriverProxy是定义在UnpooledDataSource中的内部类,是Driver的静态代理类
DriverManager.registerDriver(new DriverProxy(driverInstance));
// 将驱动添加到registeredDrivers中
registeredDrivers.put(driver, driverInstance);
} catch (Exception e) {
throw new SQLException("Error setting driver on UnpooledDataSource. Cause: " + e);
}
}
}
UnpooledDataSource.configureConnection方法主要完成数据库连接的一系列配置
private void configureConnection(Connection conn) throws SQLException {
if (defaultNetworkTimeout != null) {
conn.setNetworkTimeout(Executors.newSingleThreadExecutor(), defaultNetworkTimeout);
}
if (autoCommit != null && autoCommit != conn.getAutoCommit()) {
// 设置事物是否自动提交
conn.setAutoCommit(autoCommit);
}
if (defaultTransactionIsolationLevel != null) {
// 设置事物隔离级别
conn.setTransactionIsolation(defaultTransactionIsolationLevel);
}
}
2.6.3 PooledDataSource
数据库连接的创建过程是非常耗时的,数据库能够建立的连接数也非常有限,所以在绝大多数系统中,数据库连接是非常珍贵的资源,使用数据库连接池就显得尤为必要。使用数据库连接池会带来很多好处,例如,可以实现数据库连接的重用、提高响应速度、防止数据库连接过多造成数据库假死、避免数据库连接泄露等。
数据库连接池在初始化时,一般会创建一定数量的数据库连接并添加到连接池中备用。当程序需要使用数据库连接时,从池中请求连接;当程序不再使用该连接时,会将其返回到池中缓存,等待下次使用,而不是直接关闭。当然,数据库连接池会控制连接总数的上限以及空闲连接数的上限,如果连接池创建的总连接数已达到上限,且都已被占用,则后续请求连接的线程会进入阻塞队列等待,直到有线程释放出可用的连接。如果连接池中空闲连接数较多,达到其上限,则后续返回的空闲连接不会放入池中,而是直接关闭,这样可以减少系统维护多余数据库连接的开销。
如果将总连接数的上限设置得过大,可能因连接数过多而导致数据库僵死,系统整体性能下降;如果总连接数上限过小,则无法完全发挥数据库的性能,浪费数据库资源。如果将空闲连接的上限设置得过大,则会浪费系统资源来维护这些空闲连接;如果空闲连接上限过小,当出现瞬间的峰值请求时,系统的快速响应能力就比较弱。所以在设置数据库连接池的这两个值时,需要进行性能测试、权衡以及一些经验。
PooledDataSource实现了简易数据库连接池的功能,PooledDataSource创建新数据库连接的功能是依赖其中封装的UnpooledDataSource对象实现的。
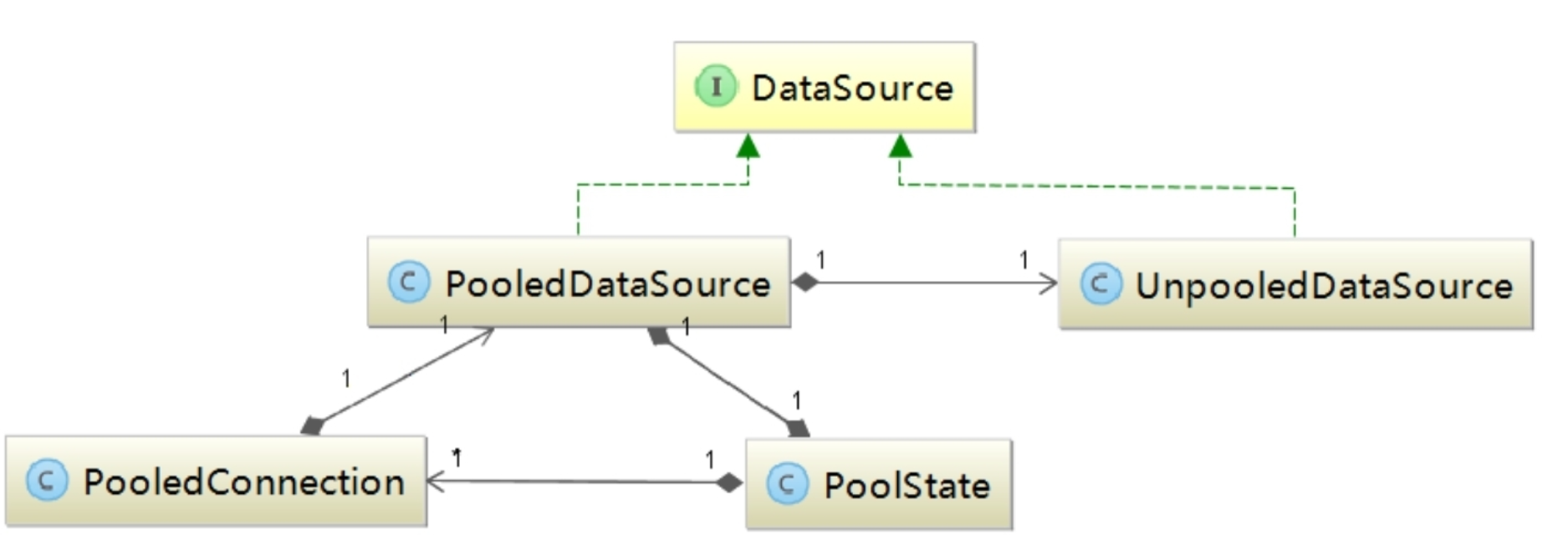
PooledDataSource并不会直接管理java.sql.Connection对象,而是管理PooledConnection对象。在PooledConnection中封装了真正的数据库连接对象(java.sql.Connection)以及其代理对象,这里的代理对象是通过JDK动态代理产生的。PooledConnection中的核心字段如下:
// 记录当前PooledConnection对象所在的PooledDataSource对象。该PooledConnection是从
// 该PooledDataSource中获取的;当调用close方法时会将PooledConnection放回该
// PooledDataSource中
private final PooledDataSource dataSource;
// 真正的数据库连接
private final Connection realConnection;
// 数据库连接的代理对象
private final Connection proxyConnection;
// 从连接池中取出该连接的时间戳
private long checkoutTimestamp;
// 该连接创建的时间戳
private long createdTimestamp;
// 最后一次被使用的世界城
private long lastUsedTimestamp;
// 由数据库URL、用户名和密码算出来的hash值,可用于标识该连接所在的连接池
private int connectionTypeCode;
// 检测当前PooledConnection是否有效。
// 主要防止close方法归还给连接池后仍然通过该连接操作数据库
private boolean valid;
PooledConnection.invoke方法是proxyConnection这个连接代理对象的真正代理逻辑,它会对close方法的调用进行代理,并且在调用真正数据库连接的方法之前进行检测
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
// 如果调用close方法,则将其重新放入连接池,而不是真正关闭数据库连接
if (CLOSE.equals(methodName)) {
dataSource.pushConnection(this);
return null;
}
try {
if (!Object.class.equals(method.getDeclaringClass())) {
checkConnection(); // 通过valid字段检测连接是否有效
}
return method.invoke(realConnection, args); // 调用真正数据库连接对象的对应方法
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
PoolState是用于管理PooledConnection对象状态的组件,它通过两个ArrayList <PooledConnection>集合分别管理空闲状态的连接和活跃状态的连接,以及一系列用于统计的字段
// 空闲的PooledConnection集合
protected final List<PooledConnection> idleConnections = new ArrayList<>();
// 活跃的PooledConnection集合
protected final List<PooledConnection> activeConnections = new ArrayList<>();
// 请求数据库连接的次数
protected long requestCount;
// 获取连接的累积时间
protected long accumulatedRequestTime;
// checkoutTime表示应用从连接池中取出连接,到归还连接这段时长,
// 记录了所有连接累积的checkoutTime时长
protected long accumulatedCheckoutTime;
// 记录了超时的连接个数
protected long claimedOverdueConnectionCount;
// 累积超时时间
protected long accumulatedCheckoutTimeOfOverdueConnections;
// 累积等待时间
protected long accumulatedWaitTime;
// 等待次数
protected long hadToWaitCount;
// 无效的连接数
protected long badConnectionCount;
PooledDataSource中管理的真正的数据库连接对象是由PooledDataSource中封装的UnpooledDataSource对象创建的,并由PoolState管理所有连接的状态。PooledDataSource字段如下:
// 通过PoolState管理连接池的状态并记录统计信息
private final PoolState state = new PoolState(this);
// 记录UnpooledDataSource对象,用于生成真实的数据库连接对象,构造函数中会初始化该字段
private final UnpooledDataSource dataSource;
// 最大活跃连接数
protected int poolMaximumActiveConnections = 10;
// 最大空闲连接数
protected int poolMaximumIdleConnections = 5;
// 最大checkout时长
protected int poolMaximumCheckoutTime = 20000;
// 在无法获取连接时,线程需要等待的时间
protected int poolTimeToWait = 20000;
protected int poolMaximumLocalBadConnectionTolerance = 3;
// 在检测一个数据库连接是否可用时,会给数据库发送一个测试SQL语句
protected String poolPingQuery = "NO PING QUERY SET";
// 是否允许发送测试SQL语句
protected boolean poolPingEnabled;
// 当连接超过poolPingConnectionsNotUsedFor毫秒未使用时,会发送一次测试SQL语句,检测连接是否正常
protected int poolPingConnectionsNotUsedFor;
// 根据数据库的URL、用户名和密码生成的一个hash值,该哈希值用于标志着当前的连接池,在构造函数中初始化
private int expectedConnectionTypeCode;
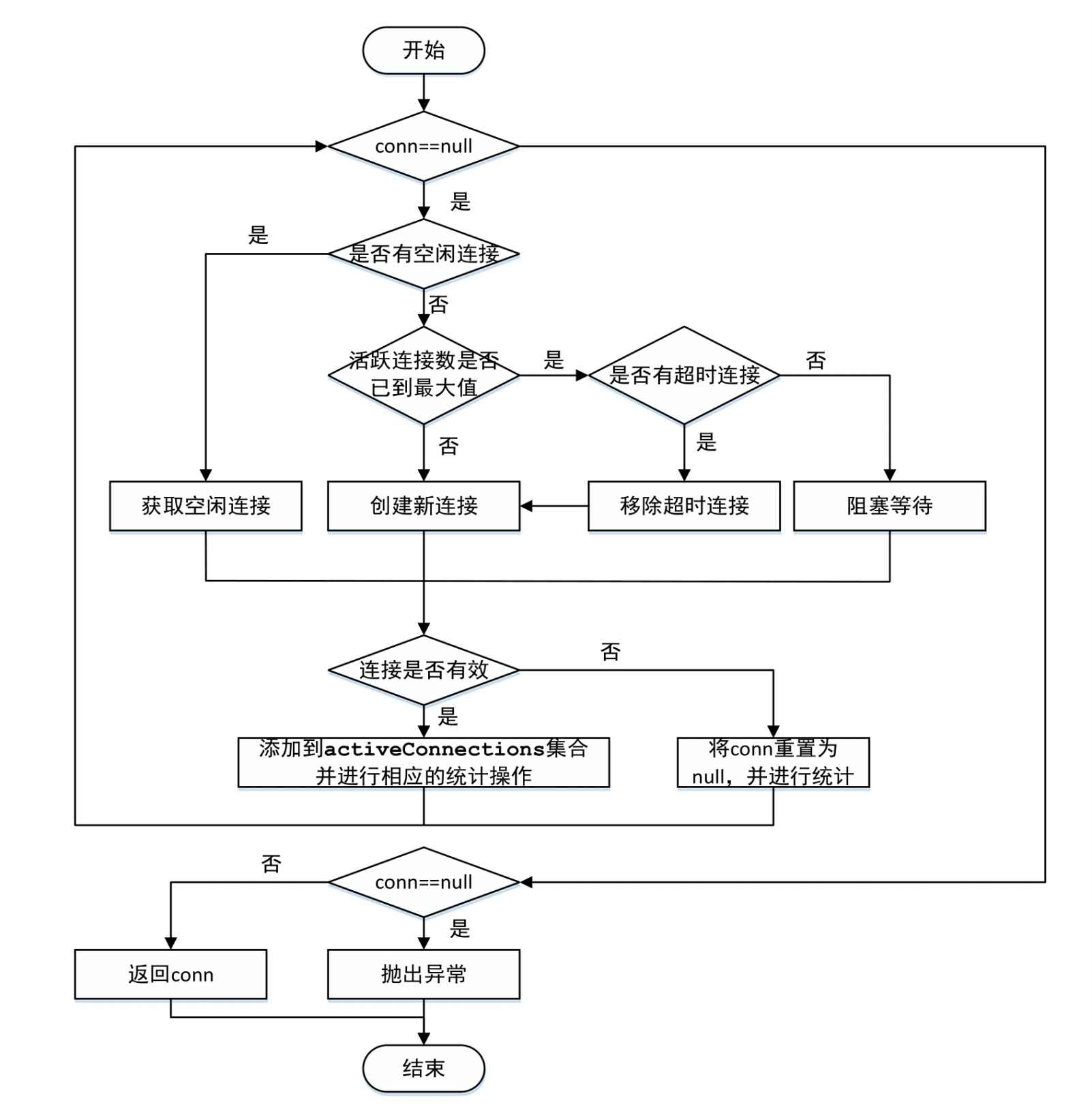
PooledDataSource.getConnection方法首先会调用PooledDataSource.popConnection方法获取PooledConnection对象,然后通过PooledConnection.getProxyConnection方法获取数据库连接的代理对象。popConnection方法是PooledDataSource的核心逻辑之一,其逻辑如图所示:
具体实现如下:
private PooledConnection popConnection(String username, String password) throws SQLException {
boolean countedWait = false;
PooledConnection conn = null;
long t = System.currentTimeMillis();
int localBadConnectionCount = 0;
while (conn == null) {
lock.lock();
try {
if (!state.idleConnections.isEmpty()) { // 检测空闲连接
conn = state.idleConnections.remove(0); // 获取连接
} else if (state.activeConnections.size() < poolMaximumActiveConnections) {
// 活跃连接数没有达到最大值,则可以创建新连接
// 创建新连接,并封装成PooledConnection对象
conn = new PooledConnection(dataSource.getConnection(), this);
} else { // 活跃连接数已经到最大值,则不能创建新连接
// 获取最先创建的活跃连接
PooledConnection oldestActiveConnection = state.activeConnections.get(0);
long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
if (longestCheckoutTime > poolMaximumCheckoutTime) { // 检测该连接是否超时
// 对超时连接的信息进行统计
state.claimedOverdueConnectionCount++;
state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
state.accumulatedCheckoutTime += longestCheckoutTime;
// 将超时连接移除activeConnections集合
state.activeConnections.remove(oldestActiveConnection);
// 如果超时连接未提交,则自动回滚
if (!oldestActiveConnection.getRealConnection().getAutoCommit()) {
try {
oldestActiveConnection.getRealConnection().rollback();
} catch (SQLException e) {
log.debug("Bad connection. Could not roll back");
}
}
// 创建新的PooledConnection对象,但是真正的数据库连接并没有创建新的,还是之前的连接
conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);
conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());
conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());
// 将超时的连接设置为无效
oldestActiveConnection.invalidate();
} else { // 无空闲连接,无法创建新连接,并且没有超时连接,只能阻塞等待
try {
if (!countedWait) {
state.hadToWaitCount++; // 统计等待次数
countedWait = true;
}
long wt = System.currentTimeMillis();
if (!condition.await(poolTimeToWait, TimeUnit.MILLISECONDS)) { // 阻塞等待
log.debug("Wait failed...");
}
state.accumulatedWaitTime += System.currentTimeMillis() - wt; // 统计等待时间
} catch (InterruptedException e) {
// set interrupt flag
Thread.currentThread().interrupt();
break;
}
}
}
if (conn != null) {
if (conn.isValid()) { // 检测PooledConnection是否有效
if (!conn.getRealConnection().getAutoCommit()) {
conn.getRealConnection().rollback();
}
// 配置PooledConnection的相关属性
conn.setConnectionTypeCode(assembleConnectionTypeCode(
dataSource.getUrl(), username, password));
conn.setCheckoutTimestamp(System.currentTimeMillis());
conn.setLastUsedTimestamp(System.currentTimeMillis());
state.activeConnections.add(conn); // 进行相关统计
state.requestCount++;
state.accumulatedRequestTime += System.currentTimeMillis() - t;
} else {
state.badConnectionCount++;
localBadConnectionCount++;
conn = null;
if (localBadConnectionCount >
poolMaximumIdleConnections + poolMaximumLocalBadConnectionTolerance) {
throw new SQLException("PooledDataSource: Could not get a good connection to the database.");
}
}
}
} finally {
lock.unlock();
}
}
if (conn == null) {
throw new SQLException(
"PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
return conn;
}
通过前面对PooledConnection.invoke方法的分析我们知道,当调用连接的代理对象的close方法时,并未关闭真正的数据连接,而是调用PooledDataSource.pushConnection方法将PooledConnection对象归还给连接池供之后重用。PooledDataSource.pushConnection方法也是PooledDataSource的核心逻辑之一
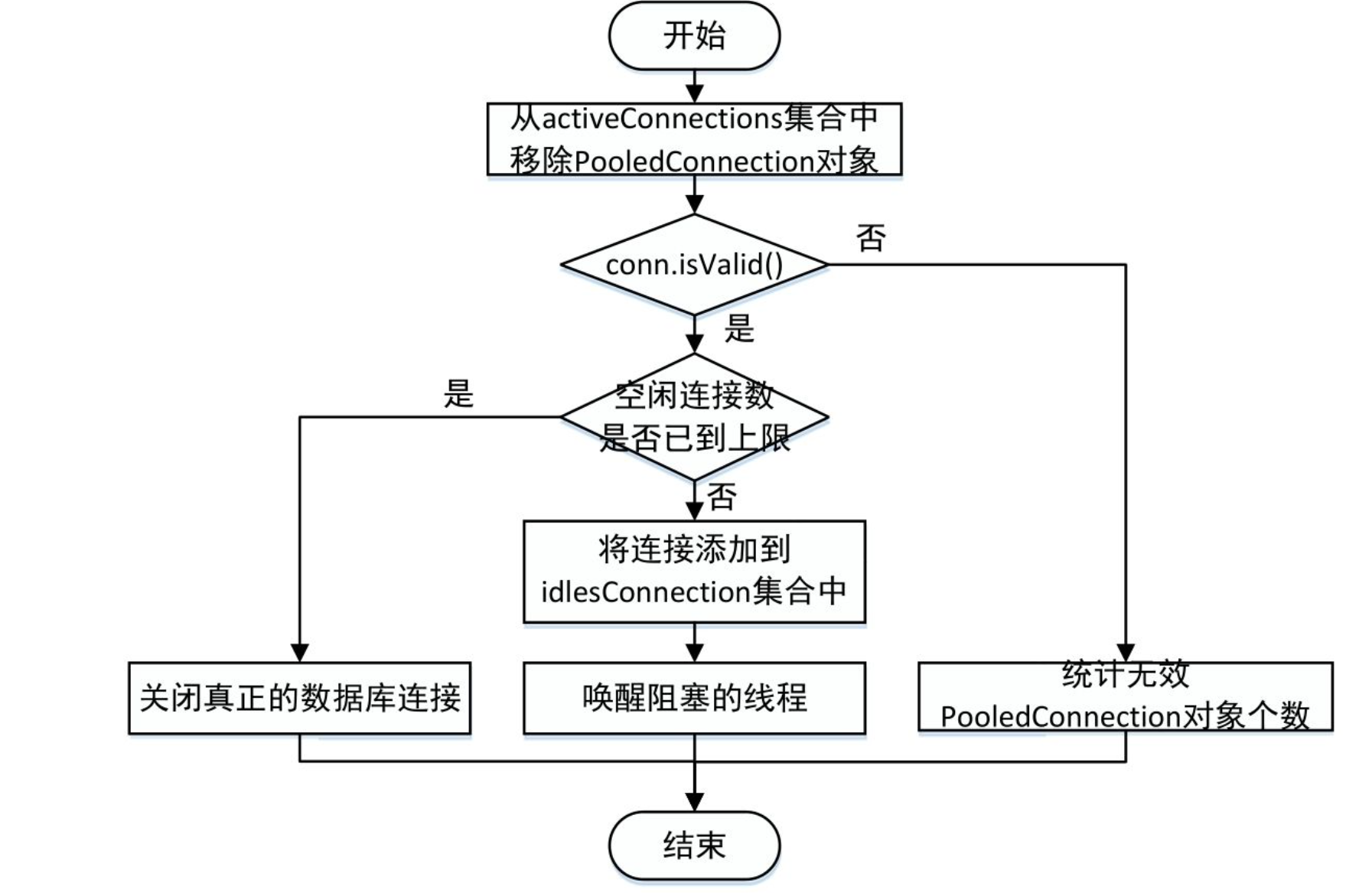
实现代码如下:
protected void pushConnection(PooledConnection conn) throws SQLException {
lock.lock();
try {
// 从activeConnections移除该PooledConnection对象
state.activeConnections.remove(conn);
if (conn.isValid()) { // 检测PooledConnection对象是否有效
// 检测空闲连接数是否已经到达上限,以及PooledConnection是否为该连接池的连接
if (state.idleConnections.size() < poolMaximumIdleConnections
&& conn.getConnectionTypeCode() == expectedConnectionTypeCode) {
