

1 Zookeeper解析基础
1.1 Paxos算法
Paxos算法:一种基于消息传递且具有高度容错特性的一致性算法。Paxos算法解决的问题就是如何快速正确的在一个分布式系统中对某个数据值达成一致,并且保证不论发生任何异常,都不会破坏整个系统的一致性。
在一个Paxos系统中,首先将所有节点划分为Proposer(提议者),Acceptor(接受者),和Learner(学习者)。(注意:每个节点都可以身兼数职)。
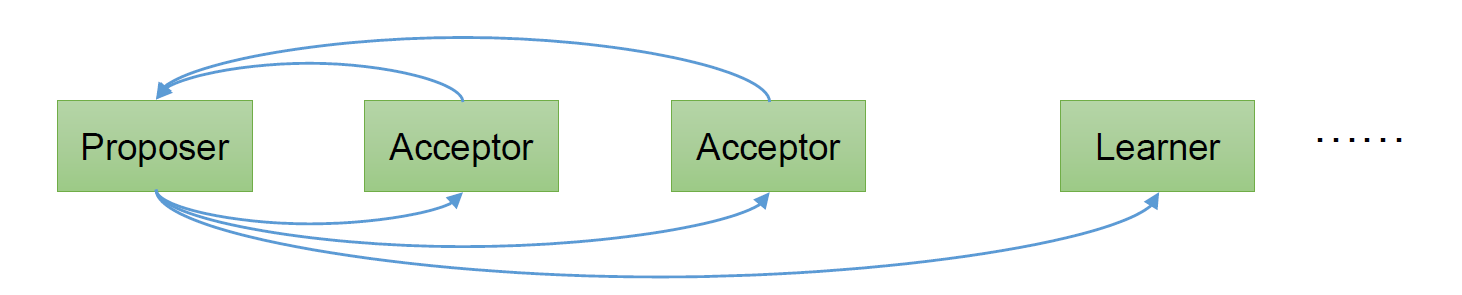
一个完整的Paxos算法流程分为三个阶段:
Prepare准备阶段:Proposer生成全局唯一且递增的Proposal ID,向所有Acceptor发送Propose请求,这里无需携带提案内容,只携 带Proposal ID即可。Acceptor收到Propose请求后,做出“两个承诺,一个应答”。
不再接受Proposal ID小于等于当前请求的Propose请求。
不再接受Proposal ID小于当前请求的Accept请求。
不违背以前做出的承诺下,回复已经Accept过的提案中Proposal ID最大的那个提案的Value和Proposal ID,没有则返回空值。
Accept接受阶段:Proposer收到多数Acceptor的Promise应答后,从应答中选择Proposal ID最大的提案的Value,作为本次要发起的提案。如果所有应答的提案Value均为空值,则可以自己随意决定提案Value。然后携带当前Proposal ID,向所有Acceptor发送Propose请求。Acceptor收到Propose请求后,在不违背自己之前做出的承诺下,接受并持久化当前Proposal ID和提案Value。
Learn学习阶段:Proposer收到多数Acceptor的Accept后,决议形成,将形成的决议发送给所有Learner。
1.2 ZAB 协议
Zab 借鉴了Paxos 算法,是特别为Zookeeper 设计的支持崩溃恢复的原子广播协议。基于该协议,Zookeeper 设计为只有一台客户端(Leader)负责处理外部的写事务请求,然后Leader 客户端将数据同步到其他Follower 节点。即Zookeeper 只有一个Leader 可以发起提案。
Zab 协议包括两种基本的模式:消息广播、崩溃恢复。
1.2.1 消息广播
ZAB协议针对事务请求的处理过程类似于一个两阶段提交过程
广播事务阶段
广播提交操作
具体如下:
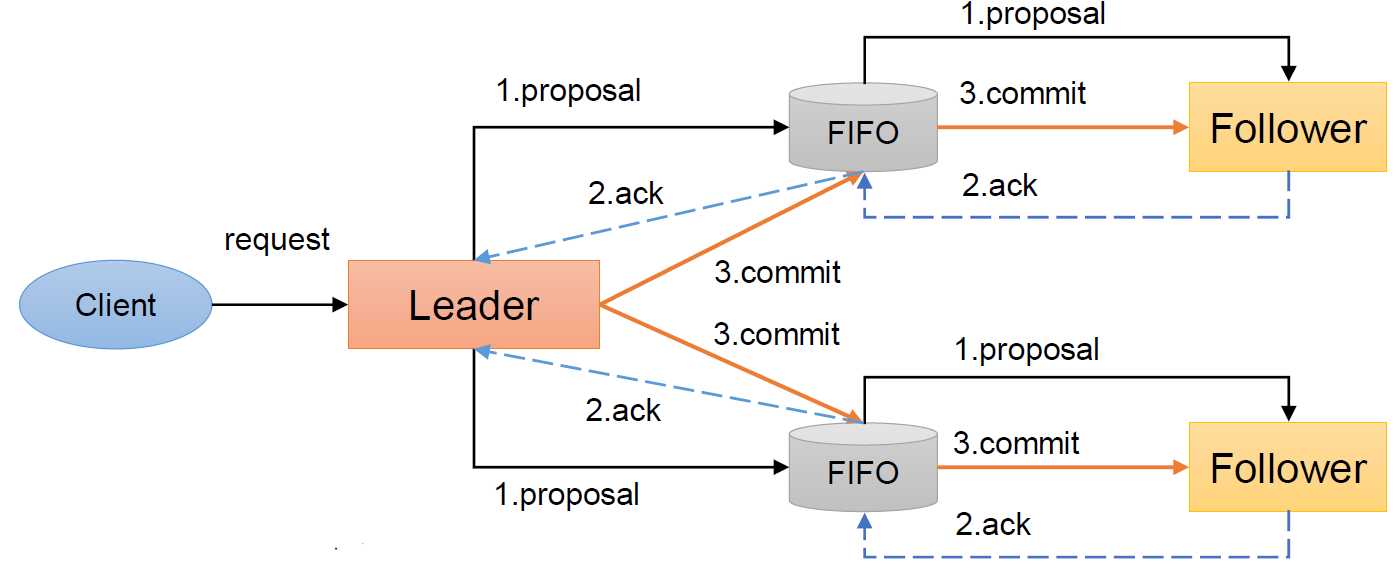
客户端发起一个写操作请求。
Leader服务器将客户端的请求转化为事务Proposal 提案,同时为每个Proposal 分配一个全局的ID,即zxid。
Leader服务器为每个Follower服务器分配一个单独的队列,然后将需要广播的Proposal依次放到队列中去,并且根据FIFO策略进行消息发送。
Follower接收到Proposal后,会首先将其以事务日志的方式写入本地磁盘中,写入成功后向Leader反馈一个Ack响应消息。
Leader接收到超过半数以上Follower的Ack响应消息后,即认为消息发送成功,可以发送commit消息。
Leader向所有Follower广播commit消息,同时自身也会完成事务提交。Follower 接收到commit消息后,会将上一条事务提交。
Zookeeper采用Zab协议的核心,就是只要有一台服务器提交了Proposal,就要确保所有的服务器最终都能正确提交Proposal。
1.2.2 崩溃恢复
一旦Leader服务器出现崩溃或者由于网络原因导致Leader服务器失去了与过半Follower的联系,那么就会进入崩溃恢复模式。
Zab协议崩溃恢复要求满足以下两个要求:
确保已经被Leader提交的提案Proposal,必须最终被所有的Follower服务器提交。
确保丢弃已经被Leader提出的,但是没有被提交的Proposal。
崩溃恢复主要包括两部分:Leader选举和数据恢复。
Leader选举:根据上述要求,Zab协议需要保证选举出来的Leader需要满足以下条件:
