

3 Netty入门
3.1 Netty概述
Netty 是一个异步的、基于事件驱动的网络应用框架,用于快速开发可维护、高性能的网络服务器和客户端
基于事件驱动:底层使用了Selector,多路复用
异步的:这里并不是指异步IO模型,只要指使用多线程,将调用结果和接收结果区分开来
Netty基于NIO,相比NIO,解决了以下问题
需要自己构建协议
解决 TCP 传输问题,如粘包、半包
epoll 空轮询导致 CPU 100%
对 API 进行增强,使之更易用,如 FastThreadLocal => ThreadLocal,ByteBuf => ByteBuffer
3.2 快速开始
加入依赖
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.39.Final</version>
</dependency>服务器端代码:
// ServerBootstrap服务端的启动器, 负责组装Netty组件, 启动服务器
new ServerBootstrap()
// BossEventLoopGroup, WorkerEventLoopGroup(Selector, thread)
.group(new NioEventLoopGroup())
// 选择服务器ServerSocketChannel实现
.channel(NioServerSocketChannel.class)
// childHandler: boss负责处理连接, worker负责处理读写, 决定了worker(child)能执行那些操作(handler)
// Channel: 客户端进行数据处理的通道, lInitializer: 初始化, 负责添加别的handler
.childHandler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ch.pipeline()
.addLast(new StringDecoder()) // 将ByteBuf转换成字符串
.addLast(new ChannelInboundHandlerAdapter() { // 添加自定义handler
@Override // 读事件
public void channelRead(ChannelHandlerContext ctx, Object msg) {
// 打印上一步转换好的字符串
log.info("receive msg: {}", msg);
}
});
}
})
// 绑定监听端口
.bind(8080);客户端代码:
// 创建客户端启动器
new Bootstrap()
// 添加EventLoop
.group(new NioEventLoopGroup())
// 选择客户端channel实现
.channel(NioSocketChannel.class)
// 添加处理器
.handler(new ChannelInitializer<NioSocketChannel>() {
@Override // 在连接建立后会调用
protected void initChannel(NioSocketChannel ch) {
ch.pipeline().addLast(new StringEncoder());
}
})
// 连接到服务器
.connect("127.0.0.1", 8080)
// 阻塞方法, 直到连接建立
.sync()
// 获取连接对象
.channel()
// 向服务器发送数据
.writeAndFlush("hello, world");3.3 Netty的组件
3.3.1 EventLoop
EventLoop 本质是一个单线程执行器(同时维护了一个 Selector),里面有 run 方法处理 Channel 上源源不断的 io 事件。
它的继承关系比较复杂
一条线是继承自 j.u.c.ScheduledExecutorService 因此包含了线程池中所有的方法
另一条线是继承自 netty 自己的 OrderedEventExecutor,提供了
boolean inEventLoop(Thread thread)方法判断一个线程是否属于此 EventLoop提供了parent方法来看看自己属于哪个 EventLoopGroup
EventLoopGroup 是一组 EventLoop,Channel 一般会调用 EventLoopGroup 的 register 方法来绑定其中一个 EventLoop,后续这个 Channel 上的 io 事件都由此 EventLoop 来处理(保证了 io 事件处理时的线程安全)
常用的EventLoopGroup有
NioEventLoopGroup:处理IO事件、普通任务、定时任务
DefaultEventLoopGroup:处理普通任务、定时任务
EventLoopGroup有一个参数的构造器,表示这个线程池有多少个线程,默认是当前CPU核心数 * 2
public NioEventLoopGroup() {
this(0);
}
// ...
protected MultithreadEventLoopGroup(int nThreads, Executor executor, Object... args) {
super(nThreads == 0 ? DEFAULT_EVENT_LOOP_THREADS : nThreads, executor, args);
}
private static final int DEFAULT_EVENT_LOOP_THREADS = Math.max(1, SystemPropertyUtil.getInt("io.netty.eventLoopThreads", NettyRuntime.availableProcessors() * 2));执行普通任务可以如下:
public void testNormalEventGroup() {
NioEventLoopGroup nioWorkers = new NioEventLoopGroup(2);
log.debug("server start...");
nioWorkers.execute(()->{
log.debug("normal task...");
});
}执行定时任务可以如下:
public void testCronEventGroup() {
NioEventLoopGroup nioWorkers = new NioEventLoopGroup(2);
// 参数1: Runnable, 执行的任务
// 参数2: 初始延迟时间, 延迟多久执行
// 参数3: 时间周期, 多久执行一次
// 参数4: 时间单位
nioWorkers.scheduleAtFixedRate(() -> {
log.debug("running...");
}, 0, 1, TimeUnit.SECONDS);
}处理IO事件可以类似于3.2
之前我们group用了一个参数,Boss和Worker都使用同一个NioEventLoopGroup,group还可以指定两个参数,第一个参数是Boss的NioEventLoopGroup(处理Accept事件),第二个参数是Worker的NioEventLoopGroup(处理读写事件)
new ServerBootstrap()
.group(new NioEventLoopGroup(), new NioEventLoopGroup())ChannelHandler也可以指定当前handler用的是哪一个eventGroup
EventLoopGroup group = new DefaultEventLoop();
new ServerBootstrap()
.group(new NioEventLoopGroup(), new NioEventLoopGroup())
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ch.pipeline().addLast(new ChannelInboundHandlerAdapter(){
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
ByteBuf buf = (ByteBuf) msg;
log.info(buf.toString(Charset.defaultCharset()));
// 这个方法表示交给下一个handler处理,如果不加会在这里直接结束
ctx.fireChannelRead(msg);
}
// 指定这个handler使用group线程来执行
}).addLast(group, new ChannelInboundHandlerAdapter(){
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
ByteBuf buf = (ByteBuf) msg;
log.info(buf.toString(Charset.defaultCharset()));
}
});
}
})
.bind(8080);hanler执行过程中,可能会涉及到不同EventLoop的切换,比如EventLoop1执行完之后,是怎么交给EventLoop2的呢?这里我们看一下源码
// ChannelInboundHandlerAdapter.java @Skip public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { ctx.fireChannelRead(msg); } // AbstractChannelHandlerContext.java public ChannelHandlerContext fireChannelRead(Object msg) { invokeChannelRead(this.findContextInbound(32), msg); return this; } static void invokeChannelRead(final AbstractChannelHandlerContext next, Object msg) { final Object m = next.pipeline.touch(ObjectUtil.checkNotNull(msg, "msg"), next); // 返回下一个handler的eventLoop EventExecutor executor = next.executor(); if (executor.inEventLoop()) { // 当前handler中的线程是否和eventLoop是同一个线程 next.invokeChannelRead(m); // 同一个线程,直接方法调用 } else { // 不是同一个线程 executor.execute(new Runnable() { // 将要执行低代码作为任务提交给下一个事件循环处理 public void run() { next.invokeChannelRead(m); } }); } }
3.3.2 Channel
channel 的主要方法有
close() 可以用来关闭 channel
closeFuture() 用来处理 channel 的关闭
sync 方法作用是同步等待 channel 关闭
而 addListener 方法是异步等待 channel 关闭
pipeline() 方法添加处理器
write() 方法将数据写入
writeAndFlush() 方法将数据写入并刷出
3.3.2.1 ChannelFuture
ChannelFuture channelFuture = new Bootstrap()
.group(new NioEventLoopGroup())
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer<Channel>() {
@Override
protected void initChannel(Channel ch) {
ch.pipeline().addLast(new StringEncoder());
}
})
.connect("127.0.0.1", 8080); // 1connect方法是异步非阻塞的,返回的是 ChannelFuture 对象,它的作用是利用 channel() 方法来获取 Channel 对象,由main方法发起了调用,真正执行的方法是NioEventLoop,onnect 方法是异步的,意味着不等连接建立,方法执行就返回了。因此 channelFuture 对象中不能立刻获得到正确的 Channel 对象。
System.out.println(channelFuture.channel()); // 1
channelFuture.sync(); // 2
System.out.println(channelFuture.channel()); // 3执行到 1 时,连接未建立,打印
[id: 0x2e1884dd]执行到 2 时,sync 方法是同步等待连接建立完成
执行到 3 时,连接肯定建立了,打印
[id: 0x2e1884dd, L:/127.0.0.1:57191 - R:/127.0.0.1:8080]
使用sync方法同步处理结果, 会阻塞在当前线程, 直到nio线程连接建立完毕
除了调用sync方法外,还可以使用addListener方法异步处理结果
channelFuture.addListener((ChannelFutureListener) channelFuture1 -> {
Channel channel = channelFuture1.channel();
channel.writeAndFlush("Hello, World");
});3.3.2.2 CloseFuture
我们如果想关闭channelFuture怎么操作呢
由于close方法是一个异步方法,因此跟channelFuture一样,channel也提供了CloseFuture来关闭线程,使用如下:
// 获取CloseFuture对象, 也是同步和异步两种
ChannelFuture closeFuture = channel.closeFuture();
closeFuture.sync();
log.debug("处理关闭之后的操作");
// closeFuture.addListener((ChannelFutureListener) future -> log.debug("处理关闭之后的操作"));在channel关闭后,我们还可以优雅地将整个线程关闭
NioEventLoopGroup group = new NioEventLoopGroup();
/* other code */
closeFuture.addListener((ChannelFutureListener) future -> {
log.debug("处理关闭之后的操作");
group.shutdownGracefully();
});3.3.3 Future & Promise
在异步处理时,经常用到这两个接口,netty中的 Future与 jdk 中的Future同名,但是是两个接口,netty的Future 继承自jdk的Future,而Promise又对netty Future进行了扩展
jdk Future 只能同步等待任务结束(或成功、或失败)才能得到结果
netty Future 可以同步等待任务结束得到结果,也可以异步方式得到结果,但都是要等任务结束
netty Promise 不仅有 netty Future 的功能,而且脱离了任务独立存在,只作为两个线程间传递结果的容器
3.3.3.1 Future的使用
@Slf4j
public class FeatureTest {
@Test
@SneakyThrows
public void testJDKFuture() {
ExecutorService service = Executors.newFixedThreadPool(2);
Future<Integer> future = service.submit(() -> {
Thread.sleep(1000);
log.info("call");
return 50;
});
Integer res = future.get();
log.info("res: {}", res);
}
@Test
@SneakyThrows
public void testNettyFuture() {
NioEventLoopGroup group = new NioEventLoopGroup();
EventLoop loop = group.next();
io.netty.util.concurrent.Future<Integer> future = loop.submit(() -> {
Thread.sleep(1000);