state.accumulatedCheckoutTime += conn.getCheckoutTime(); // 累计checkout时长
if (!conn.getRealConnection().getAutoCommit()) { // 回滚未提交的事物
conn.getRealConnection().rollback();
}
// 为返还创建新的PooledConnection对象
PooledConnection newConn = new PooledConnection(conn.getRealConnection(), this);
state.idleConnections.add(newConn); // 添加到idleConnections集合
newConn.setCreatedTimestamp(conn.getCreatedTimestamp());
newConn.setLastUsedTimestamp(conn.getLastUsedTimestamp());
conn.invalidate(); // 将原先对象设置为无效
condition.signal(); // 唤醒阻塞等待线程
} else { // 空闲连接数到达上限或者不属于该连接池
state.accumulatedCheckoutTime += conn.getCheckoutTime(); // 累计checkout时长
if (!conn.getRealConnection().getAutoCommit()) {
conn.getRealConnection().rollback();
}
conn.getRealConnection().close(); // 关闭真正的数据库连接
conn.invalidate(); // 将原先对象设置为无效
}
} else {
state.badConnectionCount++; // 统计无效PooledConnection的个数
}
} finally {
lock.unlock();
}
}
PooledDataSource.pushConnection方法和popConnection方法中都调用了PooledConnection.isValid方法来检测PooledConnection的有效性,该方法除了检测PooledConnection.valid字段的值,还会调用PooledDataSource.pingConnection方法尝试让数据库执行poolPingQuery字段中记录的测试SQL语句,从而检测真正的数据库连接对象是否依然可以正常使用。isValid方法以及pingConnection方法的代码如下:
public boolean isValid() {
return valid && realConnection != null && dataSource.pingConnection(this);
}
protected boolean pingConnection(PooledConnection conn) {
boolean result; // 记录ping操作是否成功
try {
result = !conn.getRealConnection().isClosed(); // 真正的数据库连接是否已经关闭
} catch (SQLException e) {
result = false;
}
// 如果poolPingEnabled设置为false则不执行SQL语句
// 长时间(超过poolPingConnectionsNotUsedFor指定的时长)未使用的连接,才需要使用ping操作
// 来检测数据库连接是否正常
if (result && poolPingEnabled && poolPingConnectionsNotUsedFor >= 0
&& conn.getTimeElapsedSinceLastUse() > poolPingConnectionsNotUsedFor) {
try {
// 执行SQL语句的JDBC操作
Connection realConn = conn.getRealConnection();
try (Statement statement = realConn.createStatement()) {
statement.executeQuery(poolPingQuery).close();
}
if (!realConn.getAutoCommit()) {
realConn.rollback();
}
} catch (Exception e) {
conn.getRealConnection().close();
result = false;
}
}
return result;
}
PooledDataSource.forceCloseAll方法,当修改PooledDataSource的字段时,例如数据库URL、用户名、密码、autoCommit配置等,都会调用forceCloseAll方法将所有数据库连接关闭,同时也会将所有相应的PooledConnection对象都设置为无效,清空activeConnections集合和idleConnections集合。应用系统之后通过PooledDataSource. getConnection获取连接时,会按照新的配置重新创建新的数据库连接以及相应的PooledConnection对象。forceCloseAll方法的具体实现如下:
public void forceCloseAll() {
lock.lock();
try {
// 更新当前连接池的标识
expectedConnectionTypeCode = assembleConnectionTypeCode(
dataSource.getUrl(), dataSource.getUsername(), dataSource.getPassword());
for (int i = state.activeConnections.size(); i > 0; i--) { // 处理全部的活跃连接
try {
// 从activeConnections中获取PooledConnection对象
PooledConnection conn = state.activeConnections.remove(i - 1);
conn.invalidate(); // 将PooledConnection对象设置未无效
Connection realConn = conn.getRealConnection(); // 获取真正的数据库连接对象
if (!realConn.getAutoCommit()) { // 回滚未提交的事物
realConn.rollback();
}
realConn.close(); // 关闭真正的数据库连接
} catch (Exception e) {
// ignore
}
}
// 同样的逻辑处理空闲的连接
for (int i = state.idleConnections.size(); i > 0; i--) {
// ...
}
} finally {
lock.unlock();
}
}
2.7 Transaction
MyBatis使用Transaction接口对数据库事务进行了抽象,Transaction接口的定义如下
public interface Transaction {
// 获取对应的数据库连接对象
Connection getConnection() throws SQLException;
// 提交事物
void commit() throws SQLException;
// 回滚事物
void rollback() throws SQLException;
// 关闭数据库连接
void close() throws SQLException;
// 获取事物超时时间
Integer getTimeout() throws SQLException;
}
Transaction接口有JdbcTransaction、ManagedTransaction两个实现,其对象分别由JdbcTransactionFactory和ManagedTransactionFactory负责创建。这里也使用了工厂方法模式。
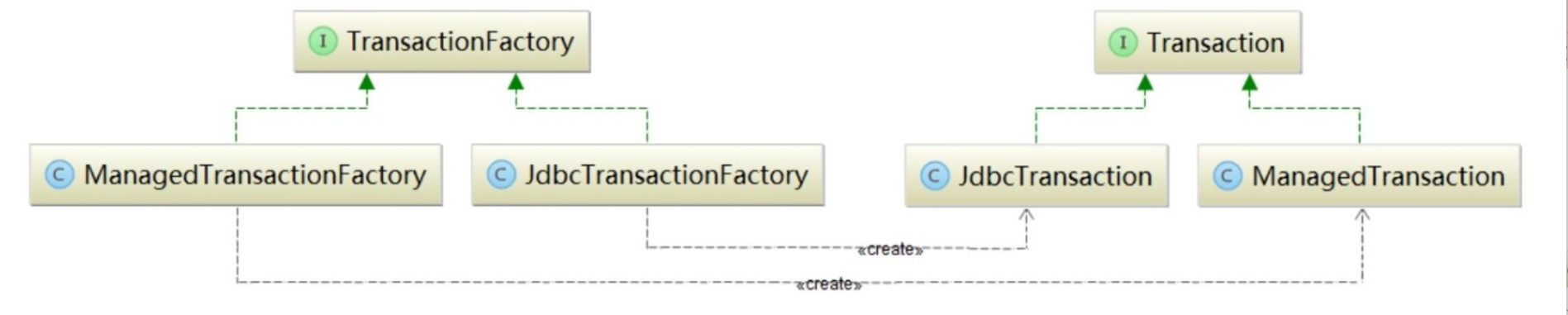
JdbcTransaction依赖于JDBC Connection控制事务的提交和回滚。JdbcTransaction中字段的含义如下:
protected Connection connection; // 事务对应的数据库连接
protected DataSource dataSource; // 数据库连接所属的DataSource
protected TransactionIsolationLevel level; // 事务隔离级别
protected boolean autoCommit; // 是否自动提交
在JdbcTransaction的构造函数中会初始化除connection字段之外的其他三个字段,而connection字段会延迟初始化,它会在调用getConnection方法时通过dataSource.getConnection方法初始化,并且同时设置autoCommit和事务隔离级别。JdbcTransaction的commit方法和rollback方法都会调用Connection对应方法实现的。
ManagedTransaction的实现更加简单,它同样依赖其中的dataSource字段获取连接,但其commit、rollback方法都是空实现,事务的提交和回滚都是依靠容器管理的。ManagedTransaction中通过closeConnection字段的值控制数据库连接的关闭行为。
TransactionFactory接口定义了配置新建TransactionFactory对象的方法,以及创建Transaction对象的方法,实现都是new出来,这里就不贴代码了
public interface TransactionFactory {
// 配置TransactionFactory 一般紧跟在创建完成之后,完成对TransactionFactory的自定义配置
default void setProperties(Properties props) {
// NOP
}
// 在指定的连接上创建Transaction对象
Transaction newTransaction(Connection conn);
// 从指定数据源中获取数据库连接,并在此连接之上创建Transaction对象
Transaction newTransaction(DataSource dataSource, TransactionIsolationLevel level, boolean autoCommit);
}
在实践中,MyBatis通常会与Spring集成使用,数据库的事务是交给Spring进行管理的,涉及到Transaction接口的另一个实现SpringManagedTransaction,这个后面再说
2.8 binding模块
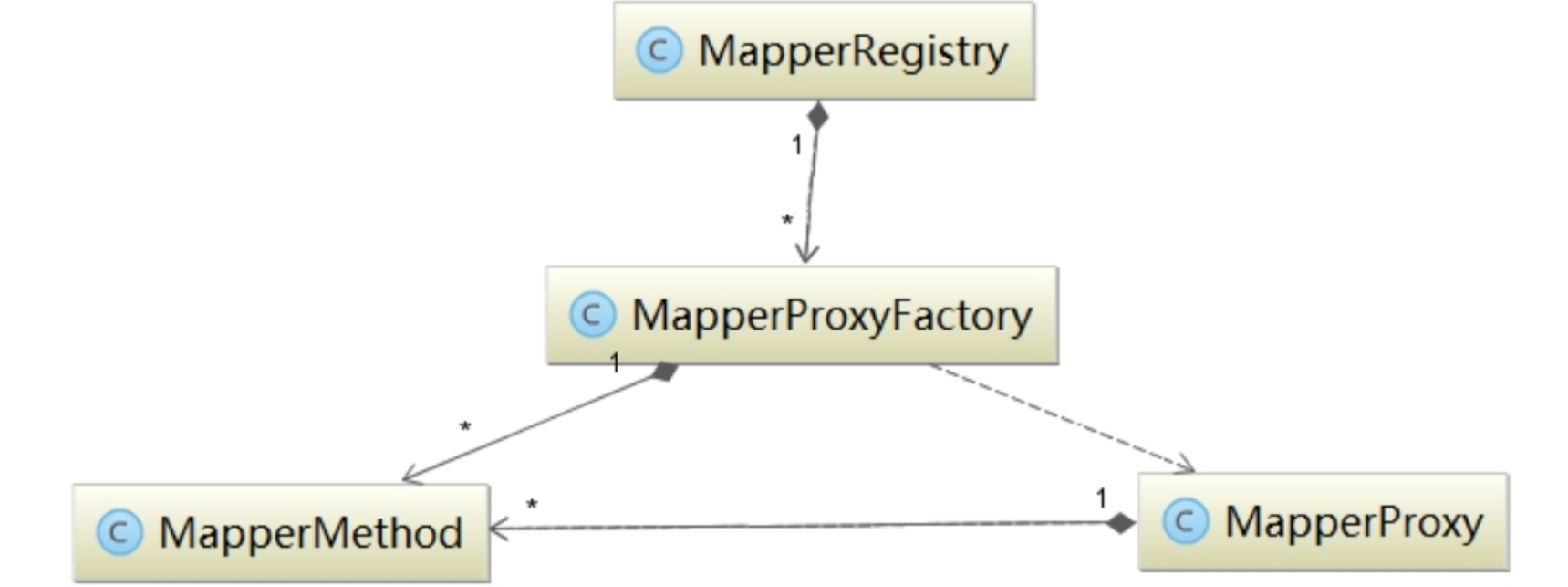
在iBatis(MyBatis的前身)中,查询一个Blog对象时需要调用SqlSession.queryForObject方法。queryForObject方法会执行指定的SQL语句进行查询并返回一个结果对象,第一个参数“selectBlog”指明了具体执行的SQL语句的id,该SQL语句定义在相应的映射配置文件中。如果我们错将“selectBlog”写成了“selectBlog1”,在初始化过程中,MyBatis是无法提示该错误的,而在实际调用queryForObject方法时才会抛出异常,开发人员才能知道该错误。MyBatis提供了binding模块用于解决上述问题。binding模块的核心组件之间的关系如下图所示:
2.8.1 MapperRegistry和MapperProxyFactory
MapperRegistry是Mapper接口及其对应的代理对象工厂的注册中心。Configuration是MyBatis全局性的配置对象,在MyBatis初始化的过程中,所有配置信息会被解析成相应的对象并记录到Configuration对象中,Configuration.mapperRegistry字段记录当前使用的MapperRegistry对象,MapperRegistry中字段的含义和功能如下
// Configuration对象,Mybatis全局唯一配置对象,其中包含了所有的配置信息
private final Configuration config;
// 记录了Mapper接口与对应MapperProxyFactory之间的关系
private final Map<Class<?>, MapperProxyFactory<?>> knownMappers = new ConcurrentHashMap<>();
在MyBatis初始化过程中会读取映射配置文件以及Mapper接口中的注解信息,并调用MapperRegistry.addMapper方法填充MapperRegistry.knownMappers集合,该集合的key是Mapper接口对应的Class对象,value为MapperProxyFactory工厂对象,可以为Mapper接口创建代理对象
public <T> void addMapper(Class<T> type) {
if (type.isInterface()) { // type是否为接口
if (hasMapper(type)) { // 是否已经加载过该接口
throw new BindingException("Type " + type + " is already known to the MapperRegistry.");
}
boolean loadCompleted = false;
try {
// 将mapper接口对应的class对象和MapperProxyFactory对象添加到knownMappers集合
knownMappers.put(type, new MapperProxyFactory<>(type));
// XML解析和注解的处理
MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type);
parser.parse();
loadCompleted = true;
} finally {
if (!loadCompleted) {
knownMappers.remove(type);
}
}
}
}
在需要执行某SQL语句时,会先调用MapperRegistry.getMapper方法获取实现了Mapper接口的代理对象
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
// 查找指定type对应的MapperProxyFactory对象
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
// 创建实现了type接口的代理对象
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
MapperProxyFactory主要负责创建代理对象,newInstance方法实现了创建实现了mapperInterface接口的代理对象的功能
public class MapperProxyFactory<T> {
// 当前MapperProxyFactory对象可以创建实现了mapperInterface接口的代理对象
private final Class<T> mapperInterface;
// 缓存,key是mapperInterface接口中某方法对应的Method对象,value是对应的MapperMethodInvoker对象
private final Map<Method, MapperMethodInvoker> methodCache = new ConcurrentHashMap<>();
protected T newInstance(MapperProxy<T> mapperProxy) {
// 创建实现了mapperInterface接口的代理对象
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}
public T newInstance(SqlSession sqlSession) {
// 创建MapperProxy对象,每次调用都会创建新的MapperProxy对象
final MapperProxy<T> mapperProxy = new MapperProxy<>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
}
2.8.2 MapperProxy
MapperProxy实现了InvocationHandler接口,MapperProxy.invoke方法是代理对象执行的主要逻辑
public class MapperProxy<T> implements InvocationHandler, Serializable {
// 记录了关联的SqlSession对象
private final SqlSession sqlSession;
// mapper接口对应的class对象
private final Class<T> mapperInterface;
// 缓存,key是mapper接口中某方法对应的Method对象,value是对应的MapperMethod对象
// MapperMethod对象会完成参数转换以及SQL语句的执行功能
// MapperMethod并不记录任何状态相关的信息,因此可以在多个代理对象见共享
private final Map<Method, MapperMethodInvoker> methodCache
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
// 如果目标方法继承自Object,则之间调用目标方法
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
}
// 从缓存中获取MapperMethodInvoker对象,如果缓存中没有,则创建新的MapperMethodInvoker对象添加到缓存中
// 然后调用invoke方法
return cachedInvoker(method).invoke(proxy, method, args, sqlSession);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
// 上面提到的MapperMethodInvoker对象
interface MapperMethodInvoker {
Object invoke(Object proxy, Method method, Object[] args, SqlSession sqlSession) throws Throwable;