新选举出来的Leader不能包含未提交的Proposal。即新Leader必须都是已经提交了Proposal的Follower服务器节点
新选举的Leader节点中含有最大的zxid。这样做的好处是可以避免Leader服务器检查Proposal的提交和丢弃工作。
数据同步:
完成Leader选举后,在正式开始工作之前(接收事务请求,然后提出新的Proposal),Leader服务器会首先确认事务日志中的所有的Proposal 是否已经被集群中过半的服务器Commit。
Leader服务器需要确保所有的Follower服务器能够接收到每一条事务的Proposal,并且能将所有已经提交的事务Proposal应用到内存数据中。等到Follower将所有尚未同步的事务Proposal都从Leader服务器上同步过,并且应用到内存数据中以后,Leader才会把该Follower加入到真正可用的Follower列表中。
1.3 CAP理论
CAP理论告诉我们,一个分布式系统不可能同时满足以下三种
一致性(C:Consistency):在分布式环境中,一致性是指数据在多个副本之间是否能够保持数据一致的特性。在一致性的需求下,当一个系统在数据一致的状态下执行更新操作后,应该保证系统的数据仍然处于一致的状态。
可用性(A:Available):可用性是指系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。
分区容错性(P:Partition Tolerance):分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障。
Zookeeper保证的是CP:
Zookeeper不能保证每次服务请求的可用性。(注:在极端环境下,Zookeeper可能会丢弃一些请求,消费者程序需要重新请求才能获得结果)。所以说,Zookeeper不能保证服务可用性。
进行Leader选举时集群都是不可用。
2 源码解析
2.1 服务端初始化源码

Zookeeper启动是从org.apache.zookeeper.server.quorum.QuorumPeerMain开始的
// QuorumPeerMain
public static void main(String[] args) {
QuorumPeerMain main = new QuorumPeerMain();
try {
// 初始化并且启动
main.initializeAndRun(args);
}
......
ServiceUtils.requestSystemExit(ExitCode.EXECUTION_FINISHED.getValue());
}初始化并且启动的方法initializeAndRun
// QuorumPeerMain
protected void initializeAndRun(String[] args) throws ConfigException, IOException, AdminServerException {
// 解析参数 zoo.cfg和 myid
QuorumPeerConfig config = new QuorumPeerConfig();
if (args.length == 1) {
config.parse(args[0]);
}
// Start and schedule the the purge task
// 启动定时任务,删除过期快照
DatadirCleanupManager purgeMgr = new DatadirCleanupManager(
config.getDataDir(),
config.getDataLogDir(),
config.getSnapRetainCount(), // 最少保留快照的个数
config.getPurgeInterval()); // 默认0表示关闭
purgeMgr.start();
// 通信初始化
if (args.length == 1 && config.isDistributed()) {