log.info("call");
return 50;
});
// 方法1: 添加监听器
future.addListener(f -> {
log.info("res: {}", f.getNow());
});
// 方法2: 阻塞等待
// log.info("res: {}", future.get());
}
}3.3.3.2 Promise使用
@Slf4j
public class PromiseTest {
@SneakyThrows
public static void main(String[] args) {
NioEventLoopGroup group = new NioEventLoopGroup();
EventLoop loop = group.next();
DefaultPromise<Integer> promise = new DefaultPromise<>(loop);
new Thread(() -> {
try {
log.info("start compute");
Thread.sleep(1000);
// 主动 设置结果
promise.setSuccess(100);
} catch (InterruptedException e) {
// 主动 设置失败
log.error("error", e);
promise.setFailure(e);
}
}).start();
// receive result
promise.addListener(future -> {
if (future.isSuccess()) {
log.info("result: {}", future.getNow());
} else {
log.error("error", future.cause());
}
});
}
}3.3.4 Handler & Pipeline
ChannelHandler 用来处理 Channel 上的各种事件,分为入站、出站两种。所有 ChannelHandler 被连成一串,就是 Pipeline
入站处理器通常是 ChannelInboundHandlerAdapter 的子类,主要用来读取客户端数据,写回结果
出站处理器通常是 ChannelOutboundHandlerAdapter 的子类,主要对写回结果进行加工
public static void main(String[] args) {
new ServerBootstrap()
.group(new NioEventLoopGroup())
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
// 通过channel拿到pipeline
ChannelPipeline pipeline = ch.pipeline();
// 添加处理器
// Netty默认会有两个Handler HeadHandler和TailHandler
// 因此添加的Handler会插在TailHandler之前, 并不是真正加在末尾
pipeline.addLast("h1", new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.debug("h1: {}", msg);
super.channelRead(ctx, msg);
// 模拟服务端向客户端发送数据, 以便h2处理器可以进行处理
ch.writeAndFlush(ctx.alloc().buffer().writeBytes("server".getBytes()));
}
});
pipeline.addLast("h2", new ChannelOutboundHandlerAdapter() {
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
log.debug("h2: {}", msg);
super.write(ctx, msg, promise);
}
});
}
})
.bind(8080);
}ChannelInboundHandlerAdapter 是按照 addLast 的顺序执行的,而 ChannelOutboundHandlerAdapter 是按照 addLast 的逆序执行的。ChannelPipeline 的实现是一个 ChannelHandlerContext(包装了 ChannelHandler) 组成的双向链表

入站处理器中,ctx.fireChannelRead(msg) 是 调用下一个入站处理器
ctx.channel().write(msg) 会 从尾部开始触发 后续出站处理器的执行
类似的,出站处理器中,ctx.write(msg, promise) 的调用也会 触发上一个出站处理器
如果不调用ctx.fireChannelRead,那么相当于链断开,就不会执行后续的处理器了
ctx.channel().write(msg) 和 ctx.write(msg)的区别
都是触发出站处理器的执行
ctx.channel().write(msg) 从尾部开始查找出站处理器
ctx.write(msg) 是从当前节点找上一个出站处理器
3.3.5 ByteBuf
ByteBuf是对NIO中ByteBuffer的增强,它可以实现自动扩容等功能
3.3.5.1 创建默认的ByteBuf
ByteBufAllocator.DEFAULT.buffer()可以创建一个默认的 ByteBuf(池化基于直接内存的 ByteBuf),初始容量是256,也可以通过构造函数指定初始容量
@Test
public void test1() {
ByteBuf buf = ByteBufAllocator.DEFAULT.buffer();
log.info("buf.capacity: {}", buf.capacity()); // 256
StringBuilder sb = new StringBuilder();
sb.append("a".repeat(300));
buf.writeBytes(sb.toString().getBytes());
log.info("buf.capacity: {}", buf.capacity()); // 512
}扩容规则是
如何写入后数据大小未超过 512,则选择下一个 16 的整数倍,例如写入后大小为 12 ,则扩容后 capacity 是 16
如果写入后数据大小超过 512,则选择下一个 2n,例如写入后大小为 513,则扩容后 capacity 是 210=1024(29=512 已经不够了)
扩容不能超过 max capacity (Integer.MAX_VALUE)会报错
ByteBuf示意图如下:
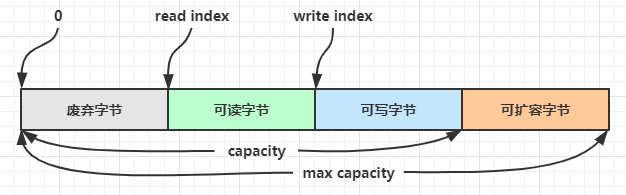
可以看到ByteBuf读写指针分离,不需要像 ByteBuffer 一样切换读写模式
3.3.5.2 直接内存 vs 堆内存
可以使用下面的代码来创建池化基于堆的 ByteBuf
ByteBuf buffer = ByteBufAllocator.DEFAULT.heapBuffer(10);也可以使用下面的代码来创建池化基于直接内存的 ByteBuf
ByteBuf buffer = ByteBufAllocator.DEFAULT.directBuffer(10);直接内存创建和销毁的代价昂贵,但读写性能高(少一次内存复制),适合配合池化功能一起用
直接内存对 GC 压力小,因为这部分内存不受 JVM 垃圾回收的管理,但也要注意及时主动释放
3.3.5.3 池化 vs 非池化
池化的最大意义在于可以重用 ByteBuf,优点有
没有池化,则每次都得创建新的 ByteBuf 实例,这个操作对直接内存代价昂贵,就算是堆内存,也会增加 GC 压力
有了池化,则可以重用池中 ByteBuf 实例,并且采用了与 jemalloc 类似的内存分配算法提升分配效率
高并发时,池化功能更节约内存,减少内存溢出的可能
池化功能是否开启,可以通过下面的系统环境变量来设置
-Dio.netty.allocator.type={unpooled|pooled}3.3.5.4 ByteBuf写入
3.3.5.5 retain & release
由于 Netty 中有堆外内存的 ByteBuf 实现,堆外内存最好是手动来释放,而不是等 GC 垃圾回收。
UnpooledHeapByteBuf 使用的是 JVM 内存,只需等 GC 回收内存即可
UnpooledDirectByteBuf 使用的就是直接内存了,需要特殊的方法来回收内存
PooledByteBuf 和它的子类使用了池化机制,需要更复杂的规则来回收内存
Netty 这里采用了引用计数法来控制回收内存,每个 ByteBuf 都实现了 ReferenceCounted 接口
每个 ByteBuf 对象的初始计数为 1
调用 release 方法计数减 1,如果计数为 0,ByteBuf 内存被回收
调用 retain 方法计数加 1,表示调用者没用完之前,其它 handler 即使调用了 release 也不会造成回收
当计数为 0 时,底层内存会被回收,这时即使 ByteBuf 对象还在,其各个方法均无法正常使用
因为 pipeline 的存在,一般需要将 ByteBuf 传递给下一个 ChannelHandler,如果在 finally 中 release 了,就失去了传递性(当然,如果在这个 ChannelHandler 内这个 ByteBuf 已完成了它的使命,那么便无须再传递)
基本规则是,谁是最后使用者,谁负责 release,详细分析如下
起点,对于 NIO 实现来讲,在 io.netty.channel.nio.AbstractNioByteChannel.NioByteUnsafe#read 方法中首次创建 ByteBuf 放入 pipeline(line 163 pipeline.fireChannelRead(byteBuf))
入站 ByteBuf 处理原则
对原始 ByteBuf 不做处理,调用 ctx.fireChannelRead(msg) 向后传递,这时无须 release
将原始 ByteBuf 转换为其它类型的 Java 对象,这时 ByteBuf 就没用了,必须 release
如果不调用 ctx.fireChannelRead(msg) 向后传递,那么也必须 release
注意各种异常,如果 ByteBuf 没有成功传递到下一个 ChannelHandler,必须 release
假设消息一直向后传,那么 TailContext 会负责释放未处理消息(原始的 ByteBuf)
出站 ByteBuf 处理原则
出站消息最终都会转为 ByteBuf 输出,一直向前传,由 HeadContext flush 后 release
异常处理原则
有时候不清楚 ByteBuf 被引用了多少次,但又必须彻底释放,可以循环调用 release 直到返回 true
之前我们提到过,Netty里面会有两个默认的HeadHandler和TailHandler,如果消息没人处理,就会掉用ByteBuf的release方法
// TailContext#onUnhandledInboundMessage
protected void onUnhandledInboundMessage(Object msg) {
try {
logger.debug("Discarded inbound message {} that reached at the tail of the pipeline. Please check your pipeline configuration.", msg);
} finally {
ReferenceCountUtil.release(msg);
}
}
// HeadContext#write
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) {
this.unsafe.write(msg, promise);
}// ReferenceCountUtil#release
public static boolean release(Object msg) {
return msg instanceof ReferenceCounted ? ((ReferenceCounted)msg).release() : false;
}// AbstractUnsafe#write
public final void write(Object msg, ChannelPromise promise) {
this.assertEventLoop();
ChannelOutboundBuffer outboundBuffer = this.outboundBuffer;
if (outboundBuffer == null) {
try {
ReferenceCountUtil.release(msg);
} finally {
this.safeSetFailure(promise, this.newClosedChannelException(AbstractChannel.this.initialCloseCause, "write(Object, ChannelPromise)"));
}
} else {
int size;
try {
msg = AbstractChannel.this.filterOutboundMessage(msg);
size = AbstractChannel.this.pipeline.estimatorHandle().size(msg);
if (size < 0) {
size = 0;
}
} catch (Throwable var15) {
try {
ReferenceCountUtil.release(msg);
} finally {
this.safeSetFailure(promise, var15);
}
return;
}
outboundBuffer.addMessage(msg, size, promise);
}
}但我们不能仅仅依靠Netty提供的头尾Handler来保证ByteBuf的释放,因为假如你在中间过程中处理消息了,那么头尾得到的就不是原来的ByteBuf了,也就无法帮你进行释放了。
3.3.5.6 slice切片
零拷贝的体现之一,对原始 ByteBuf 进行切片成多个 ByteBuf,切片后的 ByteBuf 并没有发生内存复制,还是使用原始 ByteBuf 的内存,切片后的 ByteBuf 维护独立的 read,write 指针
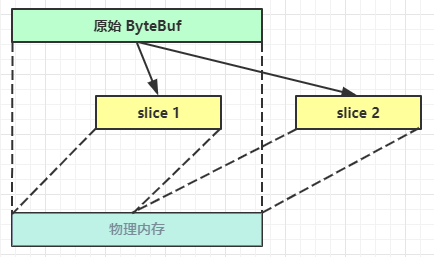
注意点:
切片后的ByteBuf的最大容量跟切片的长度是一样的,因为使用的是原始的物理内存,因此为了不影响其他的切片,会限制最大长度
当原始的ByteBuf调用release方法,会让引用计数-1,会导致切片出现问题,因此切片后需要执行retain方法,让切片后的引用计数自己来维护
3.3.5.7 duplicate复制
零拷贝的体现之一,就好比截取了原始 ByteBuf 所有内容,并且没有 max capacity 的限制,也是与原始 ByteBuf 使用同一块底层内存,只是读写指针是独立的
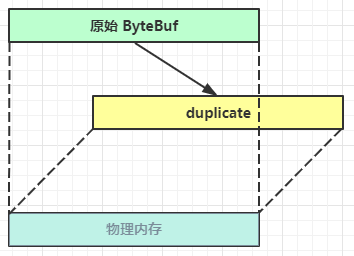
3.3.5.8 copy复制
会将底层内存数据进行深拷贝,因此无论读写,都与原始 ByteBuf 无关,注意与duplicated 区别
3.3.5.9 CompositeByteBuf合并
零拷贝的体现之一,可以将多个 ByteBuf 合并为一个逻辑上的 ByteBuf,避免拷贝
@Test
public void test3() {
ByteBuf buf1 = ByteBufAllocator.DEFAULT.buffer();
buf1.writeBytes(new byte[]{1, 2, 3, 4});
ByteBuf buf2 = ByteBufAllocator.DEFAULT.buffer();
buf1.writeBytes(new byte[]{5, 6, 7, 8, 9});
CompositeByteBuf buffer = ByteBufAllocator.DEFAULT.compositeBuffer();
buffer.addComponent(true, buf1);
log.info("buf: {}", ByteBufUtil.hexDump(buffer));
}CompositeByteBuf 是一个组合的 ByteBuf,它内部维护了一个 Component 数组,每个 Component 管理一个 ByteBuf,记录了这个 ByteBuf 相对于整体偏移量等信息,代表着整体中某一段的数据。
优点,对外是一个虚拟视图,组合这些 ByteBuf 不会产生内存复制