}
// MapperMethodInvoker对象的一个实现类
private static class PlainMethodInvoker implements MapperMethodInvoker {
private final MapperMethod mapperMethod;
public PlainMethodInvoker(MapperMethod mapperMethod) {
this.mapperMethod = mapperMethod;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args, SqlSession sqlSession)
throws Throwable {
// 调用MapperMethod.execute方法执行SQL语句
return mapperMethod.execute(sqlSession, args);
}
}
}
2.8.3 MapperMethod
MapperMethod中封装了Mapper接口中对应方法的信息,以及对应SQL语句的信息,MapperMethod可以看作连接Mapper接口以及映射配置文件中定义的SQL语句的桥梁,它的字段如下:
// 记录了SQL语句的名称与类型
private final SqlCommand command;
// Mapper接口中对应的方法的相关信息
private final MethodSignature method;
2.8.3.1 SQLCommand
SqlCommand是MapperMethod中定义的内部类,它使用name字段记录了SQL语句的名称,使用type字段(SqlCommandType类型)记录了SQL语句的类型。SqlCommandType是枚举类型,有效取值为UNKNOWN、INSERT、UPDATE、DELETE、SELECT、FLUSH。
SqlCommand的构造方法会初始化name字段和type字段:
public SqlCommand(Configuration configuration, Class<?> mapperInterface, Method method) {
final String methodName = method.getName();
final Class<?> declaringClass = method.getDeclaringClass();
// 获得MappedStatement对象
MappedStatement ms = resolveMappedStatement(mapperInterface,
methodName, declaringClass, configuration);
if (ms == null) {
if (method.getAnnotation(Flush.class) == null) { // 处理@Flush注解
throw new BindingException(
"Invalid bound statement (not found): " + mapperInterface.getName() + "." + methodName);
}
name = null;
type = SqlCommandType.FLUSH;
} else { // 初始花花name和type
name = ms.getId();
type = ms.getSqlCommandType();
if (type == SqlCommandType.UNKNOWN) {
throw new BindingException("Unknown execution method for: " + name);
}
}
}
private MappedStatement resolveMappedStatement(Class<?> mapperInterface, String methodName,
Class<?> declaringClass,
Configuration configuration) {
// SQL语句的名称是由Mapper接口的名称与对应的方法名称组成的
String statementId = mapperInterface.getName() + "." + methodName;
if (configuration.hasStatement(statementId)) { // 检测是否有该名称的SQL语句
// 从configuration.mappedStatements集合中查找对应的MappedStatement对象
// MappedStatement对象中封装了SQL语句相关的信息,在Mybatis初始化的时候创建
return configuration.getMappedStatement(statementId);
}
if (mapperInterface.equals(declaringClass)) {
return null;
}
// 如果方法的在父接口中定义的,递归查找
for (Class<?> superInterface : mapperInterface.getInterfaces()) {
if (declaringClass.isAssignableFrom(superInterface)) {
MappedStatement ms = resolveMappedStatement(superInterface,
methodName, declaringClass, configuration);
if (ms != null) {
return ms;
}
}
}
return null;
}
2.8.3.2 ParamNameResolver
在MethodSignature中,会使用ParamNameResolver处理Mapper接口中定义的方法的参数列表。ParamNameResolver使用name字段记录了参数在参数列表中的位置索引与参数名称之间的对应关系,其中key表示参数在参数列表中的索引位置,value表示参数名称,参数名称可以通过@Param注解指定,如果没有指定@Param注解,则使用参数索引作为其名称。如果参数列表中包含RowBounds类型或ResultHandler类型的参数,则这两种类型的参数并不会被记录到name集合中,这就会导致参数的索引与名称不一致
ParamNameResolver的hasParamAnnotation字段记录对应方法的参数列表中是否使用了@Param注解。
在ParamNameResolver的构造方法中,会通过反射的方式读取Mapper接口中对应方法的信息,并初始化上述两个字段
public ParamNameResolver(Configuration config, Method method) {
this.useActualParamName = config.isUseActualParamName();
// 获取参数列表中每个参数的类型
final Class<?>[] paramTypes = method.getParameterTypes();
// 获取参数列表上的注解
final Annotation[][] paramAnnotations = method.getParameterAnnotations();
// 该集合用于记录参数索引与参数名称的对应关系
final SortedMap<Integer, String> map = new TreeMap<>();
int paramCount = paramAnnotations.length;
for (int paramIndex = 0; paramIndex < paramCount; paramIndex++) { // 遍历方法所有参数
if (isSpecialParameter(paramTypes[paramIndex])) { // 如果参数类型是RowBounds类型或ResultHandler类型
continue;
}
String name = null;
for (Annotation annotation : paramAnnotations[paramIndex]) { // 遍历参数对应的注解集合
if (annotation instanceof Param) { // @Param注解出现过
hasParamAnnotation = true; // 将hasParamAnnotation设置成true
name = ((Param) annotation).value(); // 获取@Param注解指定的名称
break;
}
}
if (name == null) { // 该参数没有对应的@Param注解
if (useActualParamName) { // 根据配置决定是否使用参数实际名称作为其名称
name = getActualParamName(method, paramIndex);
}
if (name == null) { // 使用参数的索引作为其名称
name = String.valueOf(map.size());
}
}
map.put(paramIndex, name); // 记录到MAP中保存
}
names = Collections.unmodifiableSortedMap(map); // 初始化names集合
}
private static boolean isSpecialParameter(Class<?> clazz) {
return RowBounds.class.isAssignableFrom(clazz) || ResultHandler.class.isAssignableFrom(clazz);
}
names集合主要在ParamNameResolver.getNamedParams方法中使用,该方法接收的参数是用户传入的实参列表,并将实参与其对应名称进行关联
public Object getNamedParams(Object[] args) {
final int paramCount = names.size();
if (args == null || paramCount == 0) { // 无参数,返回null
return null;
}
if (!hasParamAnnotation && paramCount == 1) { // 未使用@Param且只有一个参数
Object value = args[names.firstKey()];
return wrapToMapIfCollection(value, useActualParamName ? names.get(names.firstKey()) : null);
} else {
// param这个Map记录了参数名称与实参之间的对应关系。ParamMap继承了HashMap
// 如果向ParamMap添加已经存在的key,会报错,其他与HashMap相同
final Map<String, Object> param = new ParamMap<>();
int i = 0;
for (Map.Entry<Integer, String> entry : names.entrySet()) {
// 将参数名与实参对应关系记录到param中
param.put(entry.getValue(), args[entry.getKey()]);
// 为参数创建"param + 索引"格式的默认参数名称, 如param1,param2等等
final String genericParamName = GENERIC_NAME_PREFIX + (i + 1);
// 如果@Param注解指定的参数名称就是"param + 索引"格式的, 就不用再添加了
if (!names.containsValue(genericParamName)) {
param.put(genericParamName, args[entry.getKey()]); // 添加@Param指定的格式
}
i++;
}
return param;
}
}
2.8.3.3 MethodSignature
MethodSignature也是MapperMethod中定义的内部类,其中封装了Mapper接口中定义的方法的相关信息,MethodSignature中核心字段的含义如下
private final boolean returnsMany; // 返回值是否为Collection类型或者是数组类型
private final boolean returnsMap; // 返回值是否为Map类型
private final boolean returnsVoid; // 返回值类型是否为void
private final boolean returnsCursor; // 返回值类型是否为Cursor类型
private final Class<?> returnType; // 返回值类型
private final String mapKey; // 如果返回值类型是Map,则该字段记录了作为key的列明
private final Integer resultHandlerIndex; // 用来标记该方法中参数列表中ResultHandler类型参数的位置
private final Integer rowBoundsIndex; // 用来标记该方法中参数列表中RowBounds类型参数的位置
private final ParamNameResolver paramNameResolver; // 方法对应的ParamNameResolver对象
在MethodSignature的构造函数中会解析相应的Method对象,并初始化上述字段
public MethodSignature(Configuration configuration, Class<?> mapperInterface, Method method) {
// 解析放回值的方法类型,TypeParameterResolver可以看2.2.2
Type resolvedReturnType = TypeParameterResolver.resolveReturnType(method, mapperInterface);
if (resolvedReturnType instanceof Class<?>) {
this.returnType = (Class<?>) resolvedReturnType;
} else if (resolvedReturnType instanceof ParameterizedType) {
this.returnType = (Class<?>) ((ParameterizedType) resolvedReturnType).getRawType();
} else {
this.returnType = method.getReturnType();
}
// 初始化returnsXXX字段
this.returnsVoid = void.class.equals(this.returnType);
this.returnsMany = configuration.getObjectFactory().isCollection(this.returnType)
|| this.returnType.isArray();
this.returnsCursor = Cursor.class.equals(this.returnType);
this.returnsOptional = Optional.class.equals(this.returnType);
// 若MethodSignature对应方法的返回值是Map且指定了@MapKey注解,则使用getMapKey方法进行处理
this.mapKey = getMapKey(method);
this.returnsMap = this.mapKey != null;
// 初始化rowBoundsIndex和resultHandlerIndex字段
this.rowBoundsIndex = getUniqueParamIndex(method, RowBounds.class);
this.resultHandlerIndex = getUniqueParamIndex(method, ResultHandler.class);
// 创建ParamNameResolver对象
this.paramNameResolver = new ParamNameResolver(configuration, method);
}
getUniqueParamIndex方法的主要功能是查找指定类型的参数在参数列表中的位置
private Integer getUniqueParamIndex(Method method, Class<?> paramType) {
Integer index = null;
final Class<?>[] argTypes = method.getParameterTypes();
for (int i = 0; i < argTypes.length; i++) { // 遍历MethodSignature对应方法的参数列表
if (paramType.isAssignableFrom(argTypes[i])) {
if (index != null) { // RowBounds和ResultHandler类型的参数只能有一个,不能重复出现
throw new BindingException(
method.getName() + " cannot have multiple " +
paramType.getSimpleName() + " parameters");
}
index = i; // 记录paramType类型参数在参数列表中的位置索引
}
}
return index;
}
2.8.3.4 MapperMethod
MapperMethod中定义的内部类介绍完成后回到MapperMethod,MapperMethod中最核心的方法是execute方法,它会根据SQL语句的类型调用SqlSession对应的方法完成数据库操作
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
switch (command.getType()) { // 根据SQL语句的类型调用SQLSession对应的方法
case INSERT: {
// 使用ParamNameResolver处理args[]数组,将用户传入的实参列表与指定参数名称关联起来
Object param = method.convertArgsToSqlCommandParam(args);
// 调用SQLSession的insert方法,rowCountResult会根据method字段中记录的方法的返回值类型对结果进行转换
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
// UPDATE和DELETE与insert类似
case UPDATE: {
// ...
}
case DELETE: {
// ...