runFromConfig(config);
} else {
LOG.warn("Either no config or no quorum defined in config, running in standalone mode");
// there is only server in the quorum -- run as standalone
ZooKeeperServerMain.main(args);
}
}进行通信初始化
// QuorumPeerMain
public void runFromConfig(QuorumPeerConfig config) throws IOException, AdminServerException {
try {
ManagedUtil.registerLog4jMBeans();
} catch (JMException e) {
LOG.warn("Unable to register log4j JMX control", e);
}
LOG.info("Starting quorum peer, myid=" + config.getServerId());
MetricsProvider metricsProvider;
try {
metricsProvider = MetricsProviderBootstrap.startMetricsProvider(
config.getMetricsProviderClassName(),
config.getMetricsProviderConfiguration());
} catch (MetricsProviderLifeCycleException error) {
throw new IOException("Cannot boot MetricsProvider " + config.getMetricsProviderClassName(), error);
}
try {
ServerMetrics.metricsProviderInitialized(metricsProvider);
ServerCnxnFactory cnxnFactory = null;
ServerCnxnFactory secureCnxnFactory = null;
// 创建通讯工厂,默认用的NIO
if (config.getClientPortAddress() != null) {
cnxnFactory = ServerCnxnFactory.createFactory();
cnxnFactory.configure(config.getClientPortAddress(), config.getMaxClientCnxns(), config.getClientPortListenBacklog(), false);
}
if (config.getSecureClientPortAddress() != null) {
secureCnxnFactory = ServerCnxnFactory.createFactory();
secureCnxnFactory.configure(config.getSecureClientPortAddress(), config.getMaxClientCnxns(), config.getClientPortListenBacklog(), true);
}
// 设置连接参数
quorumPeer = getQuorumPeer();
quorumPeer.setTxnFactory(new FileTxnSnapLog(config.getDataLogDir(), config.getDataDir()));
quorumPeer.enableLocalSessions(config.areLocalSessionsEnabled());
quorumPeer.enableLocalSessionsUpgrading(config.isLocalSessionsUpgradingEnabled());
........