缺点,复杂了很多,多次操作会带来性能的损耗
4 Netty进阶
4.1 粘包与半包
4.1.1 滑动窗口
TCP 以一个段(segment)为单位,每发送一个段就需要进行一次确认应答(ack)处理,但如果这么做,缺点是包的往返时间越长性能就越差
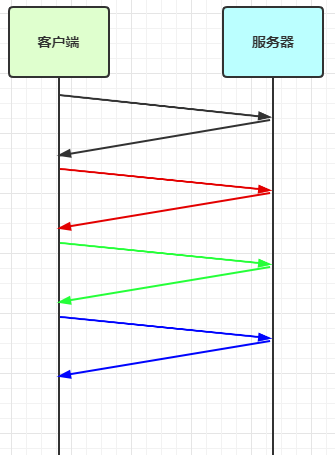
为了解决此问题,引入了窗口概念,窗口大小即决定了无需等待应答而可以继续发送的数据最大值
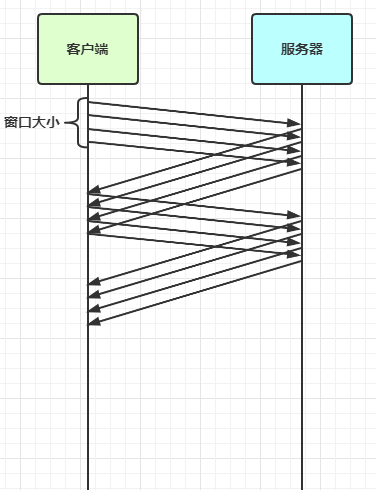
窗口实际就起到一个缓冲区的作用,同时也能起到流量控制的作用
图中深色的部分即要发送的数据,高亮的部分即窗口
窗口内的数据才允许被发送,当应答未到达前,窗口必须停止滑动
如果 1001~2000 这个段的数据 ack 回来了,窗口就可以向前滑动
接收方也会维护一个窗口,只有落在窗口内的数据才能允许接收
4.1.2 粘包
现象,发送 abc def,接收 abcdef
ch.pipeline().addLast(new LoggingHandler(LogLevel.DEBUG))
.addLast(new ChannelInboundHandlerAdapter() {
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
for (int i = 0; i < 10; i++) {
ByteBuf buf = ctx.alloc().buffer(16);
buf.writeBytes(new byte[]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15});
ctx.writeAndFlush(buf);
}
}
});服务端:
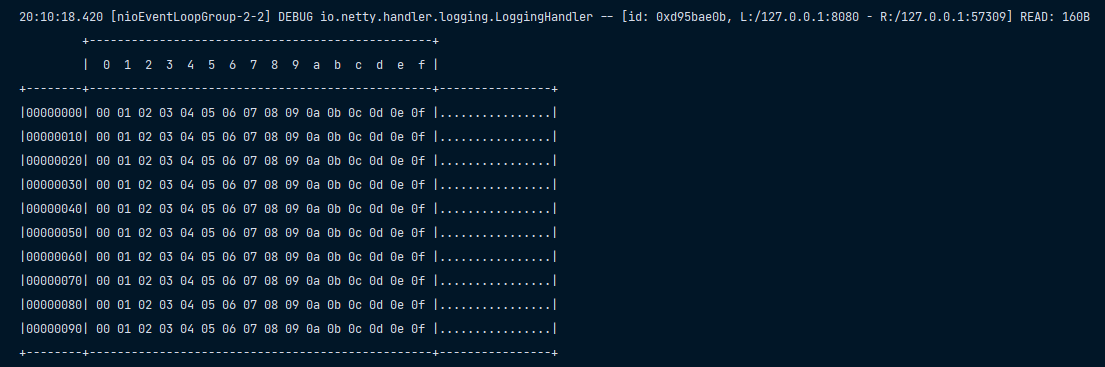
原因
应用层:接收方 ByteBuf 设置太大(Netty 默认 1024)
滑动窗口:假设发送方 256 bytes 表示一个完整报文,但由于接收方处理不及时且窗口大小足够大,这 256 bytes 字节就会缓冲在接收方的滑动窗口中,当滑动窗口中缓冲了多个报文就会粘包
Nagle 算法:会造成粘包
Nagle 算法
即使发送一个字节,也需要加入 tcp 头和 ip 头,也就是总字节数会使用 41 bytes,非常不经济。因此为了提高网络利用率,tcp 希望尽可能发送足够大的数据,这就是 Nagle 算法产生的缘由
该算法是指发送端即使还有应该发送的数据,但如果这部分数据很少的话,则进行延迟发送
如果 SO_SNDBUF 的数据达到 MSS,则需要发送
如果 SO_SNDBUF 中含有 FIN(表示需要连接关闭)这时将剩余数据发送,再关闭
如果 TCP_NODELAY = true,则需要发送
已发送的数据都收到 ack 时,则需要发送
上述条件不满足,但发生超时(一般为 200ms)则需要发送
除上述情况,延迟发送
4.1.3 半包
现象,发送 abcdef,接收 abc def
客户端:
ByteBuf buffer = ctx.alloc().buffer();
for (int i = 0; i < 10; i++) {
buffer.writeBytes(new byte[]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15});
}
ctx.writeAndFlush(buffer);为现象明显,服务端修改一下接收缓冲区,其它代码不变:
serverBootstrap.option(ChannelOption.SO_RCVBUF, 10);原因
应用层:接收方 ByteBuf 小于实际发送数据量
滑动窗口:假设接收方的窗口只剩了 128 bytes,发送方的报文大小是 256 bytes,这时放不下了,只能先发送前 128 bytes,等待 ack 后才能发送剩余部分,这就造成了半包
MSS 限制:当发送的数据超过 MSS 限制后,会将数据切分发送,就会造成半包
4.1.4 解决方案
4.1.4.1 短链接
短链接,发一个包建立一次连接,这样连接建立到连接断开之间就是消息的边界,缺点效率太低
短链接只能解决粘包问题,不能解决半包问题。
ch.pipeline().addLast(new LoggingHandler(LogLevel.DEBUG))
.addLast(new ChannelInboundHandlerAdapter() {
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
ByteBuf buffer = ctx.alloc().buffer();
buffer.writeBytes(new byte[]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15});
ctx.writeAndFlush(buffer);
// 发一次就关闭
ctx.channel().close();
}
});4.1.4.2 固定长度
让所有数据包长度固定(假设长度为 8 字节),服务器端加入
ch.pipeline().addLast(new FixedLengthFrameDecoder(8));缺点是,数据包的大小不好把握
长度定的太大,浪费
长度定的太小,对某些数据包又显得不够
4.1.4.3 固定分隔符
服务端加入,默认以 \n 或 \r\n 作为分隔符,如果超出指定长度仍未出现分隔符,则抛出异常
ch.pipeline().addLast(new LineBasedFrameDecoder(1024));缺点,处理字符数据比较合适,但如果内容本身包含了分隔符(字节数据常常会有此情况),那么就会解析错误
4.1.4.4 预设长度(LTC解码器)
在发送消息前,先约定用定长字节表示接下来数据的长度
ch.pipeline().addLast(new LengthFieldBasedFrameDecoder(
maxFrameLength, lengthFieldOffset, lengthFieldLength, lengthAdjustment, initialBytesToStrip));maxFrameLength:最大长度
lengthFieldOffset:长度字段的偏移亮(从第几个字符开始取Content-Length)
lengthFieldLength:请求头中标明请求体字符数的 长度(用多少个字符来表示我的Content-Length)
lengthAdjustment:长度字段为基准,还有几个字节是内容(Content-Length后多少个字符开始计算请求体)
initialBytesToStrip:跳过开始的多少字节内容
4.2 协议设计
协议设计一般包括下面的元素:
魔数,用来在第一时间判定是否是无效数据包
版本号,可以支持协议的升级
序列化算法,消息正文到底采用哪种序列化反序列化方式,可以由此扩展,例如:json、protobuf、hessian、jdk
指令类型,是登录、注册、单聊、群聊... 跟业务相关
请求序号,为了双工通信,提供异步能力
正文长度
消息正文
@Slf4j
public class MessageCodec extends ByteToMessageCodec<Message> {
@Override
public void encode(ChannelHandlerContext ctx, Message message, ByteBuf out) {
// 4字节的魔数
out.writeInt(Constants.MAGIC_NUMBER);
// 1字节的版本
out.writeByte(Constants.VERSION);
// 1字节的序列化方式 0 JDK,1 json
out.writeByte(Constants.SERIALIZER_CODE);
// 1字节的指令类型
out.writeByte(message.getMessageType().getType());
// 4字节的指令请求序号
out.writeInt(message.getSequenceId());
// 1字节的填充位
out.writeByte(0xff);
byte[] serialize = JDKSerializer.serialize(message);
// 4字节的序列化长度
out.writeInt(serialize.length);
// 序列化后的数据
out.writeBytes(serialize);
}
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> list) {
int magicNumber = in.readInt();
byte version = in.readByte();
byte serializerCode = in.readByte();
byte messageType = in.readByte();
int sequenceId = in.readInt();
in.readByte();
int length = in.readInt();
byte[] bytes = new byte[length];
in.readBytes(bytes, 0, length);
Message res = (Message) JDKSerializer.deserialize(bytes);
list.add(res);
log.info("magicNumber:{},version:{},serializerCode:{},messageType:{},sequenceId:{},length:{}",
magicNumber, version, serializerCode, messageType, sequenceId, length);
log.info("message:{}", res);
}
}
当 handler 不保存状态时,就可以安全地在多线程下被共享
但要注意对于编解码器类,不能继承 ByteToMessageCodec 或 CombinedChannelDuplexHandler 父类,他们的构造方法对 @Sharable 有限制
如果能确保编解码器不会保存状态,可以继承 MessageToMessageCodec 父类
4.3 连接假死
原因
网络设备出现故障,例如网卡,机房等,底层的 TCP 连接已经断开了,但应用程序没有感知到,仍然占用着资源。
公网网络不稳定,出现丢包。如果连续出现丢包,这时现象就是客户端数据发不出去,服务端也一直收不到数据,就这么一直耗着
应用程序线程阻塞,无法进行数据读写
问题
假死的连接占用的资源不能自动释放
向假死的连接发送数据,得到的反馈是发送超时
服务器端解决
怎么判断客户端连接是否假死呢?如果能收到客户端数据,说明没有假死。因此策略就可以定为,每隔一段时间就检查这段时间内是否接收到客户端数据,没有就可以判定为连接假死
// 用来判断是不是 读空闲时间过长,或 写空闲时间过长
// 5s 内如果没有收到 channel 的数据,会触发一个 IdleState#READER_IDLE 事件
ch.pipeline().addLast(new IdleStateHandler(5, 0, 0));
// ChannelDuplexHandler 可以同时作为入站和出站处理器
ch.pipeline().addLast(new ChannelDuplexHandler() {
// 用来触发特殊事件
@Override
public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception{
IdleStateEvent event = (IdleStateEvent) evt;
// 触发了读空闲事件
if (event.state() == IdleState.READER_IDLE) {
log.debug("已经 5s 没有读到数据了");
ctx.channel().close();
}
}
});客户端定时心跳
客户端可以定时向服务器端发送数据,只要这个时间间隔小于服务器定义的空闲检测的时间间隔,那么就能防止前面提到的误判,客户端可以定义如下心跳处理器
// 用来判断是不是 读空闲时间过长,或 写空闲时间过长
// 3s 内如果没有向服务器写数据,会触发一个 IdleState#WRITER_IDLE 事件
ch.pipeline().addLast(new IdleStateHandler(0, 3, 0));
// ChannelDuplexHandler 可以同时作为入站和出站处理器
ch.pipeline().addLast(new ChannelDuplexHandler() {
// 用来触发特殊事件
@Override
public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception{
IdleStateEvent event = (IdleStateEvent) evt;
// 触发了写空闲事件
if (event.state() == IdleState.WRITER_IDLE) {
// log.debug("3s 没有写数据了,发送一个心跳包");
ctx.writeAndFlush(new PingMessage());
}
}
});5 Netty优化和源码
5.1 Netty优化
5.1.1 扩展序列化算法
序列化,反序列化主要用在消息正文的转换上
序列化时,需要将 Java 对象变为要传输的数据(可以是 byte[],或 json 等,最终都需要变成 byte[])
反序列化时,需要将传入的正文数据还原成 Java 对象,便于处理
例如:JDK的序列化
public class JDKSerializer implements Serializer {
@Override
public static <T> byte[] serialize(T obj) {
try (
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
) {
oos.writeObject(obj);
return bos.toByteArray();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Override
public static <T> T deserialize(Class<T> clazz, byte[] bytes) {
try (
ByteArrayInputStream bis = new ByteArrayInputStream(bytes);
ObjectInputStream ois = new ObjectInputStream(bis);
){
return (T) ois.readObject();
} catch (IOException | ClassNotFoundException e) {
throw new RuntimeException(e);
}
}
}基于GSON的序列化:
public class JSONSerializer implements Serializer {
@Override
public static <T> byte[] serialize(T obj) {
return new Gson().toJson(object).getBytes(StandardCharsets.UTF_8);
}
@Override
public static <T> T deserialize(Class<T> clazz, byte[] bytes) {
return new Gson().fromJson(new String(bytes, StandardCharsets.UTF_8), clazz);
}
}5.1.2 参数调优
5.1.2.1 CONNECT_TIMEOUT_MILLIS
属于 SocketChannal 参数
用在客户端建立连接时,如果在指定毫秒内无法连接,会抛出 timeout 异常
SO_TIMEOUT 主要用在阻塞 IO,阻塞 IO 中 accept,read 等都是无限等待的,如果不希望永远阻塞,使用它调整超时时间
使用:
bootstrap.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, 1000)源码:
// io.netty.channel.nio.AbstractNioChannel.AbstractNioUnsafe#connect
public final void connect(
final SocketAddress remoteAddress, final SocketAddress localAddress, final ChannelPromise promise) {
// ...