}
case SELECT:
// 处理返回值类型为void缺ResultSet通过ResultHandler处理的方法
if (method.returnsVoid() && method.hasResultHandler()) {
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) { // 处理返回值为集合或数组
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) { // 处理返回值为map
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) { // 处理返回值为Cursor
result = executeForCursor(sqlSession, args);
} else { // 处理单一对象返回值
Object param = method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(command.getName(), param);
if (method.returnsOptional() && (result == null ||
!method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
case FLUSH:
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
// ... 边界检查
return result;
}
当执行INSERT、UPDATE、DELETE类型的SQL语句时,其执行结果都需要经过MapperMethod.rowCountResult方法处理。SqlSession中的insert等方法返回的是int值,rowCountResult方法会将该int值转换成Mapper接口中对应方法的返回值
private Object rowCountResult(int rowCount) {
final Object result;
if (method.returnsVoid()) {
result = null; // 返回值为void
} else if (Integer.class.equals(method.getReturnType()) ||
Integer.TYPE.equals(method.getReturnType())) {
result = rowCount; // 返回值为int或者Integer
} else if (Long.class.equals(method.getReturnType()) ||
Long.TYPE.equals(method.getReturnType())) {
result = (long) rowCount; // 返回值为long或者Long
} else if (Boolean.class.equals(method.getReturnType()) ||
Boolean.TYPE.equals(method.getReturnType())) {
result = rowCount > 0; // 返回值为Boolean
} else {
throw new BindingException("...");
}
return result;
}
如果Mapper接口中定义的方法准备使用ResultHandler处理查询结果集,则通过MapperMethod.executeWithResultHandler方法处理
private void executeWithResultHandler(SqlSession sqlSession, Object[] args) {
// 获取SQL语句对应的MappedStatement对象,MappedStatement中记录了SQL语句的相关信息
MappedStatement ms = sqlSession.getConfiguration().getMappedStatement(command.getName());
// 当使用ResultHandler处理结果集时,必须指定ResultMap或者ResultType
if (!StatementType.CALLABLE.equals(ms.getStatementType())
&& void.class.equals(ms.getResultMaps().get(0).getType())) {
throw new BindingException("...");
}
// 转换实参列表
Object param = method.convertArgsToSqlCommandParam(args);
if (method.hasRowBounds()) { // 参数中是否有RowBounds类型的参数
// 获取RowBound是对象,根据MethodSignature.rowBoundsIndex字段指定位置,从args数组中查找
RowBounds rowBounds = method.extractRowBounds(args);
// 调用SQLSession的select方法,执行查询,并由指定的ResultHandler处理结果对象
sqlSession.select(command.getName(), param, rowBounds, method.extractResultHandler(args));
} else {
sqlSession.select(command.getName(), param, method.extractResultHandler(args));
}
}
如果Mapper接口中对应方法的返回值为数组或是Collection接口实现类,则通过MapperMethod.executeForMany方法处理
private <E> Object executeForMany(SqlSession sqlSession, Object[] args) {
List<E> result;
Object param = method.convertArgsToSqlCommandParam(args); // 参数列表转换
if (method.hasRowBounds()) { // 检测是否指定了RowBounds参数
RowBounds rowBounds = method.extractRowBounds(args);
// 调用SQLSession.selectList方法进行查询
result = sqlSession.selectList(command.getName(), param, rowBounds);
} else {
result = sqlSession.selectList(command.getName(), param);
}
// 将结果集转换为数组或者Collection集合
// 实现与上面rowCountResult基本相似
if (!method.getReturnType().isAssignableFrom(result.getClass())) {
if (method.getReturnType().isArray()) {
return convertToArray(result);
}
return convertToDeclaredCollection(sqlSession.getConfiguration(), result);
}
return result;
}
如果Mapper接口中对应方法的返回值为Map类型,则通过MapperMethod.executeForMap方法处理,实现也基本相同
private <K, V> Map<K, V> executeForMap(SqlSession sqlSession, Object[] args) {
Map<K, V> result;
Object param = method.convertArgsToSqlCommandParam(args);
if (method.hasRowBounds()) {
RowBounds rowBounds = method.extractRowBounds(args);
result = sqlSession.selectMap(command.getName(), param, method.getMapKey(), rowBounds);
} else {
result = sqlSession.selectMap(command.getName(), param, method.getMapKey());
}
return result;
}
2.9 缓存模块
MyBatis作为一个强大的持久层框架,缓存是其必不可少的功能之一。MyBatis中的缓存是两层结构的,分为一级缓存、二级缓存,但在本质上是相同的,它们使用的都是Cache接口的实现, MyBatis中缓存模块相关的代码位于cache包下。
2.9.1 Cache
Cache接口是缓存模块中最核心的接口,它定义了所有缓存的基本行为。
public interface Cache {
// 该缓存对象的ID
String getId();
// 向缓存中添加数据,一般情况下,key是cachekey, value是查询的结果
void putObject(Object key, Object value);
// 根据指定的key,在缓存中查找对应的结果对象
Object getObject(Object key);
// 删除key对应的缓存项
Object removeObject(Object key);
// 清空缓存
void clear();
// 缓存项的个数,该方法不会被核心代码使用,所以可提供空实现
int getSize();
// 获取读写所,该方法不会被核心代码使用,所以可提供空实现
default ReadWriteLock getReadWriteLock() {
return null;
}
}
Cache接口的实现类有多,但大部分都是装饰器,只有PerpetualCache提供了Cache接口的基本实现
2.9.2 PerpetualCache
PerpetualCache在缓存模块中扮演着ConcreteComponent的角色,其实现比较简单,底层使用HashMap记录缓存项,也是通过该HashMap对象的方法实现的Cache接口中定义的相应方法。
public class PerpetualCache implements Cache {
// Cache对象的唯一标识
private final String id;
// 用于记录缓存的Map对象
private final Map<Object, Object> cache = new HashMap<>();
public PerpetualCache(String id) {
this.id = id;
}
@Override
public String getId() {
return id;
}
@Override
public int getSize() {
return cache.size();
}
@Override
public void putObject(Object key, Object value) {
cache.put(key, value);
}
@Override
public Object getObject(Object key) {
return cache.get(key);
}
@Override
public Object removeObject(Object key) {
return cache.remove(key);
}
@Override
public void clear() {
cache.clear();
}
}
2.9.3 缓存装饰器
cache.decorators包下提供的装饰器,它们都直接实现了Cache接口,扮演着ConcreteDecorator的角色。这些装饰器会在PerpetualCache的基础上提供一些额外的功能,通过多个组合后满足一个特定的需求,后面介绍二级缓存时,会见到这些装饰器是如何完成动态组合的。
2.9.3.1 BlockingCache
BlockingCache是阻塞版本的缓存装饰器,它会保证只有一个线程到数据库中查找指定key对应的数据。BlockingCache中各个字段的含义如下
// 阻塞超时时长
private long timeout;
// 被装饰的底层Cache对象
private final Cache delegate;
// 每个Key都有一个对应的CountDownLatch对象
private final ConcurrentHashMap<Object, CountDownLatch> locks;
假设线程A在BlockingCache中未查找到keyA对应的缓存项时,线程A会获取keyA对应的锁,这样后续线程在查找keyA时会发生阻塞
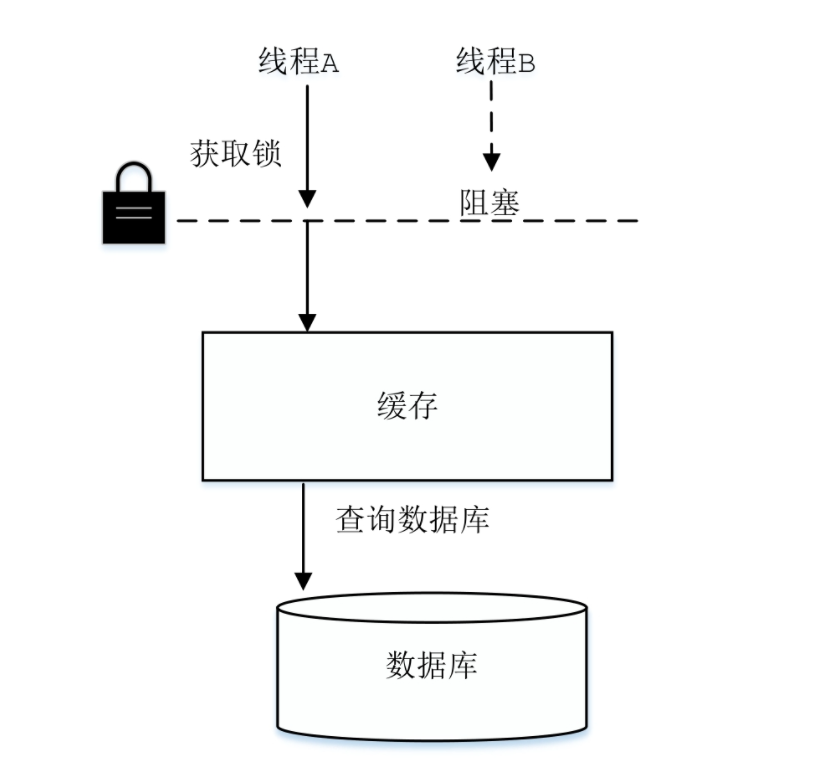
BlockingCache.getObject方法的代码如下
@Override
public Object getObject(Object key) {
acquireLock(key); // 获取该key对应的锁
Object value = delegate.getObject(key); // 查询key
if (value != null) { // 缓存有key的对应缓存项,释放锁,否则继续持有锁
releaseLock(key);
}
return value;
}
acquireLock方法中会尝试获取指定key对应的锁。如果该key没有对应的锁对象则为其创建新的CountDownLatch对象,再加锁;如果获取锁失败,则阻塞一段时间。acquireLock方法的实现如下:
private void acquireLock(Object key) {
CountDownLatch newLatch = new CountDownLatch(1);
while (true) {
CountDownLatch latch = locks.putIfAbsent(key, newLatch); // 想要获取锁
if (latch == null) { // key不在hashmap存在,表明没有任何人持有锁,而且自己的锁也放到map中去了,溜了
break;
}
// 这个时候latch就是上一个人的锁
try {
if (timeout > 0) { // 没超时,等待
boolean acquired = latch.await(timeout, TimeUnit.MILLISECONDS);
if (!acquired) { // 超时,抛出移除
throw new CacheException("...");
}
} else {
latch.await(); // 等着
}
} catch (InterruptedException e) {
throw new CacheException("...");
}
}
}
假设线程A从数据库中查找到keyA对应的结果对象后,将结果对象放入到BlockingCache中,此时线程A会释放keyA对应的锁,唤醒阻塞在该锁上的线程。其他线程即可从BlockingCache中获取keyA对应的数据,而不是再次访问数据库
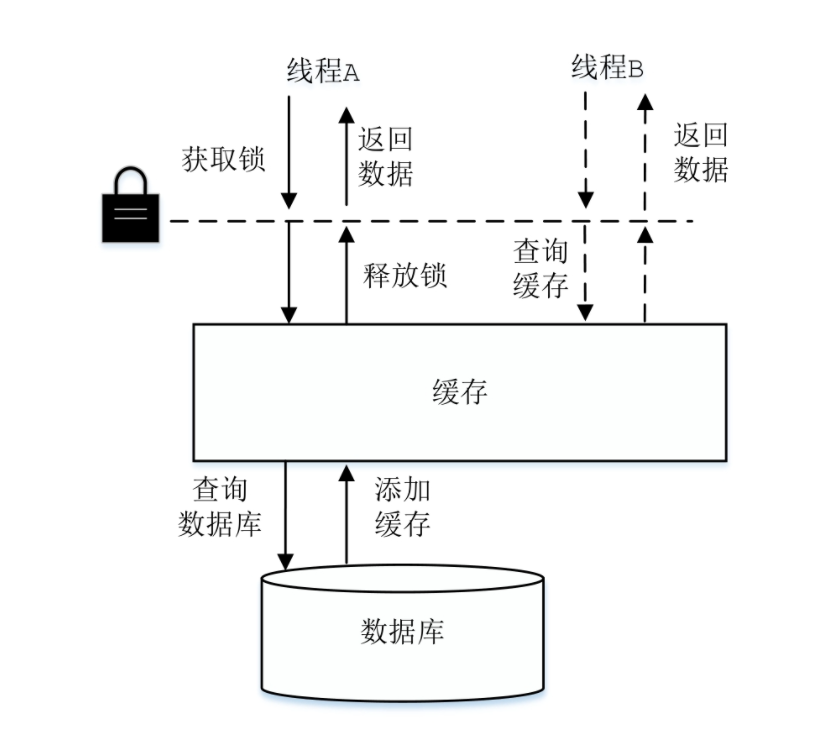
BlockingCache.putObject方法的实现如下
@Override
public void putObject(Object key, Object value) {
try {
delegate.putObject(key, value); // 向缓存中添加缓存项
} finally {
releaseLock(key); // 释放锁
}
}
private void releaseLock(Object key) {
CountDownLatch latch = locks.remove(key); // 删除map中的key
if (latch == null) { // 那我之前放到map中的值呢??