quorumPeer.initialize();
if (config.jvmPauseMonitorToRun) {
quorumPeer.setJvmPauseMonitor(new JvmPauseMonitor(config));
}
// 启动zk
quorumPeer.start();
ZKAuditProvider.addZKStartStopAuditLog();
quorumPeer.join();
}
......
}2.2 服务端加载数据源码
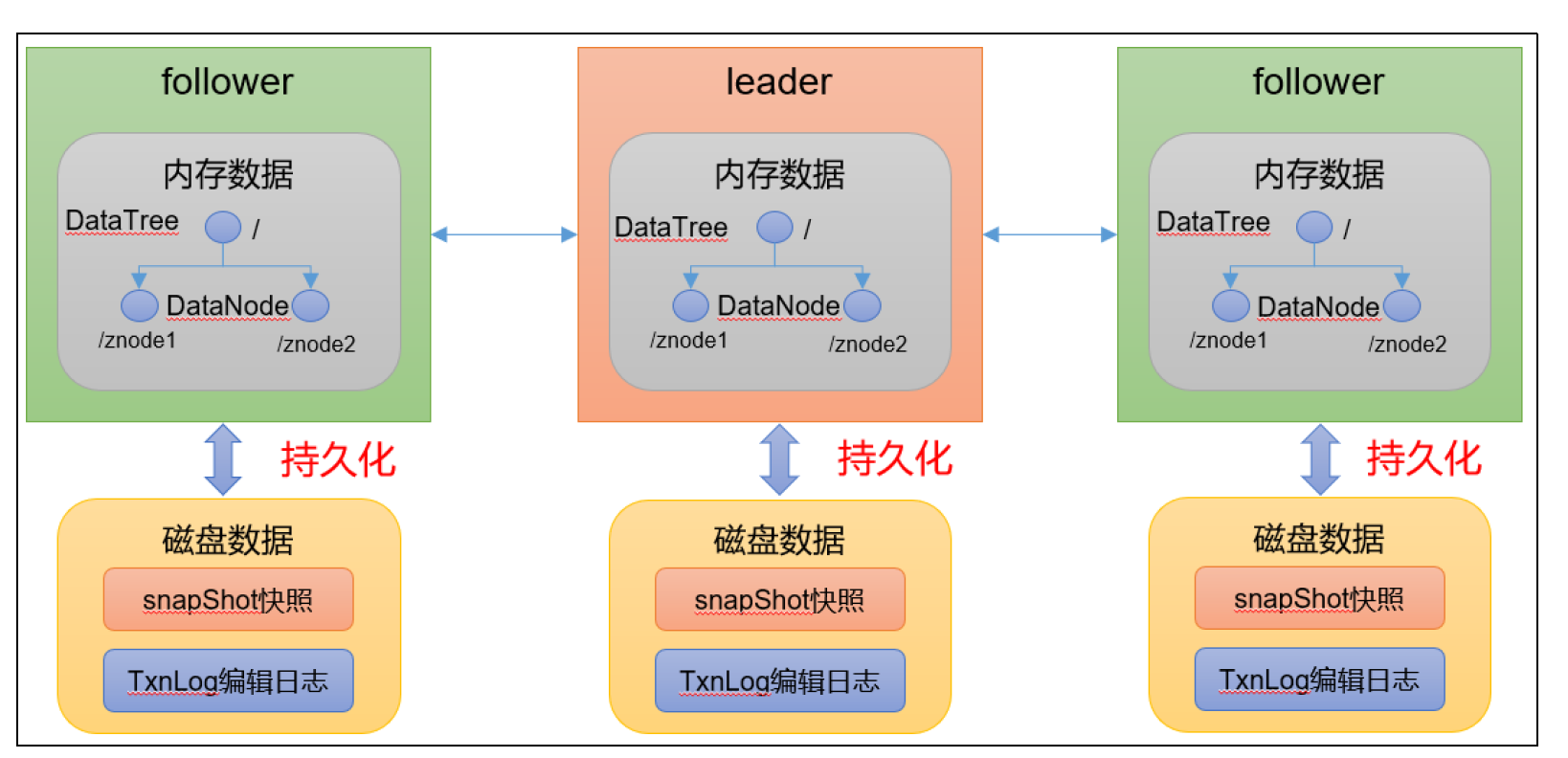
zk 中的数据模型,是一棵树,DataTree,每个节点,叫做DataNode
zk 集群中的DataTree 时刻保持状态同步
Zookeeper 集群中每个zk 节点中,数据在内存和磁盘中都有一份完整的数据。
上一章我们最后到了start方法启动ZK,我们从这个方法开始
// QuorumPeer
public synchronized void start() {
if (!getView().containsKey(myid)) {
throw new RuntimeException("My id " + myid + " not in the peer list");
}
// 加载编辑日志和镜像文件数据
loadDataBase();
startServerCnxnFactory();
try {
// 启动通信工厂实例对象
adminServer.start();
} catch (AdminServerException e) {
LOG.warn("Problem starting AdminServer", e);
System.out.println(e);
}
// 准备选举环境
startLeaderElection();
startJvmPauseMonitor();
// 执行选举
super.start();
}
// ZKDatabase
public long loadDataBase() throws IOException {
long startTime = Time.currentElapsedTime();
long zxid = snapLog.restore(dataTree, sessionsWithTimeouts, commitProposalPlaybackListener);
initialized = true;
long loadTime = Time.currentElapsedTime() - startTime;
ServerMetrics.getMetrics().DB_INIT_TIME.add(loadTime);
LOG.info("Snapshot loaded in {} ms, highest zxid is 0x{}, digest is {}",
loadTime, Long.toHexString(zxid), dataTree.getTreeDigest());
return zxid;
}// FileTxnSnapLog