// Schedule connect timeout.
int connectTimeoutMillis = config().getConnectTimeoutMillis();
if (connectTimeoutMillis > 0) {
connectTimeoutFuture = eventLoop().schedule(new Runnable() {
@Override
public void run() {
ChannelPromise connectPromise = AbstractNioChannel.this.connectPromise;
ConnectTimeoutException cause =
new ConnectTimeoutException("connection timed out: " + remoteAddress); // 断点2
if (connectPromise != null && connectPromise.tryFailure(cause)) {
close(voidPromise());
}
}
}, connectTimeoutMillis, TimeUnit.MILLISECONDS);
}
// ...
}5.1.2.2 SO_BACKLOG
SO_BACKLOG属于 ServerSocketChannal 参数
回顾一下三次握手
第一次握手,client 发送 SYN 到 server,状态修改为 SYN_SEND,server 收到,状态改变为 SYN_REVD,并将该请求放入 sync queue 队列
第二次握手,server 回复 SYN + ACK 给 client,client 收到,状态改变为 ESTABLISHED,并发送 ACK 给 server
第三次握手,server 收到 ACK,状态改变为 ESTABLISHED,将该请求从 sync queue 放入 accept queue
在 linux 2.2 之前,backlog 大小包括了两个队列的大小,在 2.2 之后,分别用下面两个参数来控制
sync queue - 半连接队列:大小通过 /proc/sys/net/ipv4/tcp_max_syn_backlog 指定,在
syncookies启用的情况下,逻辑上没有最大值限制,这个设置便被忽略accept queue - 全连接队列:其大小通过 /proc/sys/net/core/somaxconn 指定,在使用 listen 函数时,内核会根据传入的 backlog 参数与系统参数,取二者的较小值。如果 accpet queue 队列满了,server 将发送一个拒绝连接的错误信息到 client
5.1.2.3 ulimit -n
属于操作系统参数,表示一个进程能打开的文件描述符的参数
5.1.2.4 TCP_NODELAY
属于 SocketChannal 参数,默认是false,即开启nagle算法
5.1.2.4 SO_SNDBUF & SO_RCVBUF
SO_SNDBUF 属于 SocketChannal 参数,SO_RCVBUF 既可用于 SocketChannal 参数,也可以用于 ServerSocketChannal 参数(建议设置到 ServerSocketChannal 上)。用于调整发送缓冲区和接收缓冲区的大小
5.1.2.5 ALLOCATOR
属于 SocketChannal 参数,用来分配 ByteBuf: ctx.alloc()
在Windows上默认是PooledByteBufAllocator