throw new IllegalStateException("...");
}
latch.countDown(); // 释放锁
}
2.9.3.2 FifoCache和LruCache
在很多场景中,为了控制缓存的大小,系统需要按照一定的规则清理缓存。FifoCache是先入先出版本的装饰器,当向缓存添加数据时,如果缓存项的个数已经达到上限,则会将缓存中最老(即最早进入缓存)的缓存项删除,FifoCache中各个字段的含义如下
// 底层被装饰的底层Cache对象
private final Cache delegate;
// 用于记录Key进入缓存的先后顺序,使用的是LinkedList对象
private final Deque<Object> keyList;
// 缓存项的上限,超过该值,则需要清理最老的缓存项
private int size;
FifoCache.getObject和removeObject方法的实现都是直接调用底层Cache对象的对应方法,不再赘述。在FifoCache.putObject方法中会完成缓存项个数的检测以及缓存的清理操作
@Override
public void putObject(Object key, Object value) {
cycleKeyList(key); // 检测并清理缓存
delegate.putObject(key, value); // 添加缓存项
}
private void cycleKeyList(Object key) {
keyList.addLast(key); // 记录key
if (keyList.size() > size) { // 如果到达上限,清理最老的缓存项
Object oldestKey = keyList.removeFirst();
delegate.removeObject(oldestKey);
}
}
LruCache是按照近期最少使用算法(Least Recently Used,LRU)进行缓存清理的装饰器,在需要清理缓存时,它会清除最近最少使用的缓存项。LruCache中定义的各个字段的含义如下:
// 底层被装饰的底层Cache对象
private final Cache delegate;
// LinkedHashMap类型的对象,是一个有序的HashMap,用于记录key最近的使用清空
private Map<Object, Object> keyMap;
// 记录最少被使用的缓存项key
private Object eldestKey;
LruCache的构造函数中默认设置的缓存大小是1024,我们可以通过其setSize方法重新设置缓存大小
public void setSize(final int size) {
// 第三个参数为true表明记录的顺序是access-order,调用get方法会改变其记录的顺序
keyMap = new LinkedHashMap<>(size, .75F, true)
@Override
// 当调用LinkedHashMap的put方法时,会调用该方法
protected boolean removeEldestEntry(Map.Entry<Object, Object> eldest) {
boolean tooBig = size() > size;
if (tooBig) { // 如果到达缓存上限,则更新eldestKey字段,后面会删除该项
eldestKey = eldest.getKey();
}
return tooBig;
}
};
}
LruCache.getObject方法除了返回缓存项,还会调用keyMap.get方法修改key的顺序,表示指定的key最近被使用。LruCache.putObject方法除了添加缓存项,还会将eldestKey字段指定的缓存项清除掉。
@Override
public Object getObject(Object key) {
keyMap.get(key); // 修改LinkedHashMap中记录的顺序
return delegate.getObject(key);
}
@Override
public void putObject(Object key, Object value) {
delegate.putObject(key, value); // 添加缓存项
cycleKeyList(key); // 删除最久未使用的缓存项
}
private void cycleKeyList(Object key) {
keyMap.put(key, key);
if (eldestKey != null) {
delegate.removeObject(eldestKey);
eldestKey = null;
}
}
2.9.3.3 SoftCache和WeakCache
SoftCache和WeakCache来源与Java提供的引用类型:软引用和弱引用
软引用是引用强度仅弱于强引用的一种引用,它使用类SoftReference 来表示。当Java虚拟机内存不足时,GC会回收那些只被软引用指向的对象,从而避免内存溢出。在GC释放了那些只被软引用指向的对象之后,虚拟机内存依然不足,才会抛出OutOfMemoryError异常。软引用适合引用那些可以通过其他方式恢复的对象,例如,数据库缓存中的对象就可以从数据库中恢复,所以软引用可以用来实现缓存,下面将要介绍的SoftCache就是通过软引用实现的。由于在程序使用软引用之前的某个时刻,其所指向的对象可能已经被GC回收掉了,所以通过Reference.get()方法来获取软引用所指向的对象时,总是要通过检查该方法返回值是否为null,来判断被软引用的对象是否还存活。
弱引用的强度比软引用的强度还要弱。弱引用使用WeakReference来表示,它可以引用一个对象,但并不阻止被引用的对象被GC回收。在JVM虚拟机进行垃圾回收时,如果指向一个对象的所有引用都是弱引用,那么该对象会被回收。由此可见,只被弱引用所指向的对象的生存周期是两次GC之间的这段时间,而只被软引用所指向的对象可以经历多次GC,直到出现内存紧张的情况才被回收。
在很多场景下,我们的程序需要在一个对象的可达性(是否已经被GC回收)发生变化时得到通知,引用队列就是用于收集这些信息的队列。在创建SoftReference对象时,可以为其关联一个引用队列,当SoftReference所引用的对象被GC回收时,Java虚拟机就会将该SoftReference对象添加到与之关联的引用队列中。当需要检测这些通知信息时,就可以从引用队列中获取这些SoftReference对象。
SoftCache中各个字段的含义如下:
//在SoftCache中,最近使用的一部分缓存项不会被GC回收,这就是通过将其value添加到
// hardLinksToAvoidGarbageCollection集合中实现的(即有强引用指向其value)
private final Deque<Object> hardLinksToAvoidGarbageCollection;
// 引用队列,用于记录已经被GC回收的缓存项所对应的SoftEntry对象
private final ReferenceQueue<Object> queueOfGarbageCollectedEntries;
// 底层被装饰的底层Cache对象
private final Cache delegate;
// 强连接的个数,默认值是256
private int numberOfHardLinks;
SoftCache中缓存项的value是SoftEntry对象,SoftEntry继承了SoftReference,其中指向key的引用是强引用,而指向value的引用是软引用。SoftEntry的实现如下
private static class SoftEntry extends SoftReference<Object> {
private final Object key;
SoftEntry(Object key, Object value, ReferenceQueue<Object> garbageCollectionQueue) {
super(value, garbageCollectionQueue); // 指向value的引用是软引用,且关联了引用队列
this.key = key; // 强引用
}
}
SoftCache.putObject方法除了向缓存中添加缓存项,还会清除已经被GC回收的缓存项,其具体实现如下
@Override
public void putObject(Object key, Object value) {
removeGarbageCollectedItems(); // 清除已经被GC回收的缓存项
delegate.putObject(key, new SoftEntry(key, value, queueOfGarbageCollectedEntries)); // 项缓存中添加缓存项
}
private void removeGarbageCollectedItems() {
SoftEntry sv;
while ((sv = (SoftEntry) queueOfGarbageCollectedEntries.poll()) != null) {
// 遍历queueOfGarbageCollectedEntries集合
// 将已经被GC回收的value对象对应的缓存项清除
delegate.removeObject(sv.key);
}
}
SoftCache.getObject方法除了从缓存中查找对应的value,处理被GC回收的value对应的缓存项,还会更新hardLinksToAvoidGarbageCollection集合,具体实现如下
@Override
public Object getObject(Object key) {
Object result = null;
@SuppressWarnings("unchecked")
// 从缓存中查找对应的缓存项
SoftReference<Object> softReference = (SoftReference<Object>) delegate.getObject(key);
if (softReference != null) { // 检测缓存中是否有对应缓存项
result = softReference.get(); // 获取SoftReference引用的value
if (result == null) { // 已经被GC回收
delegate.removeObject(key); // 从缓存中清除对应的缓存项
} else { // 未被GC回收
synchronized (hardLinksToAvoidGarbageCollection) {
// 缓存项的value添加到hardLinksToAvoidGarbageCollection集合中保存
hardLinksToAvoidGarbageCollection.addFirst(result);
if (hardLinksToAvoidGarbageCollection.size() > numberOfHardLinks) {
// 超过numberOfHardLinks,使用先进先出清除最老的缓存项
hardLinksToAvoidGarbageCollection.removeLast();
}
}
}
}
return result;
}
removeObject方法在清除缓存项之前,也会调用removeGarbageCollectedItems方法清理被GC回收的缓存项。clear方法首先清理hardLinksToAvoidGarbageCollection集合,然后清理被GC回收的缓存项,最后清理底层delegate缓存中的缓存项
WeakCache的实现与SoftCache基本类似,唯一的区别在于其中使用WeakEntry(继承自WeakReference)封装真正的value对象,其他实现完全一样,就不再赘述了
2.9.3.4 ScheduledCache
ScheduledCache是周期性清理缓存的装饰器,它的clearInterval字段记录了两次缓存清理之间的时间间隔,默认是一小时,lastClear字段记录了最近一次清理的时间戳。ScheduledCache 的getObject、putObject、removeObject等核心方法在执行时,都会根据这两个字段检测是否需要进行清理操作,清理操作会清空缓存中所有缓存项。
2.9.3.5 LoggingCache
LoggingCache在Cache的基础上提供了日志功能,它通过hit字段和request字段记录了Cache的命中次数和访问次数。在LoggingCache.getObject方法中会统计命中次数和访问次数这两个指标,并按照指定的日志输出方式输出命中率。
2.9.3.6 SynchronizedCache
SynchronizedCache通过在每个方法上添加synchronized关键字,为Cache添加了同步功能,有点类似于JDK中Collections中的SynchronizedCollection内部类的实现
2.9.3.7 SerializedCache
SerializedCache提供了将value对象序列化的功能。SerializedCache在添加缓存项时,会将value对应的Java对象进行序列化,并将序列化后的byte[]数组作为value存入缓存。SerializedCache在获取缓存项时,会将缓存项中的byte[]数组反序列化成Java对象。使用前面介绍的Cache装饰器实现进行装饰之后,每次从缓存中获取同一key对应的对象时,得到的都是同一对象,任意一个线程修改该对象都会影响到其他线程以及缓存中的对象;而SerializedCache每次从缓存中获取数据时,都会通过反序列化得到一个全新的对象。SerializedCache使用的序列化方式是Java原生序列化
2.9.4 CacheKey
在Cache中唯一确定一个缓存项需要使用缓存项的key,MyBatis中因为涉及动态SQL等多方面因素,其缓存项的key不能仅仅通过一个String表示,所以MyBatis提供了CacheKey类来表示缓存项的key,在一个CacheKey对象中可以封装多个影响缓存项的因素。
CacheKey中可以添加多个对象,由这些对象共同确定两个CacheKey对象是否相同。CacheKey中核心字段的含义和功能如下:
// 参与计算hashcode,默认是37
private final int multiplier;
// 初始hashcode,初始值是17
private int hashcode;
// 校验和
private long checksum;
// updateList集合的个数
private int count;
// 由该集合中的所有对象共同决定两个CacheKey是否相同
private List<Object> updateList;
CacheKey对象可以由下面四个部分构成:
- MappedStatement的id
- 指定查询结果集的范围,也就是RowBounds.offset和RowBounds.limit。
- 查询所使用的SQL语句,也就是boundSql.getSql()方法返回的SQL语句,其中可能包含“?”占位符。
- 用户传递给上述SQL语句的实际参数值。
在向CacheKey.updateList集合中添加对象时,使用的是CacheKey.update方法,具体实现如下:
public void update(Object object) {
int baseHashCode = object == null ? 1 : ArrayUtil.hashCode(object);
// 重新计算count,hashcode,checksum的值
count++;
checksum += baseHashCode;
baseHashCode *= count;
hashcode = multiplier * hashcode + baseHashCode;
updateList.add(object);
}
CacheKey重写了equals方法和hashCode方法,这两个方法使用上面介绍的count、checksum、hashcode、updateList比较CacheKey对象是否相同
@Override
public boolean equals(Object object) {
if (this == object) { // 是否是同一对象
return true;
}
if (!(object instanceof CacheKey)) { // 是否类型相同
return false;
}
final CacheKey cacheKey = (CacheKey) object;
if ((hashcode != cacheKey.hashcode) || (checksum != cacheKey.checksum) || (count != cacheKey.count)) {
// 比较三个数字
return false;
}
// 比较updateList每一项
for (int i = 0; i < updateList.size(); i++) {
Object thisObject = updateList.get(i);
Object thatObject = cacheKey.updateList.get(i);
if (!ArrayUtil.equals(thisObject, thatObject)) {
return false;
}
}
return true;
}
@Override
public int hashCode() {
return hashcode;
}
3 核心处理层
核心处理层以第2章介绍的基础支持层为基础,实现了MyBatis的核心功能。主要包括MyBatis的初始化、动态SQL语句的解析、结果集的映射、参数解析以及SQL语句的执行等几个方面。
3.1 Mybatis的初始化
类似于Spring、MyBatis等灵活性和可扩展性都很高的开源框架都提供了很多配置项,开发人员需要在使用时提供相应的配置信息,实现相应的需求。MyBatis中的配置文件主要有两个,分别是mybatis-config.xml配置文件和映射配置文件。
现在主流的配置方式除了使用XML配置文件,还会配合注解进行配置。在MyBatis初始化的过程中,除了会读取mybatis-config.xml配置文件以及映射配置文件,还会加载配置文件指定的类,处理类中的注解,创建一些配置对象,最终完成框架中各个模块的初始化。另外,也可以使用Java API的方式对MyBatis进行配置,这种硬编码的配置方式主要用在配置量比较少且配置信息不常变化的场景下。
3.1.1 BaseBuilder
MyBatis初始化的主要工作是加载并解析mybatis-config.xml配置文件、映射配置文件以及相关的注解信息。MyBatis的初始化入口是SqlSessionFactoryBuilder.build方法
public SqlSessionFactory build(Reader reader, String environment, Properties properties) {
try {
// 读取配置文件
XMLConfigBuilder parser = new XMLConfigBuilder(reader, environment, properties);
// 解析配置文件得到Configuration对象,创建DefaultSqlSessionFactory对象
return build(parser.parse());
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
ErrorContext.instance().reset();
try {
if (reader != null) {
reader.close();
}
} catch (IOException e) {
// Intentionally ignore. Prefer previous error.
}
}
}
SqlSessionFactoryBuilder.build方法会创建XMLConfigBuilder对象来解析mybatis-config.xml配置文件,而XMLConfigBuilder继承自BaseBuilder抽象类
MyBatis的初始化过程使用了建造者模式,这里的BaseBuilder抽象类就扮演着建造者接口的角色。BaseBuilder中核心字段的含义如下
// Configuration是Mybatis初始化过程的核心对象,Mybatis中几乎所有配置信息都会保存
// 到Configuration对象中。Configuration对象是在Mybatis初始化过程中创建且全局唯一
protected final Configuration configuration;
// 在mybatis-config.xml配置文件中可以使用typeAliases标签定义别名,这些定义的别名都会保存
// 在TypeAliasRegistry中,这个类可以见2.3.3
protected final TypeAliasRegistry typeAliasRegistry;
// 在mybatis-config.xml配置文件中可以使用typeRegistry标签定义TypeHandler
// 完成指定数据库类型和Java类型的转换,这些TypeHandler都会记录在TypeHandlerRegistry中
// 这个类可以见2.3.2
protected final TypeHandlerRegistry typeHandlerRegistry;
BaseBuilder中记录的TypeAliasRegistry对象和TypeHandlerRegistry对象,其实是全局唯一的,它们都是在Configuration对象初始化时创建的
在BaseBuilder构造函数中,通过相应的Configuration.get*方法得到TypeAliasRegistry对象和TypeHandlerRegistry对象,并赋值给BaseBuilder相应字段
BaseBuilder.resolveAlias方法依赖TypeAliasRegistry解析别名,BaseBuilder.resolveTypeHandler方法依赖TypeHandlerRegistry查找指定的TypeHandler对象。
MyBatis使用JdbcType枚举类型表示JDBC类型。MyBatis中常用的枚举类型还有ResultSetType和ParameterMode:ResultSetType枚举类型表示结果集类型,使用ParameterMode枚举类型表示存储过程中的参数类型。在BaseBuilder中提供了相应的resolveJdbcType、resolveResultSetType、resolveParameterMode方法,将String转换成对应的枚举对象,实现比较简单
3.1.2 XMLConfigBuilder
XMLConfigBuilder是BaseBuilder的众多子类之一,它扮演的是具体建造者的角色。XMLConfigBuilder主要负责解析mybatis-config.xml配置文件,其核心字段如下
// 标记是否解析过mybatis-config.xml配置文件
private boolean parsed;
// 用于解析mybatis-config.xml配置文件的XPathParser对象,可以见2.1
private final XPathParser parser;
// 标识environment配置的名称,默认读取default属性
private String environment;
// ReflectorFactory负责创建和缓存Reflector对象,可以见2.2.1
private final ReflectorFactory localReflectorFactory = new DefaultReflectorFactory();
XMLConfigBuilder.parse方法是解析mybatis-config.xml配置文件的入口,它通过调用XMLConfigBuilder.parseConfiguration方法实现整个解析过程
public Configuration parse() {
if (parsed) {
throw new BuilderException("Each XMLConfigBuilder can only be used once.");
}
parsed = true;
// 在mybatis-config.xml中查找configuration节点,并开始解析
parseConfiguration(parser.evalNode("/configuration"));
return configuration;
}
private void parseConfiguration(XNode root) {
try {
// 解析各个节点
propertiesElement(root.evalNode("properties"));
Properties settings = settingsAsProperties(root.evalNode("settings"));
loadCustomVfsImpl(settings);
loadCustomLogImpl(settings);
typeAliasesElement(root.evalNode("typeAliases"));
pluginsElement(root.evalNode("plugins"));
objectFactoryElement(root.evalNode("objectFactory"));
objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
reflectorFactoryElement(root.evalNode("reflectorFactory"));
settingsElement(settings); // 将settings值设置到Configuration中
// read it after objectFactory and objectWrapperFactory issue #631
environmentsElement(root.evalNode("environments"));
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
typeHandlersElement(root.evalNode("typeHandlers"));
mappersElement(root.evalNode("mappers"));
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
}
XMLConfigBuilder 将mybatis-config.xml配置文件中每个节点的解析过程封装成了一个相应的方法
3.1.2.1 properties
XMLConfigBuilder.propertiesElement方法会解析mybatis-config.xml配置文件中的properties节点并形成java.util.Properties对象,之后将该Properties对象设置到XPathParser和Configuration的variables字段中。在后面的解析过程中,会使用该Properties对象中的信息替换占位符