public long restore(DataTree dt, Map<Long, Integer> sessions, PlayBackListener listener) throws IOException {
long snapLoadingStartTime = Time.currentElapsedTime();
// 恢复快照
long deserializeResult = snapLog.deserialize(dt, sessions);
ServerMetrics.getMetrics().STARTUP_SNAP_LOAD_TIME.add(Time.currentElapsedTime() - snapLoadingStartTime);
FileTxnLog txnLog = new FileTxnLog(dataDir);
boolean trustEmptyDB;
File initFile = new File(dataDir.getParent(), "initialize");
if (Files.deleteIfExists(initFile.toPath())) {
LOG.info("Initialize file found, an empty database will not block voting participation");
trustEmptyDB = true;
} else {
trustEmptyDB = autoCreateDB;
}
RestoreFinalizer finalizer = () -> {
// 加载编辑日志
long highestZxid = fastForwardFromEdits(dt, sessions, listener);
// The snapshotZxidDigest will reset after replaying the txn of the
// zxid in the snapshotZxidDigest, if it's not reset to null after
// restoring, it means either there are not enough txns to cover that
// zxid or that txn is missing
DataTree.ZxidDigest snapshotZxidDigest = dt.getDigestFromLoadedSnapshot();
if (snapshotZxidDigest != null) {
LOG.warn(
"Highest txn zxid 0x{} is not covering the snapshot digest zxid 0x{}, "
+ "which might lead to inconsistent state",
Long.toHexString(highestZxid),
Long.toHexString(snapshotZxidDigest.getZxid()));
}
return highestZxid;
};
.......