// io.netty.buffer.ByteBufUtil
static {
String allocType = SystemPropertyUtil.get(
"io.netty.allocator.type", PlatformDependent.isAndroid() ? "unpooled" : "pooled");
allocType = allocType.toLowerCase(Locale.US).trim();
ByteBufAllocator alloc;
if ("unpooled".equals(allocType)) {
alloc = UnpooledByteBufAllocator.DEFAULT;
logger.debug("-Dio.netty.allocator.type: {}", allocType);
} else if ("pooled".equals(allocType)) {
alloc = PooledByteBufAllocator.DEFAULT;
logger.debug("-Dio.netty.allocator.type: {}", allocType);
} else {
alloc = PooledByteBufAllocator.DEFAULT;
logger.debug("-Dio.netty.allocator.type: pooled (unknown: {})", allocType);
}
...
}也可以调整io.netty.allocator.type来控制是否是池化,通过io.netty.noPreferDirect(默认false)调整是否使用直接内存
5.1.2.6 RCVBUF_ALLOCATOR
属于 SocketChannal 参数,用于控制 netty 接收缓冲区大小
负责入站数据的分配,决定入站缓冲区的大小(并可动态调整),统一采用 direct 直接内存,具体池化还是非池化由 allocator 决定
5.2 Netty部分源码
多图预警!
5.2.1 启动流程
回顾一下NIO的启动
// 创建Selector, 管理多个Channel
try (
ServerSocketChannel channel = ServerSocketChannel.open();
) {
// 启动服务端
int port = NetworkUtil.findAvailablePort(8080);
channel.bind(new InetSocketAddress(port));
log.info("Server start at port {}", port);
channel.configureBlocking(false);
// 建立Selector管理ServerSocketChannel(注册)
// SelectionKey: 事件发生后, 通过SelectionKey可以获得事件类型和事件所关联的Channel
// 第二个参数 指明监听事件类型为Accept事件
Selector selector = Selector.open();
channel.configureBlocking(false);
channel.register(selector, SelectionKey.OP_ACCEPT);
while (true) {...}
}其实netty就是对nio进行封装,因此启动流程也类似,看看netty是怎么做的把~
以下面一段简单代码为例
public static void main(String[] args) {
new ServerBootstrap()