private void propertiesElement(XNode context) throws Exception {
if (context == null) {
return;
}
// 解析properties子节点(property)的name和value属性,并记录到properties中
Properties defaults = context.getChildrenAsProperties();
// 解析properties的resource和url属性,用于确定properties配置文件的位置
String resource = context.getStringAttribute("resource");
String url = context.getStringAttribute("url");
// 不能同时存在,否则会抛出异常
if (resource != null && url != null) {
throw new BuilderException("...");
}
// 加载resource属性或者url属性指定的properties文件
if (resource != null) {
defaults.putAll(Resources.getResourceAsProperties(resource));
} else if (url != null) {
defaults.putAll(Resources.getUrlAsProperties(url));
}
// 与Configuration文件中的匹variables集合合并
Properties vars = configuration.getVariables();
if (vars != null) {
defaults.putAll(vars);
}
// 更新XPathParser和Configuration的variables字段
parser.setVariables(defaults);
configuration.setVariables(defaults);
}
3.1.2.2 setting
XMLConfigBuilder.settingsAsProperties方法负责解析settings节点,在settings节点下的配置是MyBatis全局性的配置,它们会改变MyBatis的运行时行为,具体配置项的含义参考MyBatis官方文档。需要注意的是,在MyBatis初始化时,这些全局配置信息都会被记录到Configuration对象的对应属性中。例如,开发人员可以通过配置autoMappingBehavior修改MyBatis是否开启自动映射的功能
settingsAsProperties方法的解析方式与propertiesElement方法类似,但是多了使用MetaClass检测key指定的属性在Configuration类中是否有对应setter方法的步骤
private Properties settingsAsProperties(XNode context) {
if (context == null) {
return new Properties();
}
// 解析settings子节点(setting)的name和value属性,并记录到properties中
Properties props = context.getChildrenAsProperties();
// 创建Configuration对应的MetaClass对象
MetaClass metaConfig = MetaClass.forClass(Configuration.class, localReflectorFactory);
for (Object key : props.keySet()) {
// Configuration是否定义了key属性相应的Setter方法
if (!metaConfig.hasSetter(String.valueOf(key))) {
throw new BuilderException( "...");
}
}
return props;
}
3.1.2.3 typeAliases, typeHandlers
XMLConfigBuilder.typeAliasesElement方法负责解析typeAliases节点及其子节点,并通过TypeAliasRegistry完成别名的注册
private void typeAliasesElement(XNode context) {
if (context == null) {
return;
}
for (XNode child : context.getChildren()) { // 处理全部子节点
if ("package".equals(child.getName())) { // 处理package节点
// 获取指定的包名
String typeAliasPackage = child.getStringAttribute("name");
// 通过TypeAliasRegistry扫描指定包中的所有的类,并解析@Alias注解,完成别名注册
configuration.getTypeAliasRegistry().registerAliases(typeAliasPackage);
} else { // 处理typeAlias节点
String alias = child.getStringAttribute("alias"); // 获取指定的别名
String type = child.getStringAttribute("type"); // 获取别名对应的类型
try {
Class<?> clazz = Resources.classForName(type);
if (alias == null) {
typeAliasRegistry.registerAlias(clazz); // 扫描@Alias注解,完成注册
} else {
typeAliasRegistry.registerAlias(alias, clazz); // 注册别名
}
} catch (ClassNotFoundException e) {
throw new BuilderException("...");
}
}
}
}
XMLConfigBuilder.typeHandlerElement方法负责解析typeHandlers节点,并通过TypeHandlerRegistry对象完成TypeHandler的注册,该方法的实现与上述typeAliasesElement方法类似
3.1.2.4 plugin
插件是MyBatis提供的扩展机制之一,用户可以通过添加自定义插件在SQL语句执行过程中的某一点进行拦截。MyBatis中的自定义插件只需实现 Interceptor 接口,并通过注解指定想要拦截的方法签名即可。pluginElement方法负责解析plugins节点中定义的插件,并完成实例化和配置操作
private void pluginsElement(XNode context) throws Exception {
if (context != null) {
for (XNode child : context.getChildren()) { // 遍历全部plugin节点
// 获取plugin的interceptor属性值
String interceptor = child.getStringAttribute("interceptor");
// 获取plugin下properties配置的信息,并封装成Properties对象
Properties properties = child.getChildrenAsProperties();
// 通过TypeAliasRegistry解析别名后,实例化Interceptor对象
Interceptor interceptorInstance = (Interceptor) resolveClass(interceptor).getDeclaredConstructor()
.newInstance();
// 设置Interceptor属性
interceptorInstance.setProperties(properties);
// 记录Interceptor对象
configuration.addInterceptor(interceptorInstance);
}
}
}
所有配置的Interceptor对象都是通过Configuration.interceptorChain字段管理的,InterceptorChain底层使用ArrayList实现
3.1.2.5 objectFactory
基础支持层时提到过,我们可以通过添加自定义Objectory实现类、ObjectWrapperFactory实现类以及ReflectorFactory实现类对MyBatis进行扩展。objectFactoryElement方法负责解析并实例化objectFactory节点指定的ObjectFactory实现类,之后将自定义的ObjectFactory对象记录到Configuration.objectFactory字段中
private void objectFactoryElement(XNode context) throws Exception {
if (context != null) {
// 获取ObjectFactory节点的type属性
String type = context.getStringAttribute("type");
// 获取ObjectFactory下properties配置的信息,并封装成Properties对象
Properties properties = context.getChildrenAsProperties();
// 通过ObjectFactory解析别名后,实例化ObjectFactory对象
ObjectFactory factory = (ObjectFactory) resolveClass(type).getDeclaredConstructor().newInstance();
// 记录自定义ObjectFactory属性,完成初始化的相关操作
factory.setProperties(properties);
// 将自定义ObjectFactory对象记录到Configuration对象的ObjectFactory字段中,待后续使用
configuration.setObjectFactory(factory);
}
}
XMLConfigBuilder对objectWrapperFactory节点、reflectorFactory节点的解析与上述过程类似,最终会将解析得到的自定义对象记录到Configuration的相应字段中
3.1.2.6 environments
在实际生产中,同一项目可能分为开发、测试和生产多个不同的环境,每个环境的配置可能也不尽相同。MyBatis可以配置多个environment节点,每个environment节点对应一种环境的配置。但需要注意的是,尽管可以配置多个环境,每个 SqlSessionFactory 实例只能选择其一
XMLConfigBuilder.environmentsElement方法负责解析environments的相关配置,它会根据XMLConfigBuilder.environment字段值确定要使用的environment配置,之后创建对应的TransactionFactory和DataSource对象,并封装进Environment对象中
private void environmentsElement(XNode context) throws Exception {
if (context == null) {
return;
}
if (environment == null) {
// 未指定environment字段,酒使用default属性指定的environment
environment = context.getStringAttribute("default");
}
for (XNode child : context.getChildren()) {
String id = child.getStringAttribute("id");
if (isSpecifiedEnvironment(id)) { // 与XMLConfigBuilder.environment字段匹配
// 先通过TypeAliasRegistry解析别名后创建TransactionFactory
TransactionFactory txFactory = transactionManagerElement(child.evalNode("transactionManager"));
// 创建DataSourceFactory和DataSource
DataSourceFactory dsFactory = dataSourceElement(child.evalNode("dataSource"));
DataSource dataSource = dsFactory.getDataSource();
// 创建Environment对象,封装了上面创建的TransactionFactory以及DataSource
// 这里使用了Builder模式
Environment.Builder environmentBuilder = new Environment.Builder(id).transactionFactory(txFactory)
.dataSource(dataSource);
configuration.setEnvironment(environmentBuilder.build());
break;
}
}
}
3.1.2.7 databaseIdProvider
MyBatis不能像Hibernate那样,直接帮助开发人员屏蔽多种数据库产品在SQL语言支持方面的差异。但是在mybatis-config.xml配置文件中,通过databaseIdProvider定义所有支持的数据库产品的databaseId,然后在映射配置文件中定义SQL语句节点时,通过databaseId指定该SQL语句应用的数据库产品,这样也可以实现类似的功能。
在MyBatis初始化时,会根据前面确定的DataSource确定当前使用的数据库产品,然后在解析映射配置文件时,加载不带databaseId属性和带有匹配当前数据库databaseId属性的所有SQL语句。如果同时找到带有databaseId和不带databaseId的相同语句,则后者会被舍弃,使用前者。databaseIdProviderElement方法负责解析databaseIdProvider节点,并创建指定的DatabaseIdProvider对象。DatabaseIdProvider会返回databaseId值,MyBatis会根据databaseId选择合适的SQL进行执行。
private void databaseIdProviderElement(XNode context) throws Exception {
if (context == null) {
return;
}
String type = context.getStringAttribute("type");
// 为了保证兼容性性,修改type取值
if ("VENDOR".equals(type)) {
type = "DB_VENDOR";
}
Properties properties = context.getChildrenAsProperties(); // 解析相关配置信息
// 创建DatabaseIdProvider对象
DatabaseIdProvider databaseIdProvider = (DatabaseIdProvider) resolveClass(type).getDeclaredConstructor()
.newInstance();
// 配置DatabaseIdProvider,完成初始化
databaseIdProvider.setProperties(properties);
Environment environment = configuration.getEnvironment();
if (environment != null) {
// 通过前面确定的DataSource获取databaseID,记录到Configuration的databaseId中
String databaseId = databaseIdProvider.getDatabaseId(environment.getDataSource());
configuration.setDatabaseId(databaseId);
}
}
MyBatis提供的DatabaseIdProvider接口及其实现比较简单。DatabaseIdProvider接口的核心方法是getDatabaseId方法,它主要负责通过给定的DataSource来查找对应的databaseId。MyBatis提供了VendorDatabaseIdProvider和DefaultDatabaseIdProvider两个实现,其中DefaultDatabaseIdProvider已过时
VendorDatabaseIdProvider.getDatabaseId方法在接收到DataSource对象时,会先解析DataSource所连接的数据库产品名称,之后根据databaseIdProvider节点配置的数据库产品名称与databaseId的对应关系确定最终的databaseId
private String getDatabaseName(DataSource dataSource) throws SQLException {
// 解析DataSource连接的数据库产品名称
String productName = getDatabaseProductName(dataSource);
if (this.properties != null) {
// 根据databaseIdProvider子结点配置的数据库产品和databaseId之间的对应关系,确定最终使用的databaseId
return properties.entrySet().stream().filter(entry -> productName.contains((String) entry.getKey()))
.map(entry -> (String) entry.getValue()).findFirst().orElse(null);
}
return productName;
}
private String getDatabaseProductName(DataSource dataSource) throws SQLException {
try (Connection con = dataSource.getConnection()) {
return con.getMetaData().getDatabaseProductName();
}
}
3.1.2.8 mappers
在MyBatis初始化时,除了加载mybatis-config.xml配置文件,还会加载全部的映射配置文件,mybatis-config.xml配置文件中的mappers节点会告诉MyBatis去哪些位置查找映射配置文件以及使用了配置注解标识的接口。mapperElement方法负责解析mappers节点,它会创建XMLMapperBuilder对象加载映射文件,如果映射配置文件存在相应的Mapper接口,也会加载相应的Mapper接口,解析其中的注解并完成向MapperRegistry的注册。
private void mappersElement(XNode context) throws Exception {
if (context == null) {
return;
}
for (XNode child : context.getChildren()) {
if ("package".equals(child.getName())) { // 处理package子结点
String mapperPackage = child.getStringAttribute("name");
// 扫描指定包,并想MapperRegistry注册Mapper接口
configuration.addMappers(mapperPackage);
} else {
// 获取mapper结点的resource、url、class属性,这三个属性互斥
String resource = child.getStringAttribute("resource");
String url = child.getStringAttribute("url");
String mapperClass = child.getStringAttribute("class");
// 如果mapper结点指定了resource或是url属性,啧创建XMLMapperBuilder对象
// 并通过该对象解析resource或是url指定的Mapper配置文件
if (resource != null && url == null && mapperClass == null) {
ErrorContext.instance().resource(resource);
try (InputStream inputStream = Resources.getResourceAsStream(resource)) {
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource,
configuration.getSqlFragments());
mapperParser.parse();
}
} else if (resource == null && url != null && mapperClass == null) {
ErrorContext.instance().resource(url);
try (InputStream inputStream = Resources.getUrlAsStream(url)) {
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url,
configuration.getSqlFragments());
mapperParser.parse();
}
} else if (resource == null && url == null && mapperClass != null) {
// 如果Mapper结点指定了class属性,则直接注册该Mapper接口
Class<?> mapperInterface = Resources.classForName(mapperClass);
configuration.addMapper(mapperInterface);
} else {
throw new BuilderException(
"A mapper element may only specify a url, resource or class, but not more than one.");
}
}
}
}
3.1.3 XMLMapperBuilder
XMLMapperBuilder负责解析映射配置文件,它继承了BaseBuilder抽象类,也是具体建造者的角色。XMLMapperBuilder.parse方法是解析映射文件的入口
public void parse() {
// 判断是否已经加载过该映射文件
if (!configuration.isResourceLoaded(resource)) {
configurationElement(parser.evalNode("/mapper")); // 处理mapper结点
// 将resource添加到configuration.loadedResource集合中保存, 记录了已经加载过的映射文件
configuration.addLoadedResource(resource);
bindMapperForNamespace(); // 注册mapper接口
}
// 处理configurationElement方法中解析失败的resultMap节点
configuration.parsePendingResultMaps(false);
// 处理configurationElement方法中解析失败的cache-ref节点
configuration.parsePendingCacheRefs(false);
// 处理configurationElement方法中解析失败的SQL语句节点
configuration.parsePendingStatements(false);
}
XMLMapperBuilder也是将每个节点的解析过程封装成了一个方法,而这些方法由XMLMapperBuilder.configurationElement方法调用
private void configurationElement(XNode context) {
try {
// 获取mapper节点的namespace属性
String namespace = context.getStringAttribute("namespace");
if (namespace == null || namespace.isEmpty()) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
// 设置MapperBuilderAssistant.currentNamespace字段,记录命名空间
builderAssistant.setCurrentNamespace(namespace);
// 解析每个节点
cacheRefElement(context.evalNode("cache-ref"));
cacheElement(context.evalNode("cache"));
// 这个节点已经废弃了, 不再推荐使用
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
resultMapElements(context.evalNodes("/mapper/resultMap"));
sqlElement(context.evalNodes("/mapper/sql"));
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e);
}
}
3.1.3.1 cache
MyBatis拥有非常强大的二级缓存功能,该功能可以非常方便地进行配置,MyBatis默认情况下没有开启二级缓存,如果要为某命名空间开启二级缓存功能,则需要在相应映射配置文件中添加cache节点,还可以通过配置cache节点的相关属性,为二级缓存配置相应的特性(本质上就是添加相应的装饰器)。cacheElement方法主要负责解析cache节点
private void cacheElement(XNode context) {
if (context != null) {
String type = context.getStringAttribute("type", "PERPETUAL");
// 通过TypeAliasRegistry查找type属性对应的Cache接口实现
Class<? extends Cache> typeClass = typeAliasRegistry.resolveAlias(type);