return finalizer.run();
}2.3 ZK选举源码
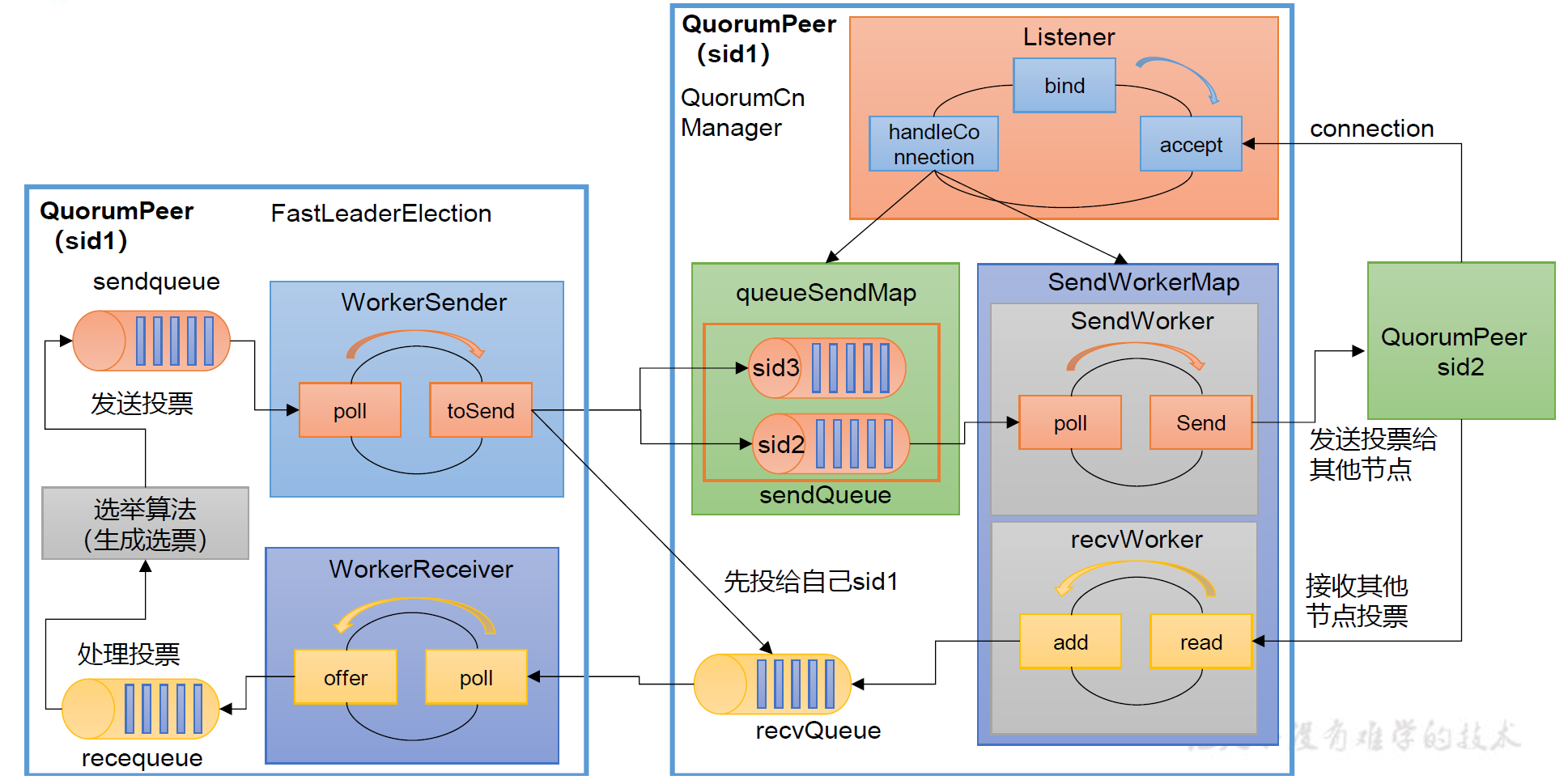
// QuorumPeer
public synchronized void startLeaderElection() {
try {
if (getPeerState() == ServerState.LOOKING) {
// 创建选票
// 选票组件 epoch leader的任期代号、 zxid某个leader当选期间执行的事务编号 myid serverid
// 开始选票时,都是先投自己
currentVote = new Vote(myid, getLastLoggedZxid(), getCurrentEpoch());
}
} catch (IOException e) {
RuntimeException re = new RuntimeException(e.getMessage());
re.setStackTrace(e.getStackTrace());
throw re;
}
// 创建选举算法实例
this.electionAlg = createElectionAlgorithm(electionType);
}// QuorumPeer
protected Election createElectionAlgorithm(int electionAlgorithm) {
Election le = null;
//TODO: use a factory rather than a switch
switch (electionAlgorithm) {
case 1:
throw new UnsupportedOperationException("Election Algorithm 1 is not supported.");
case 2:
throw new UnsupportedOperationException("Election Algorithm 2 is not supported.");
case 3:
// 创建QuorumCnxnManager,负责选举过程中的所有网络通信
QuorumCnxManager qcm = createCnxnManager();
QuorumCnxManager oldQcm = qcmRef.getAndSet(qcm);
if (oldQcm != null) {
LOG.warn("Clobbering already-set QuorumCnxManager (restarting leader election?)");
oldQcm.halt();
}
QuorumCnxManager.Listener listener = qcm.listener;
if (listener != null) {
// 启动监听线程
listener.start();
// 准备开始选举
FastLeaderElection fle = new FastLeaderElection(this, qcm);
fle.start();
le = fle;
} else {
LOG.error("Null listener when initializing cnx manager");
}
break;
default:
assert false;
}
return le;
}// FastLeaderElection
public FastLeaderElection(QuorumPeer self, QuorumCnxManager manager) {
this.stop = false;
this.manager = manager;
starter(self, manager);
}// FastLeaderElection
private void starter(QuorumPeer self, QuorumCnxManager manager) {
this.self = self;
proposedLeader = -1;
proposedZxid = -1;
// 初始化队列和信息
sendqueue = new LinkedBlockingQueue<ToSend>();
recvqueue = new LinkedBlockingQueue<Notification>();