.group(new NioEventLoopGroup())
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ch.pipeline().addLast(new LoggingHandler(LogLevel.DEBUG));
}
}).bind(8080);
}我们主要关注bind方法,bind方法调用doBind方法,实现如下:
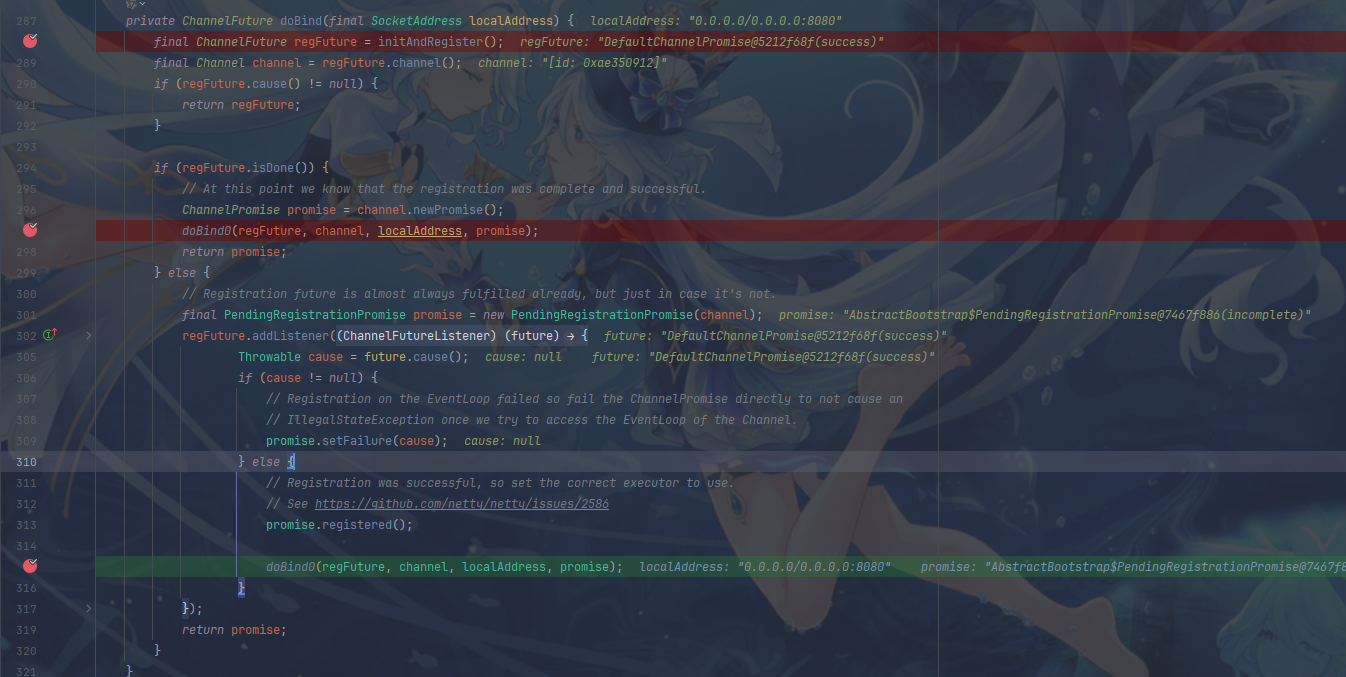
其中主要的方法有initAndRegister和doBind0,init就相当于我们之前写nio的创建ServerSocktChannel(ServerSocketChannel ssc = ServerSocketChannel .open()),Register就是将ssc绑定到selector上(SelectionKey scKey = ssc.register(selector, 0, nettySsc)),doBind0则是真正监听8080端口(ssc.bind(new InetSocketAddress(8080, backlog)))
接下来具体看一下initAndRegister方法,首先调用反射创建NioServerSocketChannel,并执行provider.openServerSocketChannel方法(provider.openServerSocketChannel就类似于ServerSocketChannel的open方法,如下图)
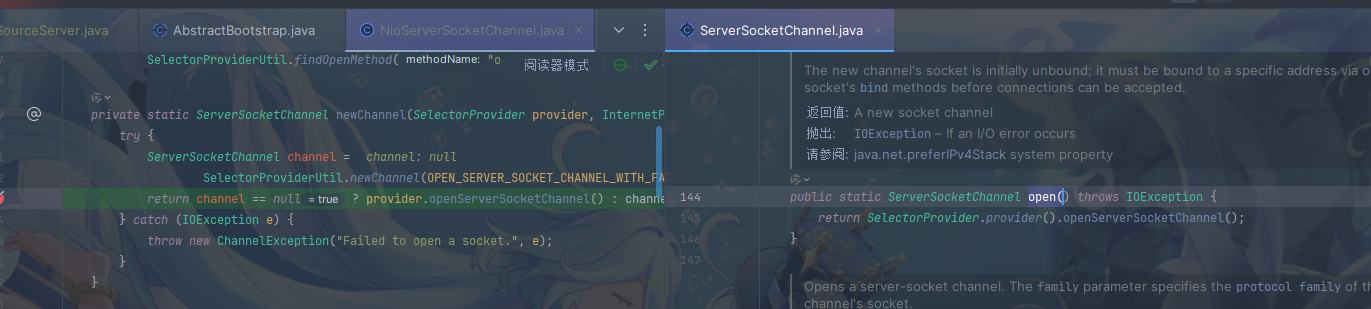
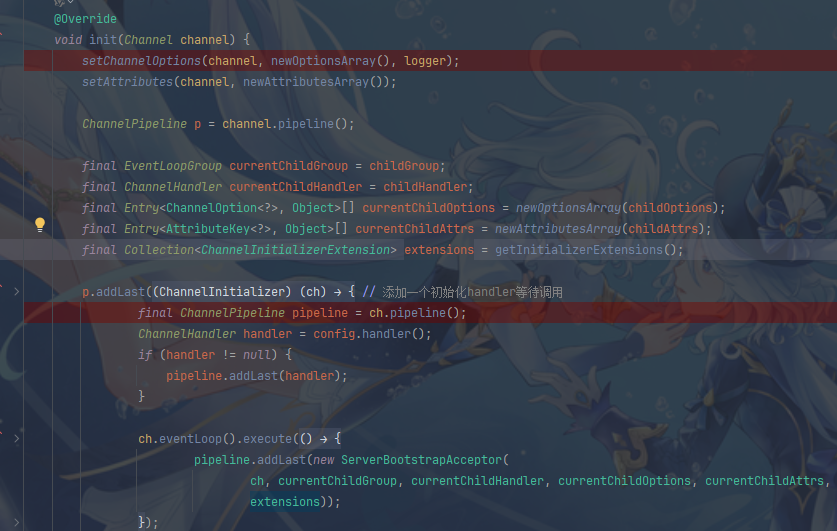
然后执行init方法,init方法主要是添加了一个初始化的handler等待调用,这个handler其实是向nio ssc加入了ServerBootstrapAcceptor,也是一个handler,用于在accept事件发生后建立连接
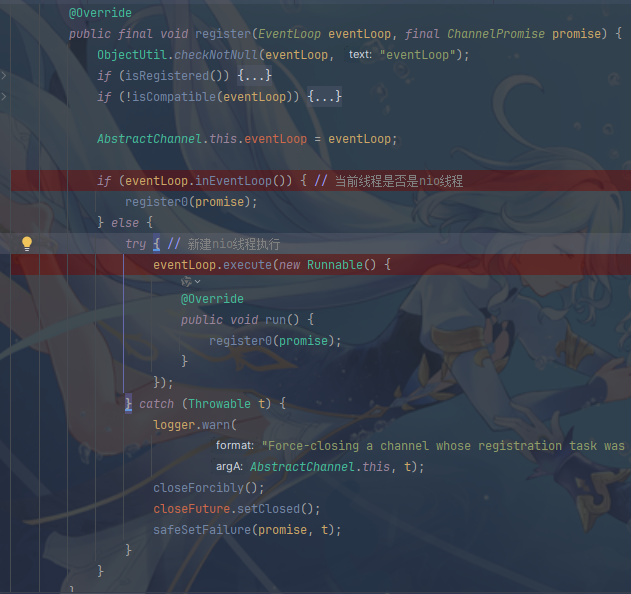
接着register方法,register方法主要是切换线程,从主线程切换到nio线程,并将ssc绑定到selector上,并键NioServerSocketChannel作为附件传递
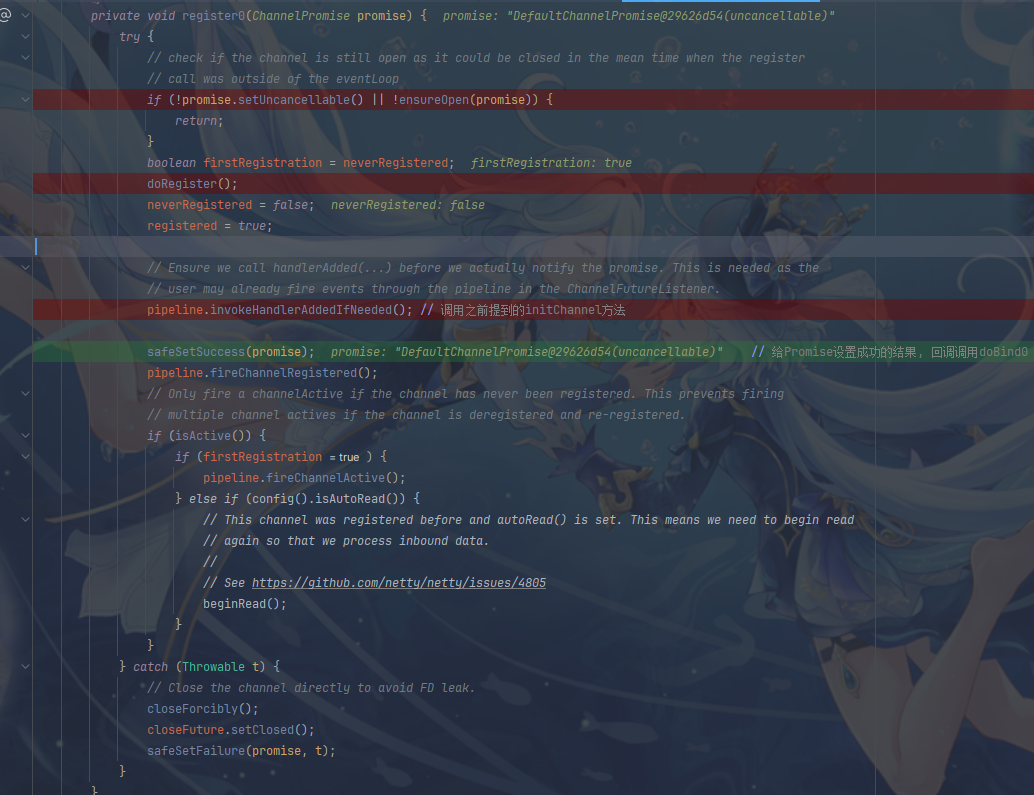
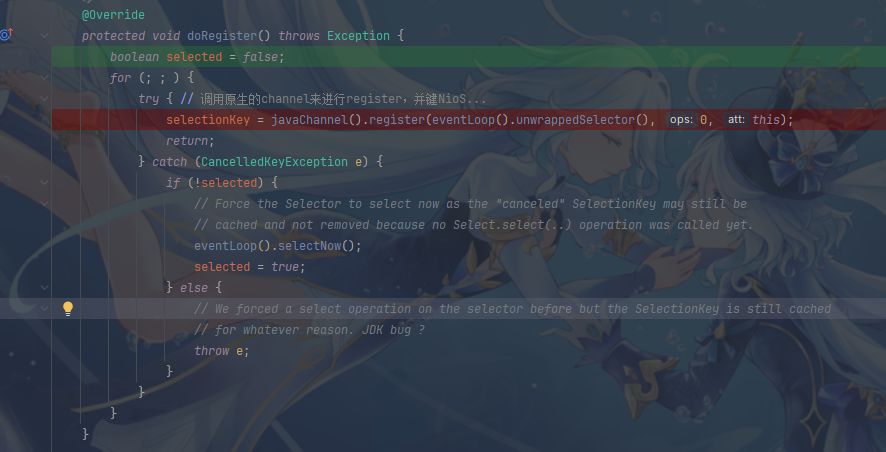
register方法结束后会设置Promise的结果,即回调doBind0
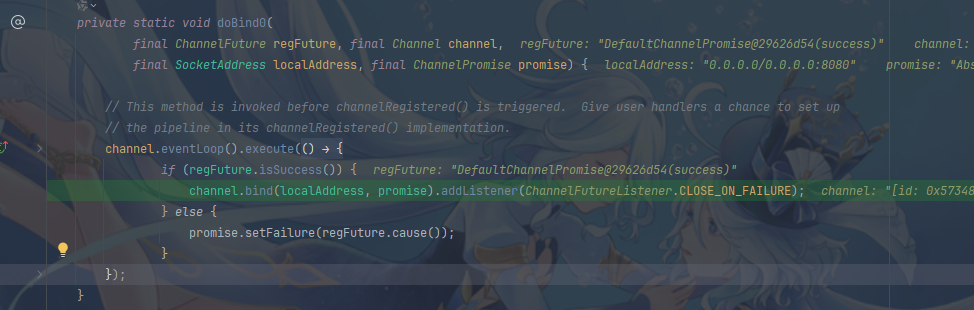
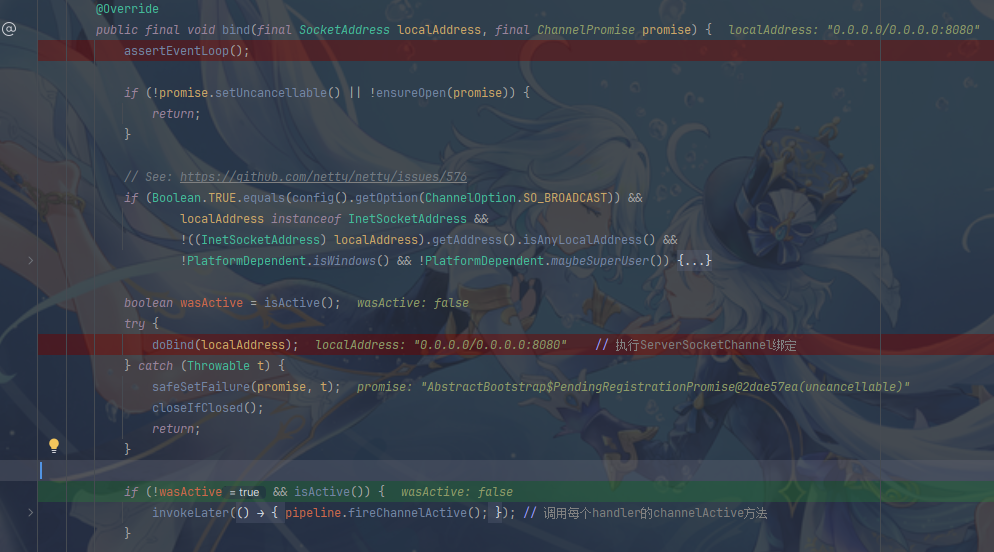
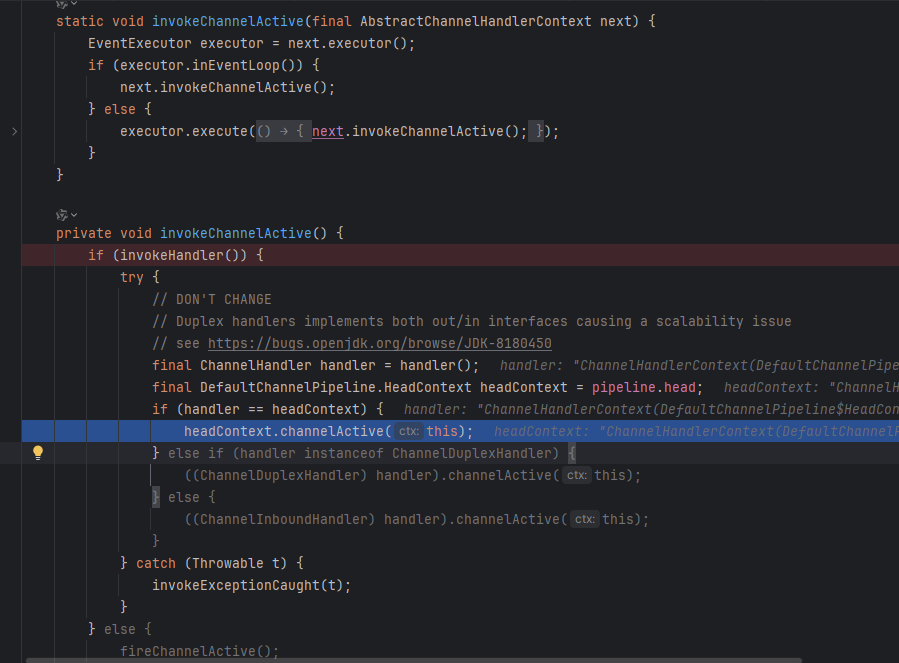
doBind会调用原生的ServerSocketChannel进行端口绑定,并调用处理链上的channelActive方法(实际上是关注OP_ACCEPT事件)

5.2.2 NioEventLoop
NioEventLoop有三个组成部分:Selector、线程和任务队列,它既可以处理IO事件,也会处理普通任务
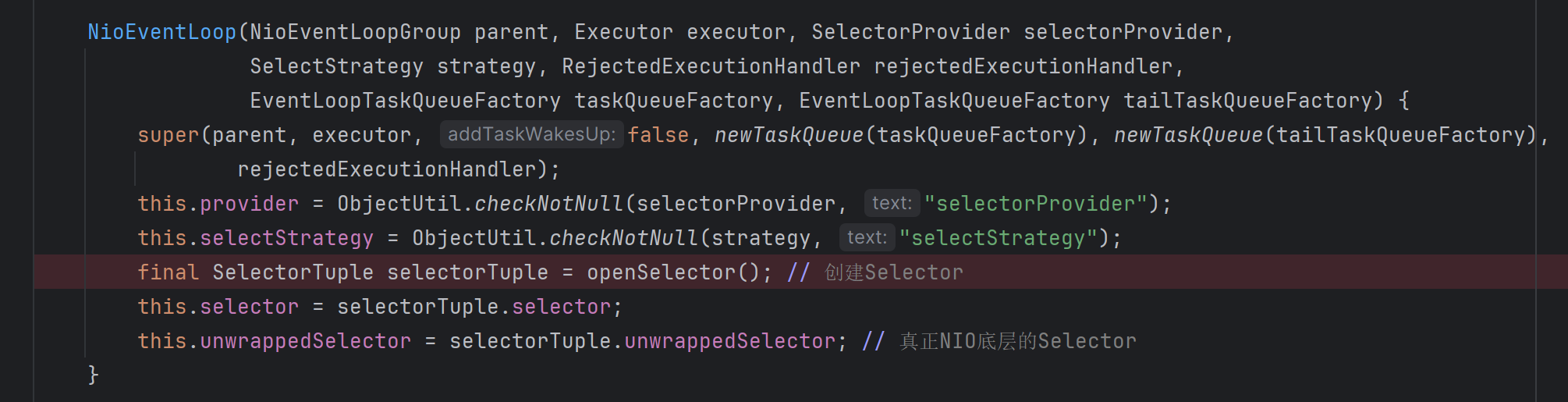
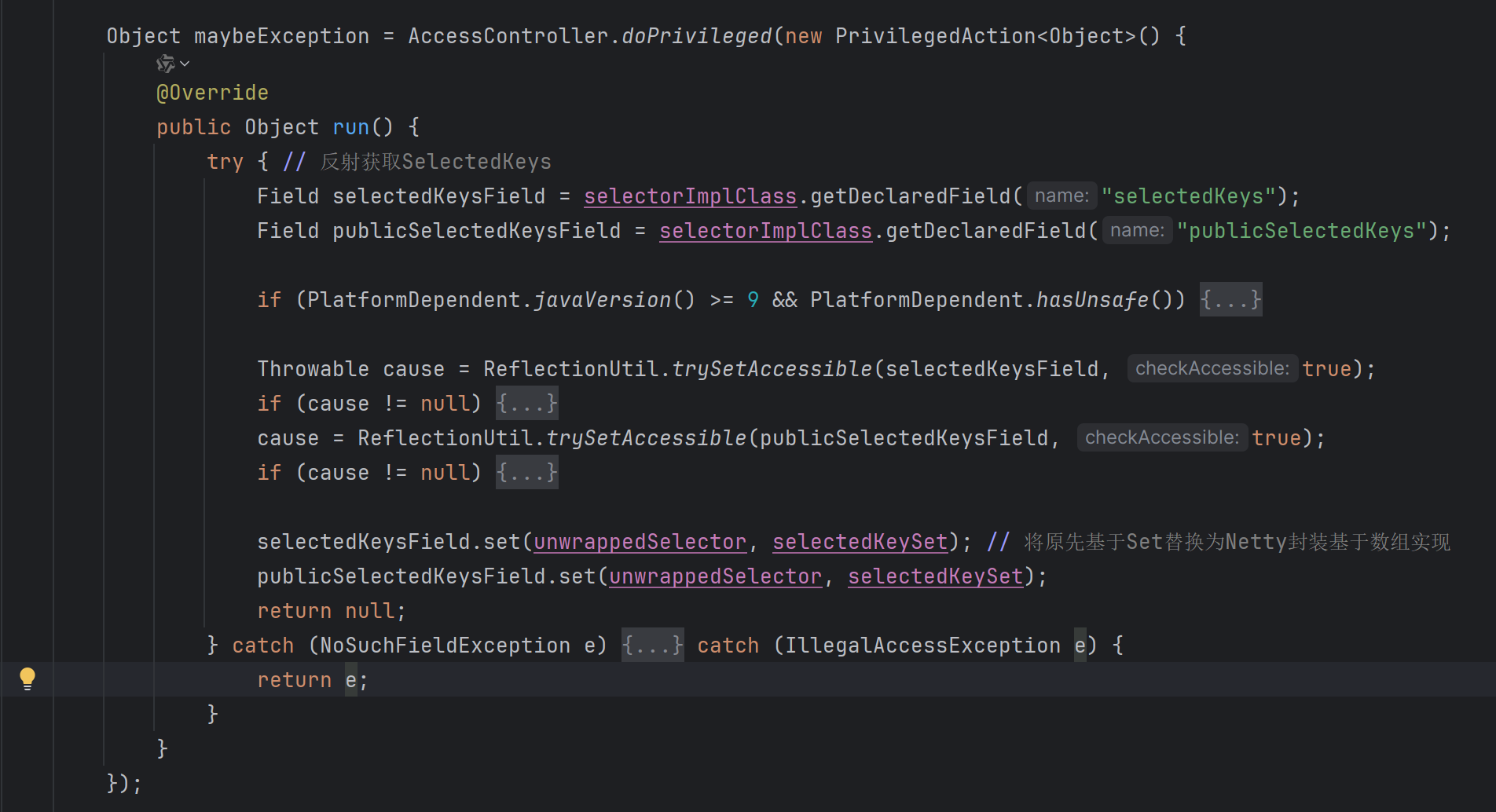