String eviction = context.getStringAttribute("eviction", "LRU");
// 解析eviction属性指定的Cache装饰器类型
Class<? extends Cache> evictionClass = typeAliasRegistry.resolveAlias(eviction);
Long flushInterval = context.getLongAttribute("flushInterval");
Integer size = context.getIntAttribute("size");
boolean readWrite = !context.getBooleanAttribute("readOnly", false);
boolean blocking = context.getBooleanAttribute("blocking", false);
// 获取cache节点下的子节点,将用于初始化二级缓存
Properties props = context.getChildrenAsProperties();
// 通过MapperBuilderAssistant创建Cache对象,并添加到Configuration.cache集合中保存
builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props);
}
}
MapperBuilderAssistant是一个辅助类,其useNewCache方法负责创建Cache对象,并将其添加到Configuration.caches集合中保存。Configuration中的caches字段是StrictMap类型的字段,它记录Cache的id(默认是映射文件的namespace)与Cache对象(二级缓存)之间的对应关系。StrictMap继承了HashMap,并在其基础上进行了少许修改,这里重点关注StrictMap.put方法,如果检测到重复的key则抛出异常,如果没有重复的key则添加key以及value,同时会根据key产生shortKey
public V put(String key, V value) {
if (containsKey(key)) { // 如果包含了该Key,直接抛异常
throw new IllegalArgumentException("...");
}
if (key.contains(".")) {
// 按照"."将key切分成数组,并将数组的最后一项作为shortKey
final String shortKey = getShortName(key);
if (super.get(shortKey) == null) {
super.put(shortKey, value);
} else {
// 如果该shortKey已经存在,则将value修改为Ambiguity对象
super.put(shortKey, (V) new Ambiguity(shortKey));
}
}
return super.put(key, value);
}
Ambiguity是StrictMap中定义的静态内部类,它表示的是存在二义性的键值对。 Ambiguity中使用subject字段记录了存在二义性的key,并提供了相应的getter方法,StrictMap.get方法会检测value是否存在以及value是否为Ambiguity类型对象,如果满足这两个条件中的任意一个,则抛出异常。
public V get(Object key) {
V value = super.get(key);
if (value == null) { // 如果key没有对应的value,报错
throw new IllegalArgumentException(name + " does not contain value for " + key);
}
if (value instanceof Ambiguity) { // 如果value是Ambiguity类型报错
throw new IllegalArgumentException(((Ambiguity) value).getSubject() + " is ambiguous in " + name
+ " (try using the full name including the namespace, or rename one of the entries)");
}
return value;
}
MapperBuilderAssistant.useNewCache:
public Cache useNewCache(Class<? extends Cache> typeClass, Class<? extends Cache> evictionClass, Long flushInterval,
Integer size, boolean readWrite, boolean blocking, Properties props) {
// 创建Cache,CacheBuilder是建造者
Cache cache = new CacheBuilder(currentNamespace).implementation(valueOrDefault(typeClass, PerpetualCache.class))
.addDecorator(valueOrDefault(evictionClass, LruCache.class)).clearInterval(flushInterval).size(size)
.readWrite(readWrite).blocking(blocking).properties(props).build();
// 将Cache对象添加到Configuration.caches集合中,其中会将cache的id作为key,cache本身作为value
configuration.addCache(cache);
currentCache = cache; // 记录当前命名空间使用的cache对象
return cache;
}
CacheBuilder是Cache的建造者,CacheBuilder中各个字段的含义如下
private final String id; // cache对象的唯一标识,一般对应映射文件的namespace
// cache接口的真正实现类,默认值是前面提到的PerpetualCache(2.9.2)
private Class<? extends Cache> implementation;
// 装饰器集合, 默认只包含LruCache.class(2.9.3.2)
private final List<Class<? extends Cache>> decorators;
// cache大小
private Integer size;
// 清理时间周期
private Long clearInterval;
// 是否可读写
private boolean readWrite;
// 其他配置信息
private Properties properties;
// 是否阻塞
private boolean blocking;
CacheBuilder中提供了很多设置属性的方法,对应于建造者中的建造方法,build方法根据CacheBuilder中上述字段的值创建Cache对象并添加合适的装饰器
public Cache build() {
// 设置上面提到的默认属性
setDefaultImplementations();
// 根据implementation指定的类型,通过反射获取参数类型为String的构造方法
// 并通过该构造方法创建对应的Cache对象
Cache cache = newBaseCacheInstance(implementation, id);
// 根据cache节点下配置的property信息,初始化Cache对象
setCacheProperties(cache);
// 检测cache对象的类型,如果是PerpetualCache类型,添加decorators集合的装饰器,
// 如果是自定义cache的实现,则不添加装饰器
if (PerpetualCache.class.equals(cache.getClass())) {
for (Class<? extends Cache> decorator : decorators) {
cache = newCacheDecoratorInstance(decorator, cache);
setCacheProperties(cache); // 配置cache对象的属性
}
// 添加mybatis中提供的标准装饰器
cache = setStandardDecorators(cache);
} else if (!LoggingCache.class.isAssignableFrom(cache.getClass())) {
// 如果不是LoggingCache的子类,添加LoggingCache的装饰器
cache = new LoggingCache(cache);
}
return cache;
}
setStandardDecorators方法会根据CacheBuilder中各个字段的值,为cache对象添加对应的装饰器
private Cache setStandardDecorators(Cache cache) {
try {
// 创建Cache对象对应的metaObject对象
MetaObject metaCache = SystemMetaObject.forObject(cache);
if (size != null && metaCache.hasSetter("size")) {
metaCache.setValue("size", size);
}
if (clearInterval != null) { // 检测是否指定了clearInterval字段
cache = new ScheduledCache(cache); // 添加ScheduledCache装饰器
((ScheduledCache) cache).setClearInterval(clearInterval);
}
if (readWrite) { // 是否只读
cache = new SerializedCache(cache); // 添加SerializedCache装饰器
}
cache = new LoggingCache(cache); // 添加LoggingCache和SynchronizedCache装饰器
cache = new SynchronizedCache(cache);
if (blocking) { //是否阻塞
cache = new BlockingCache(cache);
}
return cache;
} catch (Exception e) {
throw new CacheException("Error building standard cache decorators. Cause: " + e, e);
}
}
3.1.3.2 cache-ref
通过前面对cache节点解析过程的介绍我们知道,XMLMapperBuilder.cacheElement方法会为每个namespace创建一个对应的Cache对象,并在Configuration.caches集合中记录namespace与Cache对象之间的对应关系。如果我们希望多个namespace共用同一个二级缓存,即同一个Cache对象,则可以使用cache-ref节点进行配置。
XMLMapperBuilder.cacheRefElement方法负责解析cache-ref节点。Configuration.cacheRefMap集合,其中key是cache-ref节点所在的namespace,value是cache-ref节点的namespace属性所指定的namespace。也就是说,前者共用后者的Cache对象
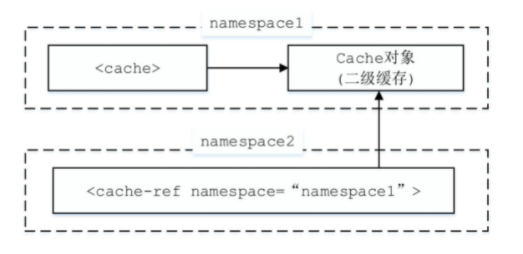
cacheRefElement方法的代码如下
private void cacheRefElement(XNode context) {
if (context != null) {
// 将当前Mapper配置文件的namespace与被引用的Cache所在的namespace之间的对应关系
// 记录到Configuration.cacheRefMap集合中
configuration.addCacheRef(builderAssistant.getCurrentNamespace(), context.getStringAttribute("namespace"));
// 创建CacheRefResolver对象
CacheRefResolver cacheRefResolver = new CacheRefResolver(builderAssistant,
context.getStringAttribute("namespace"));
try {
// 解析Cache引用,该估计欧辰主要是设置MapperBuilderAssistant中的currentCache和unresolvedCacheRef字段
cacheRefResolver.resolveCacheRef();
} catch (IncompleteElementException e) {
// 如果解析出现异常, 酒放到incompleteCacheRef,后面再处理
configuration.addIncompleteCacheRef(cacheRefResolver);
}
}
}
CacheRefResolver是一个简单的Cache引用解析器,其中封装了被引用的namespace以及当前XMLMapperBuilder对应的MapperBuilderAssistant对象。CacheRefResolver.resolveCacheRef方法会调用MapperBuilderAssistant.useCacheRef方法。在MapperBuilderAssistant.useCacheRef方法中会通过namespace查找被引用的Cache对象,具体实现如下
public Cache useCacheRef(String namespace) {
if (namespace == null) {
throw new BuilderException("cache-ref element requires a namespace attribute.");
}
try {
// 标识为未成功解析Cached引用
unresolvedCacheRef = true;
// 获取namespace对应的Cache对象
Cache cache = configuration.getCache(namespace);
if (cache == null) {
throw new IncompleteElementException("No cache for namespace '" + namespace + "' could be found.");
}
// 记录当前命名空间使用的Cache对象
currentCache = cache;
// 标识为成功解析了Cache引用
unresolvedCacheRef = false;
return cache;
} catch (IllegalArgumentException e) {
throw new IncompleteElementException("No cache for namespace '" + namespace + "' could be found.", e);
}
}
3.1.3.3 resultMap
select语句查询得到的结果集是一张二维表,水平方向上看是一个个字段,垂直方向上看是一条条记录。而Java是面向对象的程序设计语言,对象是根据类定义创建的,类之间的引用关系可以认为是嵌套的结构。在JDBC编程中,为了将结果集中的数据映射成对象,我们需要自己写代码从结果集中获取数据,然后封装成对应的对象并设置对象之间的关系,而这些都是大量的重复性代码。为了减少这些重复的代码,MyBatis使用resultMap节点定义了结果集与结果对象(JavaBean对象)之间的映射规则,resultMap节点可以满足绝大部分的映射需求,从而减少开发人员的重复性劳动,提高开发效率。
每个ResultMapping对象记录了结果集中的一列与JavaBean中一个属性之间的映射关系。在后面的分析过程中我们可以看到,resultMap节点下除了discriminator子节点的其他子节点,都会被解析成对应的ResultMapping对象。ResultMapping中的核心字段含义如下
private Configuration configuration; // Mybatis的全局配置对象
private String property; // 与该列进行映射的属性
private String column; // 从数据库中得到的列名或者是列名的别名
private Class<?> javaType; // JavaBean的完全限定名,或一个类型别名
private JdbcType jdbcType; // 进行映射的列的JDBC类型
private TypeHandler<?> typeHandler; // 类型处理器,会覆盖默认的类型处理器
// 对应节点的ResultMap属性,该属性通过id引用了另外一个resultMap节点定义,它负责将结果集的一部分
// 映射成其他关联的结果对象,这样我们就可以通过join进行关联查询,然后直接映射成多个对象
// 并同时设置这些对象的组合关系
private String nestedResultMapId;
// 对应节点的select属性,该属性通过id引用了另一个select节点定义,它会将指定的列的值传入
// select属性指定的select语句中作为参数进行查询
private String nestedQueryId;
private Set<String> notNullColumns; // 对应节点的nonNullColumn属性拆分后的结果
private String columnPrefix; // 表前缀
private List<ResultFlag> flags; // 处理后的标志,标志共两个:id和constructor
private List<ResultMapping> composites; // column属性拆分后的结果,composites.size > 0 会使column为null
private String resultSet;
private String foreignColumn;
private boolean lazy; // 是否延迟加载
每个resultMap节点都会被解析成一个ResultMap对象,其中每个节点所定义的映射关系,则使用ResultMapping对象表示
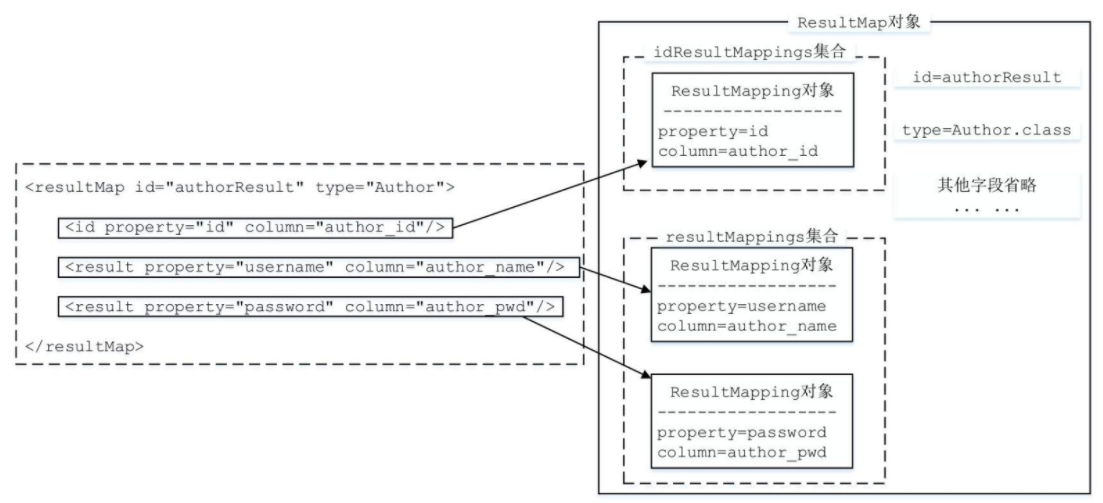
ResultMap中各个字段的含义如下
private Configuration configuration; // Mybatis全局配置对象
private String id; // resultMap节点的id属性
private Class<?> type; // resultMap节点的type属性
// 记录除了discriminator节点之外的其他映射关系
private List<ResultMapping> resultMappings;
// 记录了映射关系中带有ID标志的映射关系,列如id节点和constructor节点的idArgs子节点
private List<ResultMapping> idResultMappings;
// 记录了映射关系中带有Constructor标志的映射关系,列入constructor节点所有子元素
private List<ResultMapping> constructorResultMappings;
// 记录了映射关系中不带有Constructor标志的映射关系
private List<ResultMapping> propertyResultMappings;
private Set<String> mappedColumns; // 记录了所有映射关系中涉及的column属性的集合
private Set<String> mappedProperties;
// 鉴别器,对应discriminator节点
// discriminator相当于一个switch语句,能判断条件,然后返回相应的resultMap
private Discriminator discriminator;
private boolean hasNestedResultMaps; // 是否含有嵌套的结果映射,如果某个映射关系中存在resultMap属性,为true
private boolean hasNestedQueries; // 是否含有嵌套查询,如果某个属性映射中存在select属性,为true
private Boolean autoMapping; //是否开启自动映射
在XMLMapperBuilder中通过resultMapElements方法解析映射配置文件中的全部resultMap节点,该方法会循环调用resultMapElement方法处理每个resultMap节点
private ResultMap resultMapElement(XNode resultMapNode, List<ResultMapping> additionalResultMappings,
Class<?> enclosingType) {
ErrorContext.instance().activity("processing " + resultMapNode.getValueBasedIdentifier());
// resultType的属性, 表示结果集被映射的java对象
// getStringAttribute表示从XNode获取第一个参数的值, 如果没有就取第二个参数作为默认值
String type = resultMapNode.getStringAttribute("type",
resultMapNode.getStringAttribute("ofType",
resultMapNode.getStringAttribute("resultType", resultMapNode.getStringAttribute("javaType"))));
// 解析type类型
Class<?> typeClass = resolveClass(type);
if (typeClass == null) {
// 获取上一个标签的type
typeClass = inheritEnclosingType(resultMapNode, enclosingType);
}
Discriminator discriminator = null;
// 该集合用于记录解析的结果
List<ResultMapping> resultMappings = new ArrayList<>(additionalResultMappings);
// 处理resultMap的子节点
List<XNode> resultChildren = resultMapNode.getChildren();
for (XNode resultChild : resultChildren) {
if ("constructor".equals(resultChild.getName())) { // 处理constructor节点
processConstructorElement(resultChild, typeClass, resultMappings);
} else if ("discriminator".equals(resultChild.getName())) { // 处理discriminator节点
discriminator = processDiscriminatorElement(resultChild, typeClass, resultMappings);
} else {
// 处理id、result、association、collection节点
List<ResultFlag> flags = new ArrayList<>();
if ("id".equals(resultChild.getName())) {
flags.add(ResultFlag.ID);
}
// 创建ResultMapping对象,并添加到resultMapping集合中保存
resultMappings.add(buildResultMappingFromContext(resultChild, typeClass, flags));
}
}
String id = resultMapNode.getStringAttribute("id", resultMapNode.getValueBasedIdentifier());
String extend = resultMapNode.getStringAttribute("extends");
Boolean autoMapping = resultMapNode.getBooleanAttribute("autoMapping");
ResultMapResolver resultMapResolver = new ResultMapResolver(builderAssistant, id,
typeClass, extend, discriminator,
resultMappings, autoMapping);
try {
// 创建ResultMap对象,并添加到 Configuration.resultMaps集合中,该集合是StrictMap对象
return resultMapResolver.resolve();
} catch (IncompleteElementException e) {
configuration.addIncompleteResultMap(resultMapResolver);
throw e;
}
}
3.1.3.4 sql
在映射配置文件中,可以使用sql节点定义可重用的SQL语句片段。当需要重用sql节点中定义的SQL语句片段时,只需要使用include节点引入相应的片段即可,这样,在编写SQL语句以及维护这些SQL语句时,都会比较方便。XMLMapperBuilder.sqlElement方法负责解析映射配置文件中定义的全部<sql>节点
private void sqlElement(List<XNode> list, String requiredDatabaseId) {
for (XNode context : list) {
// 获取databaseId属性
String databaseId = context.getStringAttribute("databaseId");
// 获取id属性
String id = context.getStringAttribute("id");
// id属性加上namespace
id = builderAssistant.applyCurrentNamespace(id, false);
// 如果databaseId属性和当前databaseId一致,就添加到sqlFragments中