在NioEventLoop的构造方法中会创建Selector,我们看到获得了两个Selector,其中一个unwrappedSelector是NIO底层的Selector,另外一个Selector则是Netty对其做了优化,具体是将selectedKeys(原先为Set实现)替换为基于数组实现,遍历效率会高一点
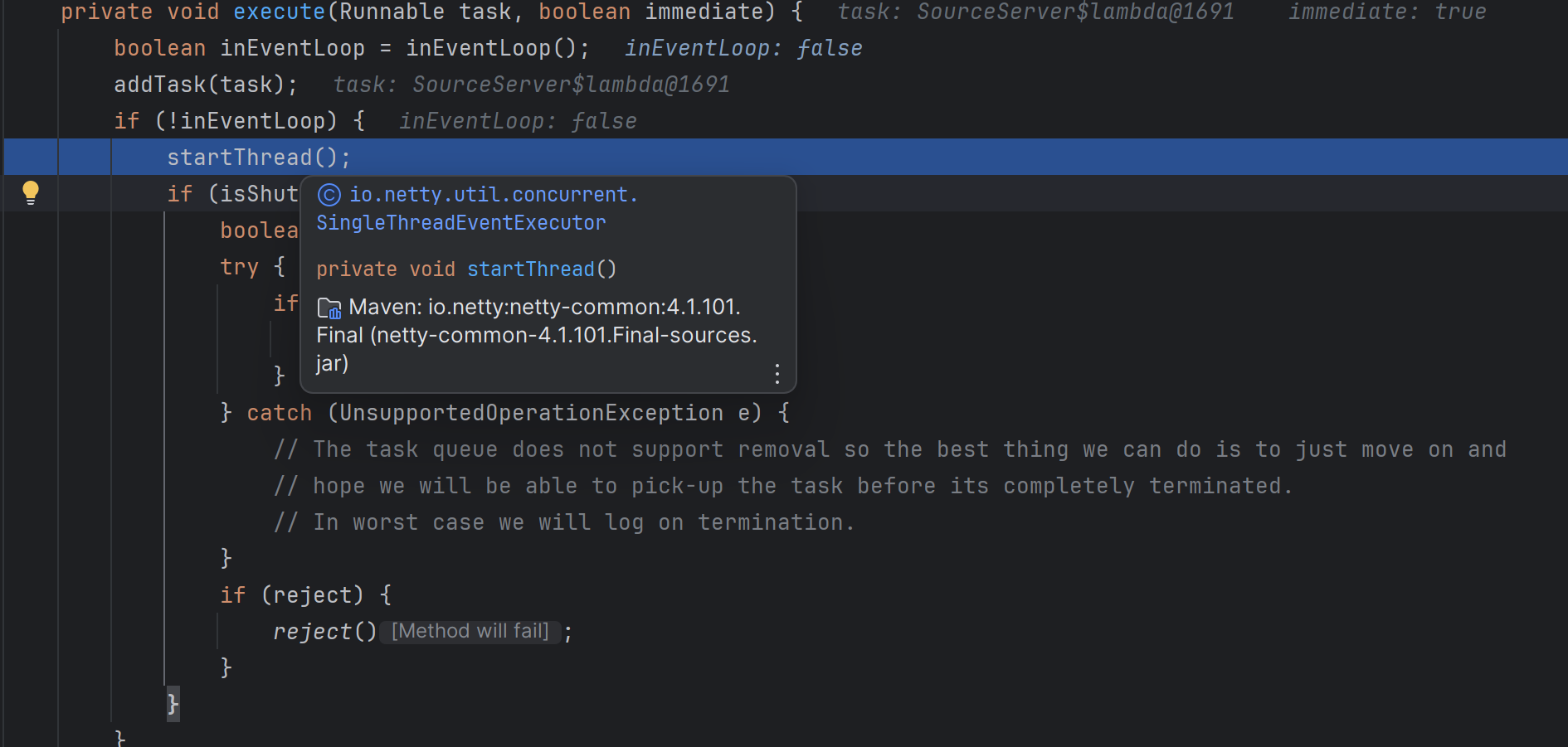
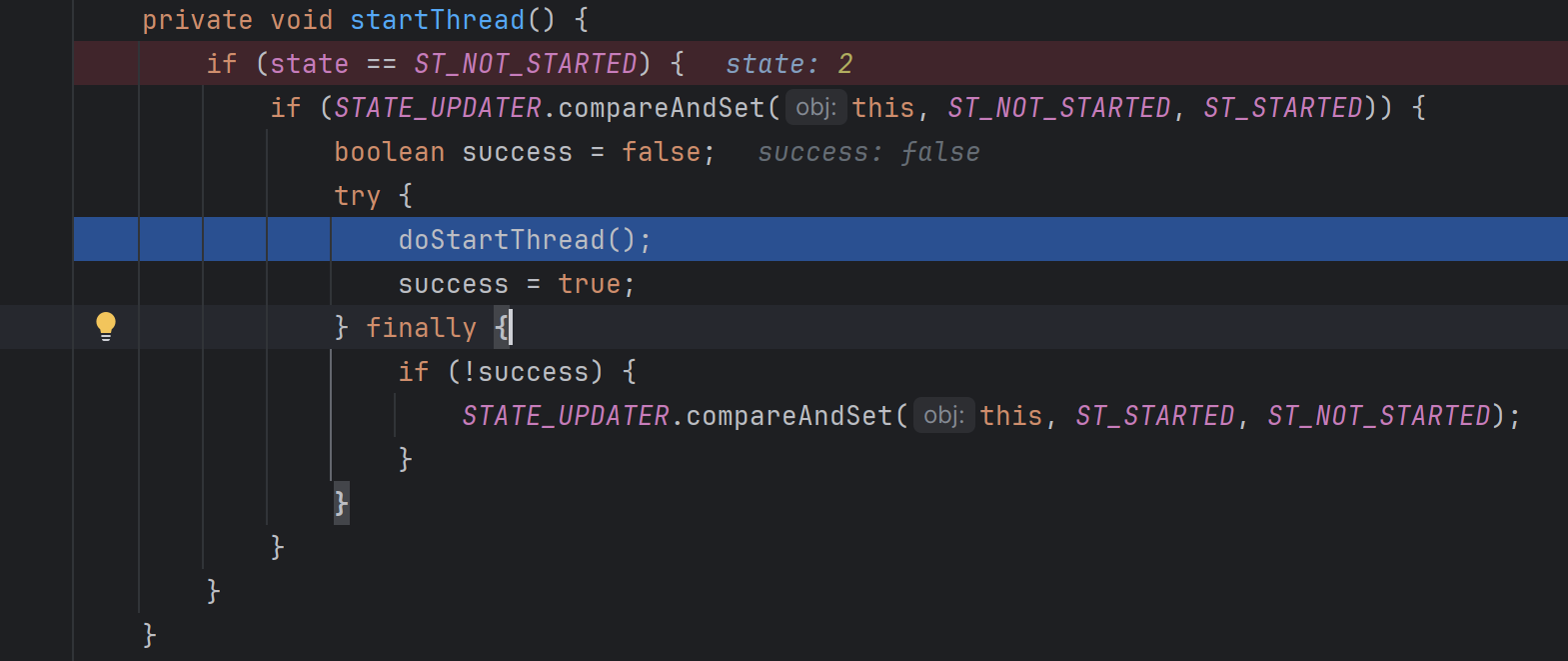
在第一次调用execute的时候会创建Nio线程,并通过状态位控制线程只会启动一次
当selector的Select方法阻塞时,由于EventLopp不仅要处理IO事件,任务来了也得处理,因此调用有参的Select表示超时时间,并且在有任务来的时候,还会调用wakeup方法进行唤醒
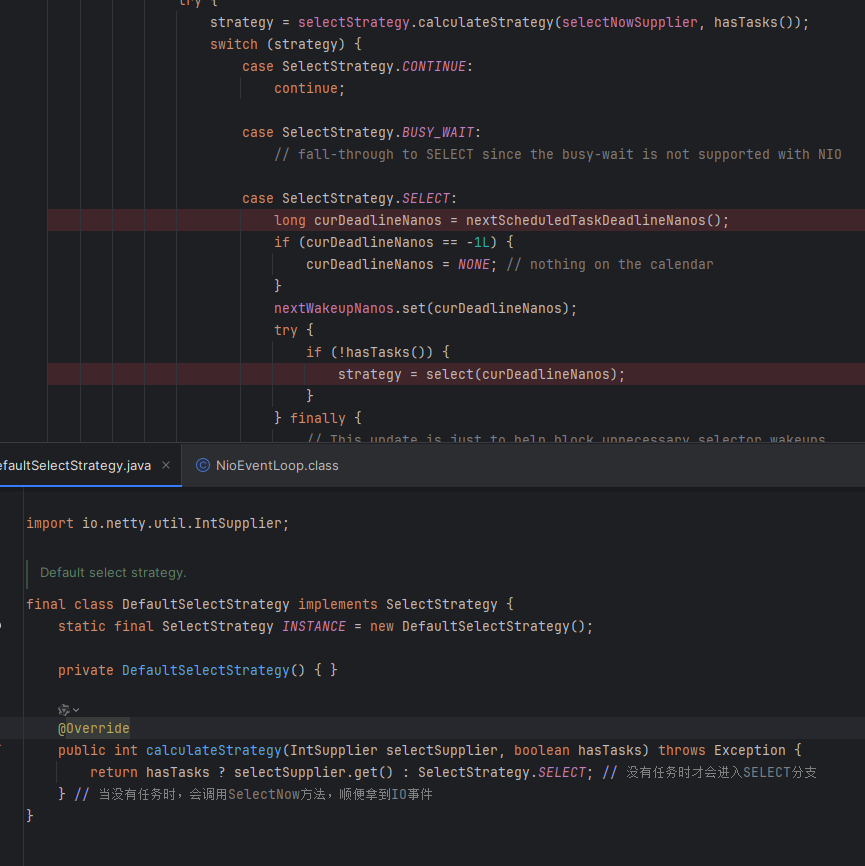
selector.select阻塞的超时时间是1.5s
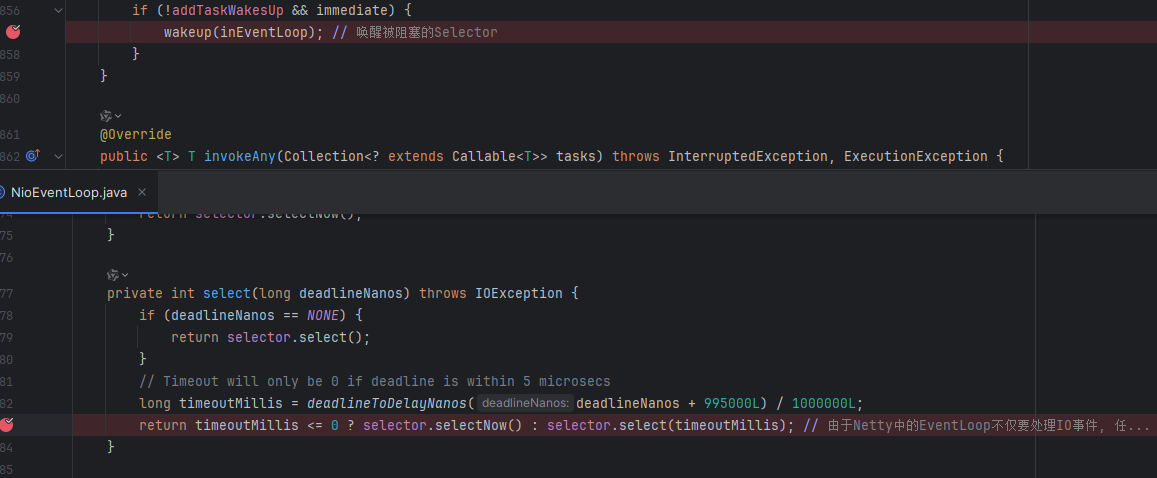
wakeup方法实现如下,使用CAS并且只有其他线程提交任务的时候,才会唤醒select

那NioEventLoopSelect 方法什么时候退出死循环呢?
每次循环的时候会更新当前时间,假如当前时间到了截至时间,就会跳出循环
循环时间过程中发现有任务了,也会退出循环
selector.select返回不为0,也即有事件发生了,也会退出循环
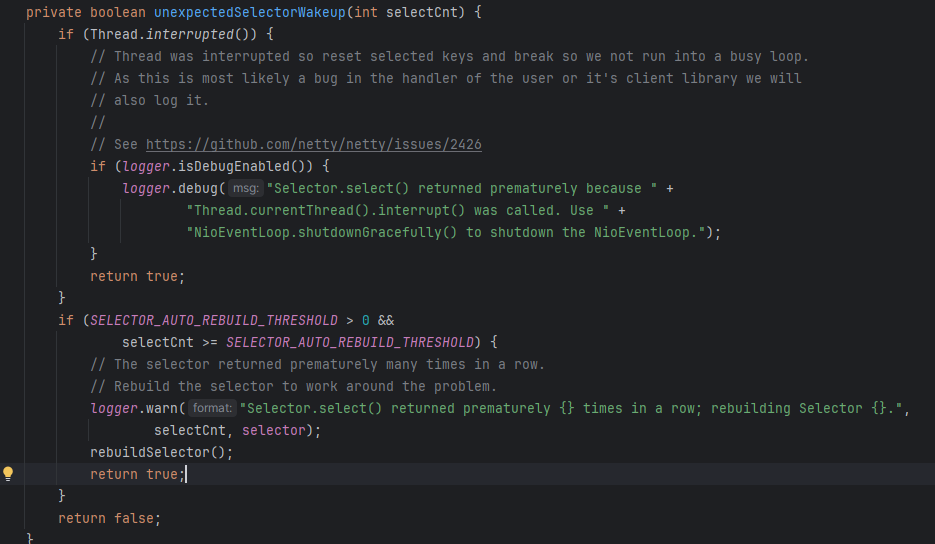
总所周知,NIO有一个空轮询BUG
JDK在Linux的Selector会发生这个Bug,当BUG发生时,selector.select没有事件发生,没有超时,select也不会阻塞住,由于是死循环,也就导致CPU空转,而一旦线程多,就容易导致CPU占用100%,而Netty解决的方法也很简单,就是维护一个计数器selectCnt,每次循环的时候将selectCnt +1 正常的时候将selectCnt置为0,当selectCnt > 配置的值(SELECTOR_AUTO_REBUILD_THRESHOLD,配置方法是io.netty.selectorAutoRebuildThreshold,默认是512)就认为产生了空轮询BUG,就重新创建Select,并将旧Selector的事件等内容复制到新的Selector,替换旧的Selector
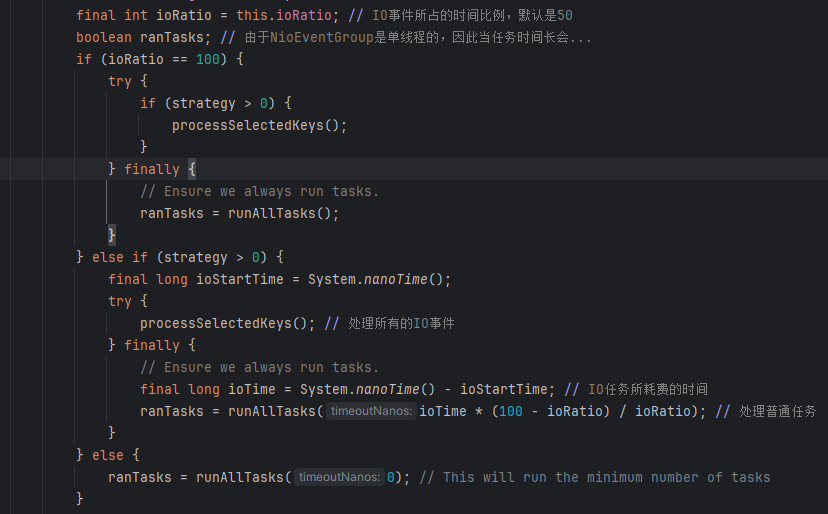
当有任务或者事件进来的时候,就会处理IO和任务,里面有一个参数ioRatio,默认是50,由于NioEventGroup是单线程的,因此当任务时间长会影响IO事件处理,因此ioRatio就是用来控制两者的时间比例,执行完IO任务后,根据IO任务执行的时间,计算任务可以执行的时间。当ioRatio设置成100的时候,则会先执行io事件,执行完之后反而会执行全部的任务
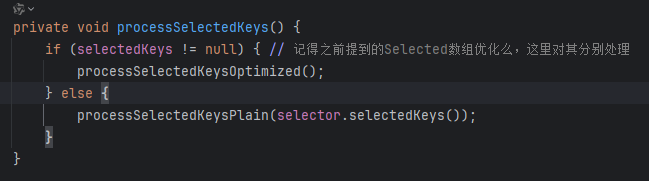
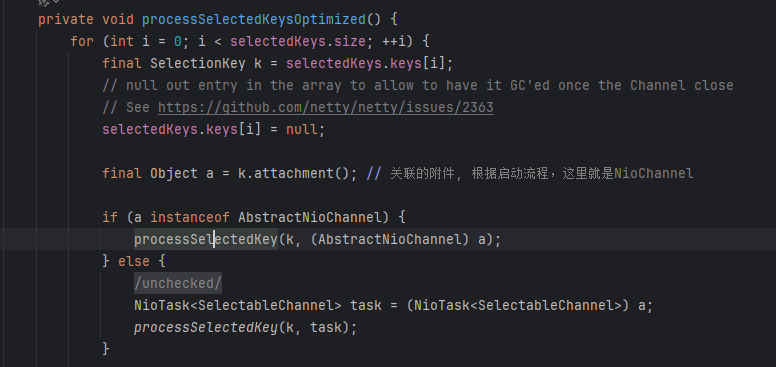
processSelectedKey会根据事件类型处理各种事件
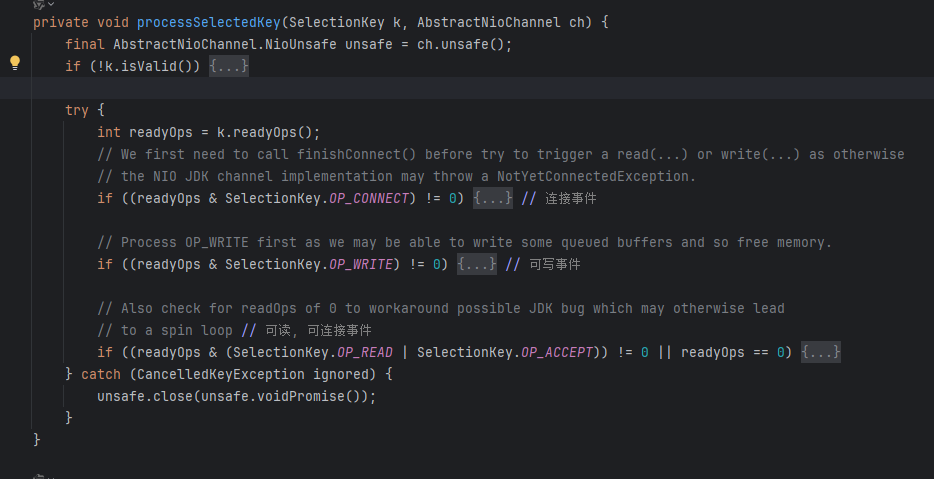
5.2.3 accept流程
在nio中的accept和read如下:
while (true) {
// select是阻塞方法, 直到有事件发生, 才会恢复运行
log.info("Waiting for event...");
int count = selector.select();
log.info("Event count: {}", count);
// 获取所有可用的事件
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> iter = keys.iterator();
while (iter.hasNext()) {
SelectionKey key = iter.next();
// 处理Key的时候, 要从集合中删除
// 否则下次处理但没有事件就会报错
if (key.isAcceptable()) { // 处理Accept事件
handleAccept(key, selector);
} else if (key.isReadable()) { // 处理Read事件
handleRead(key);
}
// 处理完毕,必须将事件移除
iter.remove();
}
}
private static void handleAccept(SelectionKey key, Selector selector) throws IOException {
try (ServerSocketChannel channel = (ServerSocketChannel) key.channel()) {
// 必须处理
SocketChannel sc = channel.accept();
sc.configureBlocking(false);
ByteBuffer buffer = ByteBuffer.allocate(16);
sc.register(selector, SelectionKey.OP_READ, buffer); // 关注Read事件
log.info("Accepted connection from {}", sc.getRemoteAddress());
}
}而while true就对应我们之前的死循环,上面我们就提到了processSelectedKey其实就是处理相对应的事件,因此accept执行的是unsafe.read();
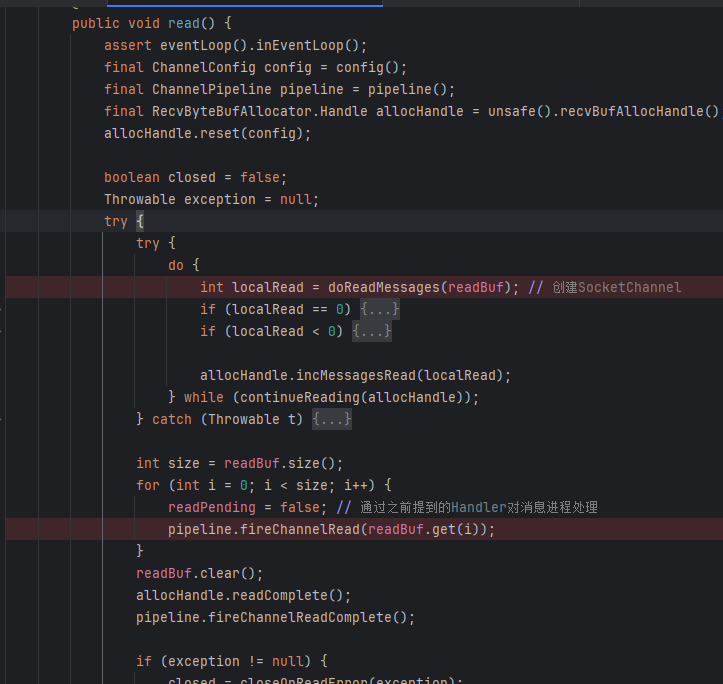
在doReadMessages其实就对应我们的创建SocketChannel,并设置非阻塞,也会创建NioSocketChannel
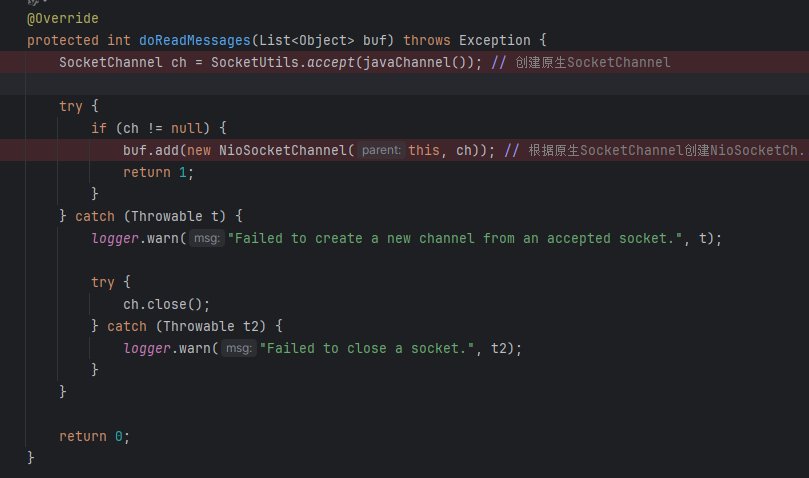
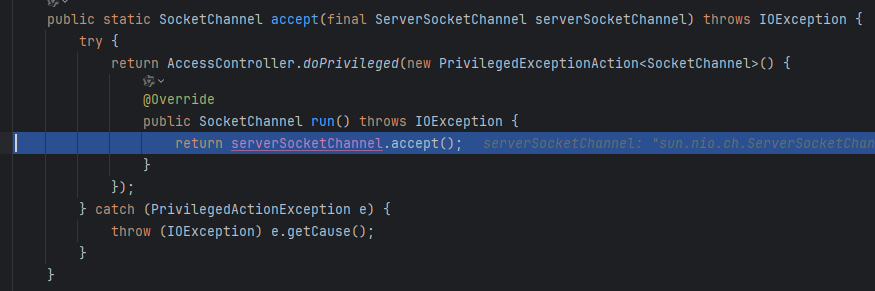
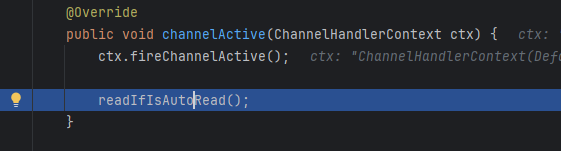
然后会执行fireChannelRead,会把新的NioEventLoop的selector监听这个Channel上的事件(对应sc.register(selector, 0, NioSocketChannel)),这个时候会调用NioSocketChannel上的初始化器(即之前写的添加handler)
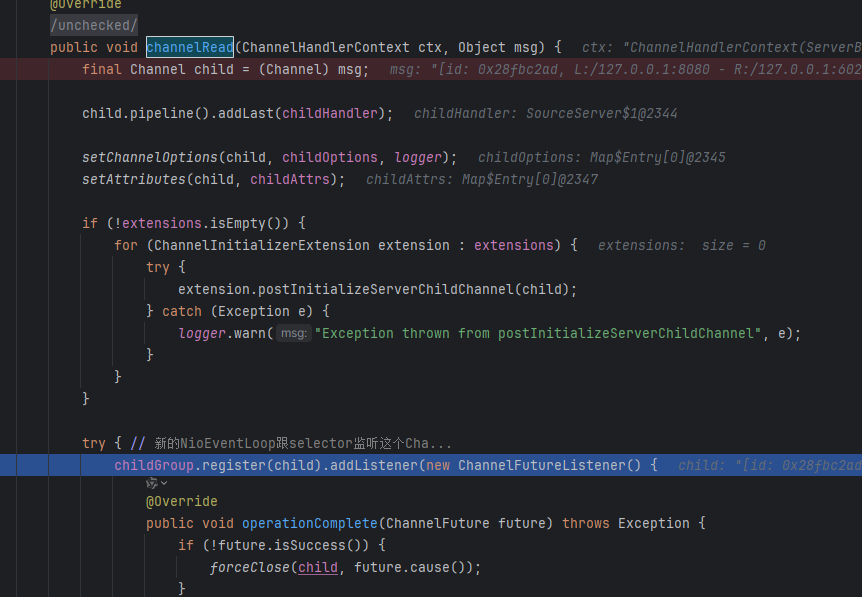
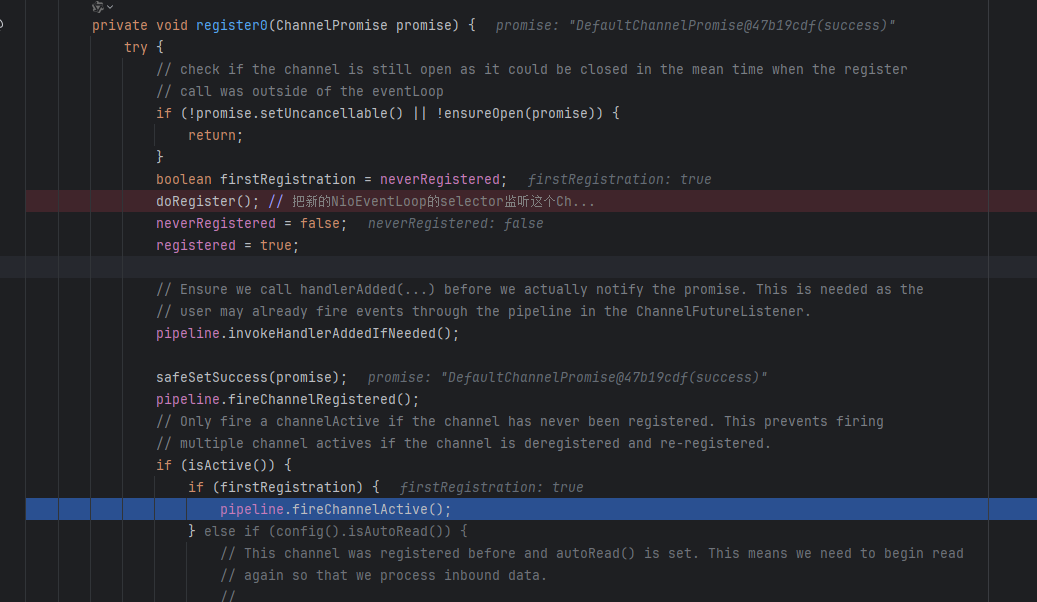
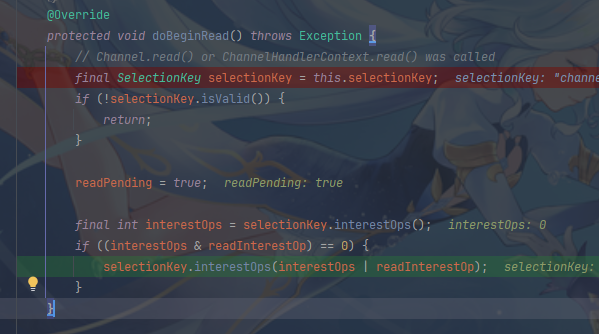
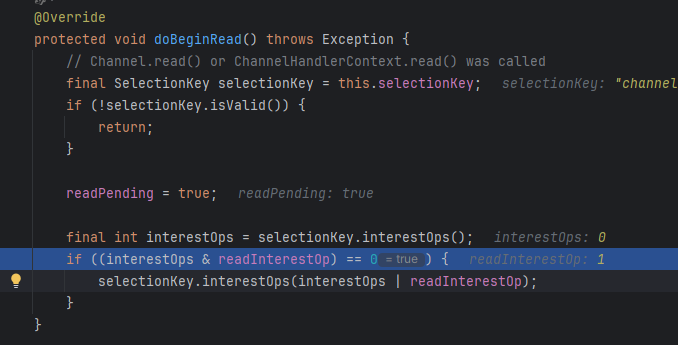
然后就可以监听读事件了
5.2.4 read流程
read方法也是执行unsafe.read(),关键方法为doReadBytes和fireChannelRead,doReadBytes会填充byteBuf,fireChannelRead则会调用处理链上的读事件
评论