// sqlFragment指向了Configuration.sqlFragments集合
if (databaseIdMatchesCurrent(id, databaseId, requiredDatabaseId)) {
sqlFragments.put(id, context);
}
}
}
3.1.4 XMLStatementBuilder
映射配置文件中还有一类比较重要的节点需要解析,也就是SQL节点。这些SQL节点主要用于定义SQL语句,它们不再由XMLMapperBuilder进行解析,而是由 XMLStatementBuilder负责进行解析。MyBatis使用SqlSource接口表示映射文件或注解中定义的SQL语句,但它表示的SQL语句是不能直接被数据库执行的,因为其中可能含有动态SQL语句相关的节点或是占位符等需要解析的元素。SqlSource接口的定义如下:
public interface SqlSource {
// getBoundSql方法会根据映射文件中的内容或注解描述的SQL语句,以及传入的参数对象,返回可执行的SQL语句
BoundSql getBoundSql(Object parameterObject);
}
MyBatis使用MappedStatement表示映射配置文件中定义的SQL节点,MappedStatement包含了这些节点的很多属性,其中比较重要的字段如下:
private String resource; // 节点中的id属性 包括命名空间前缀
private SqlSource sqlSource; // sqlSource对象,对应一条sql语句
private SqlCommandType sqlCommandType; // sql语句的类型
XMLStatementBuilder.parseStatementNode方法是解析SQL节点的入口函数,其部分实现如下
public void parseStatementNode() {
// 获取SQL节点的id属性以及databaseId属性
String id = context.getStringAttribute("id");
String databaseId = context.getStringAttribute("databaseId");
// 判断是否匹配当前数据库, 若不匹配则不加载当前SQL节点
// 若存在相同id且数据库databaseId属性值不为空,则不再加载当前SQL节点
if (!databaseIdMatchesCurrent(id, databaseId, this.requiredDatabaseId)) {
return;
}
// 根据SQL节点的名称决定SQL语句的类型
String nodeName = context.getNode().getNodeName();
SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH));
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect);
boolean useCache = context.getBooleanAttribute("useCache", isSelect);
boolean resultOrdered = context.getBooleanAttribute("resultOrdered", false);
// 处理其中的include属性
XMLIncludeTransformer includeParser = new XMLIncludeTransformer(configuration, builderAssistant);
includeParser.applyIncludes(context.getNode());
// 后面核心的内容后面再说
}
3.1.4.1 include
在解析SQL节点之前,首先通过XMLIncludeTransformer解析SQL语句中的include节点,该过程会将include节点替换成sql节点中定义的SQL片段,并将其中的“${xxx}”占位符替换成真实的参数,该解析过程是在XMLIncludeTransformer.applyIncludes方法中实现的
public void applyIncludes(Node source) {
// 获取mybatis-config.xml中properties节点下定义的变量集合
Properties variablesContext = new Properties();
Properties configurationVariables = configuration.getVariables();
Optional.ofNullable(configurationVariables).ifPresent(variablesContext::putAll);
// 处理include节点
applyIncludes(source, variablesContext, false);
}
private void applyIncludes(Node source, final Properties variablesContext, boolean included) {
if ("include".equals(source.getNodeName())) { // (2) 处理include子节点
// 查找refid属性指向的sql节点,返回的是其深克隆的Node对象
Node toInclude = findSqlFragment(getStringAttribute(source, "refid"), variablesContext);
// 解析include节点下的property节点,将得到的键值对添加到variablesContext中,并形成新的Properties对象返回
// 用于替换占位符
Properties toIncludeContext = getVariablesContext(source, variablesContext);
// 递归处理include节点,再sql节点中可能有include节点引入了其他SQL片段
applyIncludes(toInclude, toIncludeContext, true);
if (toInclude.getOwnerDocument() != source.getOwnerDocument()) {
toInclude = source.getOwnerDocument().importNode(toInclude, true);
}
// 将include节点替换为被引用的SQL片段
source.getParentNode().replaceChild(toInclude, source);
while (toInclude.hasChildNodes()) { // 将sql节点的子节点添加到sql节点前面
toInclude.getParentNode().insertBefore(toInclude.getFirstChild(), toInclude);
}
toInclude.getParentNode().removeChild(toInclude); // 删除sql节点
} else if (source.getNodeType() == Node.ELEMENT_NODE) { // (1)
if (included && !variablesContext.isEmpty()) {
// replace variables in attribute values
NamedNodeMap attributes = source.getAttributes();
for (int i = 0; i < attributes.getLength(); i++) {
Node attr = attributes.item(i);
attr.setNodeValue(PropertyParser.parse(attr.getNodeValue(), variablesContext));
}
}
// 遍历子节点
NodeList children = source.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
applyIncludes(children.item(i), variablesContext, included);
}
} else if (included && (source.getNodeType() == Node.TEXT_NODE || source.getNodeType() == Node.CDATA_SECTION_NODE)
&& !variablesContext.isEmpty()) { // (3)
// 使用之前解析得到的Properties对象替换对应的占位符
source.setNodeValue(PropertyParser.parse(source.getNodeValue(), variablesContext));
}
}
例如有下面一个配置文件
<sql id="someinclude">
from ${tablename}
</sql>
<select id="countAll" resultType="int">
select
B.id as blog_id, B.title as blog_title, B.author_id as blog_author_id
<include refid="someinclude">
<property name="tablename" value="Blog">
</include>
</select>
我们从XMLStatementBuilder.applyIncludes 方法解析select节点开始分析,整个流程如图所示。首先第一层applyIncludes 方法调用中会执行(1)处代码,该处代码会递归调用applyIncludes方法处理select节点下的include子节点(refid="someinclude")。进入第二层applyIncludes方法调用继续执行,执行到(2)处代码,该代码段首先查找include节点引用的<sql id="someinclude">节点,注意这里得到toInclude对象(Node类型)是sql节点在Configuration.sqlFragments集合中对应Node对象的深克隆对象,然后获取include节点提供的属性值,即"tablename" -> "Blog",最后递归调用applyIncludes方法处理sql节点。进入第三层继续执行会执行到(2)处代码,递归调用applyIncludes方法处理sql节点的子节点。进入第四层继续处理,此时会执行到(3)处代码,该处代码段会将“from ${tablename}”解析成“from Blog”。之后开始递归的返回过程。
返回到第二层applyIncludes 方法调用时,首先会将include节点对应的Node对象替换为sql节点对应的Node对象(深度克隆对象),然后将sql节点的子节点(“from Blog”文本节点)添加到sql节点对应的Node对象之前,删除sql节点对应的Node对象。最后结束applyIncludes 方法的递归调用。
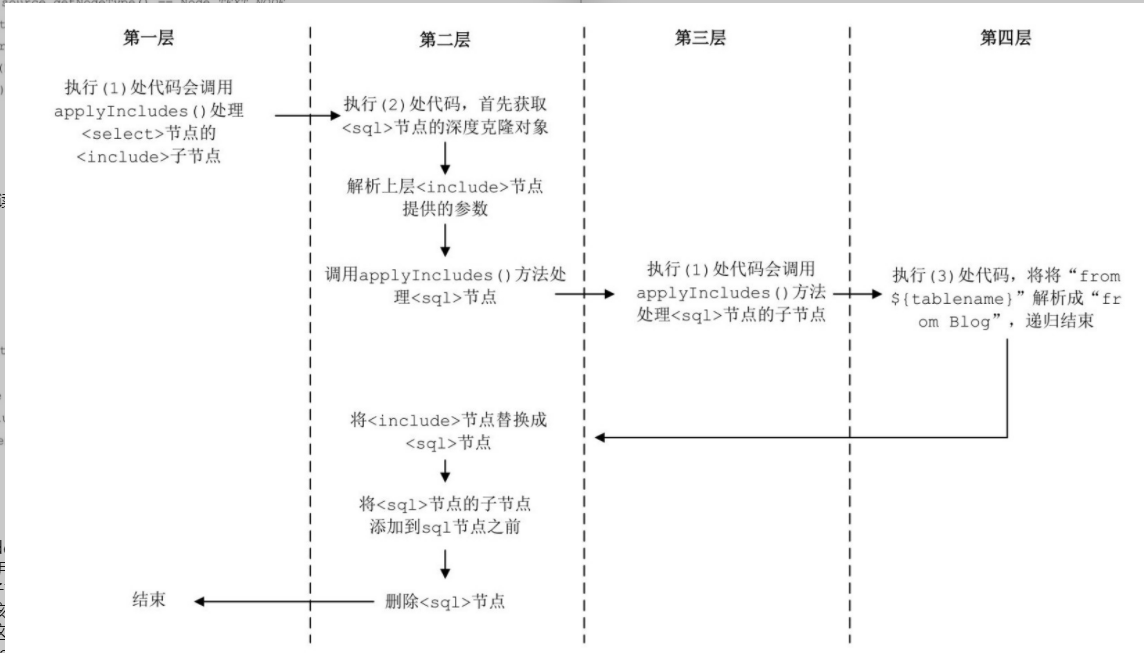
3.1.4.2 selectkey
在insert、update节点中可以定义selectKey节点来解决主键自增问题,selectKey节点对应的KeyGenerator接口在后面会详细介绍,现在重点关注selectKey节点的解析,XMLStatementBuilder.processSelectKeyNodes方法负责解析SQL节点中的selectKey子节点
private void processSelectKeyNodes(String id, Class<?> parameterTypeClass, LanguageDriver langDriver) {
// 获取全部的selectKey节点
List<XNode> selectKeyNodes = context.evalNodes("selectKey");
// 解析selectKey节点
if (configuration.getDatabaseId() != null) {
parseSelectKeyNodes(id, selectKeyNodes, parameterTypeClass, langDriver, configuration.getDatabaseId());
}
parseSelectKeyNodes(id, selectKeyNodes, parameterTypeClass, langDriver, null);
// 移除selectKey节点
removeSelectKeyNodes(selectKeyNodes);
}
在parseSelectKeyNodes方法中会为selectKey节点生成id,检测databaseId是否匹配以及是否已经加载过相同id且databaseId不为空的selectKey节点,并调用parseSelectKeyNode方法处理每个selectKey节点。
在parseSelectKeyNode方法中,首先读取selectKey节点的一系列属性,然后调用LanguageDriver.createSqlSource方法创建对应的SqlSource对象,最后创建MappedStatement对象,并添加到Configuration.mappedStatements集合中保存。parseSelectKeyNode方法的具体实现如下:
private void parseSelectKeyNode(String id, XNode nodeToHandle, Class<?> parameterTypeClass, LanguageDriver langDriver,
String databaseId) {
// 获取selectKey节点的resultType、statementType、keyProperty等属性
String resultType = nodeToHandle.getStringAttribute("resultType");
Class<?> resultTypeClass = resolveClass(resultType);
StatementType statementType = StatementType
.valueOf(nodeToHandle.getStringAttribute("statementType", StatementType.PREPARED.toString()));
String keyProperty = nodeToHandle.getStringAttribute("keyProperty");
String keyColumn = nodeToHandle.getStringAttribute("keyColumn");
boolean executeBefore = "BEFORE".equals(nodeToHandle.getStringAttribute("order", "AFTER"));
// defaults
boolean useCache = false;
boolean resultOrdered = false;
KeyGenerator keyGenerator = NoKeyGenerator.INSTANCE;
Integer fetchSize = null;
Integer timeout = null;
boolean flushCache = false;
String parameterMap = null;
String resultMap = null;
ResultSetType resultSetTypeEnum = null;
// 通过LangDriver.createSqlSource创建SqlSource
SqlSource sqlSource = langDriver.createSqlSource(configuration, nodeToHandle, parameterTypeClass);
// selectKey节点中只能配置SELECT语句
SqlCommandType sqlCommandType = SqlCommandType.SELECT;
// 通过MapperBuilderAssistant.创建MappedStatement对象,并添加到configuration.mappedStatements集合中保存
// 该集合为StrictMap类型
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType, fetchSize, timeout, parameterMap,
parameterTypeClass, resultMap, resultTypeClass, resultSetTypeEnum, flushCache, useCache, resultOrdered,
keyGenerator, keyProperty, keyColumn, databaseId, langDriver, null, false);
id = builderAssistant.applyCurrentNamespace(id, false);
MappedStatement keyStatement = configuration.getMappedStatement(id, false);
// 创建SelectKeyGenerator对象,并添加到configuration.keyGenerators集合中保存
configuration.addKeyGenerator(id, new SelectKeyGenerator(keyStatement, executeBefore));
}
LanguageDriver接口有两个实现类,默认使用的XMLLanguageDriver实现类,我们也可以提供自定义的LanguageDriver实现,并在mybatis-config.xml中通过defaultScriptingLanguage配置指定使用该自定义实现。
在XMLLanguageDriver.createSqlSource方法中会创建XMLScriptBuilder对象并调用XMLScriptBuilder.parseScriptNode方法创建SqlSource对象,该方法的代码如下
public SqlSource parseScriptNode() {
// 手写判断当前节点是否有动态SQL, 动态SQL会包括占位符或是动态SQL相关节点
MixedSqlNode rootSqlNode = parseDynamicTags(context);
SqlSource sqlSource;
if (isDynamic) {
sqlSource = new DynamicSqlSource(configuration, rootSqlNode);
} else {
sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType);
}
return sqlSource;
}
在XMLScriptBuilder.parseDynamicTags方法中,会遍历selectKey下的每个节点,如果包含任何标签节点,则认为是动态SQL语句;如果文本节点中含有“${}”占位符,也认为其为动态SQL语句。
protected MixedSqlNode parseDynamicTags(XNode node) {
List<SqlNode> contents = new ArrayList<>(); // 用于记录生成的SQLNode集合
NodeList children = node.getNode().getChildNodes(); // 获取SelectKey节点的所有子节点
for (int i = 0; i < children.getLength(); i++) {
// 创建XNode,该过程会将能解析掉的"${}"都解析掉
XNode child = node.newXNode(children.item(i));
if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE ||
child.getNode().getNodeType() == Node.TEXT_NODE) { // 对文本节点的处理
String data = child.getStringBody("");
TextSqlNode textSqlNode = new TextSqlNode(data);
// 解析SQL语句,如果有未解析的占位符,说明该节点是动态SQL
if (textSqlNode.isDynamic()) {
contents.add(textSqlNode);
isDynamic = true; // 标记为动态SQL
} else {
contents.add(new StaticTextSqlNode(data));
}
} else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) {
// 如果子节点是一个标签, 那么一定是一个动态SQL节点
// 根据不同的动态标签生成不同的NodeHandler
String nodeName = child.getNode().getNodeName();
NodeHandler handler = nodeHandlerMap.get(nodeName);
if (handler == null) {
throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");
}
// 处理动态SQL,并将解析得到的SQLNode对象放入contents中保存
handler.handleNode(child, contents);
isDynamic = true;
}
}
return new MixedSqlNode(contents);
}
3.1.4.3 sql
经过上述两个解析过程之后,include节点和selectKey节点已经被解析并删除掉了。XMLStatementBuilder.parseStatementNode方法剩余的操作就是解析SQL节点
KeyGenerator keyGenerator;
String keyStatementId = id + SelectKeyGenerator.SELECT_KEY_SUFFIX;
keyStatementId = builderAssistant.applyCurrentNamespace(keyStatementId, true);
// 检测SQL节点中是否配置了selectKey节点、SQL节点的useGeneratedKeys属性值
// mybatis-config.xml中全局的useGeneratedKeys配置,以及是否为insert语句,
// 决定KeyGenerator接口实现
if (configuration.hasKeyGenerator(keyStatementId)) {
keyGenerator = configuration.getKeyGenerator(keyStatementId);
} else {
keyGenerator = context.getBooleanAttribute("useGeneratedKeys",
configuration.isUseGeneratedKeys() && SqlCommandType.INSERT.equals(sqlCommandType))
? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE;
}
// 调用LanguageDriver创建SqlSource
SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
StatementType statementType = StatementType
.valueOf(context.getStringAttribute("statementType", StatementType.PREPARED.toString()));
Integer fetchSize = context.getIntAttribute("fetchSize");
Integer timeout = context.getIntAttribute("timeout");
String parameterMap = context.getStringAttribute("parameterMap");
String resultType = context.getStringAttribute("resultType");
Class<?> resultTypeClass = resolveClass(resultType);
String resultMap = context.getStringAttribute("resultMap");
if (resultTypeClass == null && resultMap == null) {
resultTypeClass = MapperAnnotationBuilder.getMethodReturnType(builderAssistant.getCurrentNamespace(), id);
}
String resultSetType = context.getStringAttribute("resultSetType");
ResultSetType resultSetTypeEnum = resolveResultSetType(resultSetType);
if (resultSetTypeEnum == null) {
resultSetTypeEnum = configuration.getDefaultResultSetType();
}
String keyProperty = context.getStringAttribute("keyProperty");
String keyColumn = context.getStringAttribute("keyColumn");
String resultSets = context.getStringAttribute("resultSets");
boolean dirtySelect = context.getBooleanAttribute("affectData", Boolean.FALSE);
// 通过MapperBuilderAssistant创建MappedStatement,并添加到Configuration.mappedStatements中
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType, fetchSize, timeout, parameterMap,
parameterTypeClass, resultMap, resultTypeClass, resultSetTypeEnum, flushCache,
useCache, resultOrdered,keyGenerator, keyProperty, keyColumn, databaseId,
langDriver, resultSets, dirtySelect);