this.messenger = new Messenger(manager);
}
// QuorumPeer
@Override
public void run() {
......
try {
/*
* Main loop
*/
while (running) {
switch (getPeerState()) {
case LOOKING:
LOG.info("LOOKING");
ServerMetrics.getMetrics().LOOKING_COUNT.add(1);
if (Boolean.getBoolean("readonlymode.enabled")) {
LOG.info("Attempting to start ReadOnlyZooKeeperServer");
// Create read-only server but don't start it immediately
final ReadOnlyZooKeeperServer roZk = new ReadOnlyZooKeeperServer(logFactory, this, this.zkDb);
// Instead of starting roZk immediately, wait some grace
// period before we decide we're partitioned.
//
// Thread is used here because otherwise it would require
// changes in each of election strategy classes which is
// unnecessary code coupling.
Thread roZkMgr = new Thread() {
public void run() {
try {
// lower-bound grace period to 2 secs
sleep(Math.max(2000, tickTime));
if (ServerState.LOOKING.equals(getPeerState())) {
roZk.startup();
}
}
......
}
};
try {
roZkMgr.start();
reconfigFlagClear();
if (shuttingDownLE) {
shuttingDownLE = false;
startLeaderElection();
}
setCurrentVote(makeLEStrategy().lookForLeader());
}
......
} else {
try {
reconfigFlagClear();
if (shuttingDownLE) {
shuttingDownLE = false;
startLeaderElection();
}
// 更新当前选票
setCurrentVote(makeLEStrategy().lookForLeader());
}
......
}
break;
case OBSERVING:
try {
LOG.info("OBSERVING");
setObserver(makeObserver(logFactory));
observer.observeLeader();
}
......
break;
case FOLLOWING:
try {
LOG.info("FOLLOWING");
setFollower(makeFollower(logFactory));
// 如果是Follower,找Leader进行连接
follower.followLeader();
}
......
break;
case LEADING:
LOG.info("LEADING");
try {
setLeader(makeLeader(logFactory));
// 如果是leader 调用leader.lead
leader.lead();
setLeader(null);
}
......
}
}
}
......
}// FastLeaderElection
public Vote lookForLeader() throws InterruptedException {
......
try {
// 保存每一个服务器的最新合法有效的投票
Map<Long, Vote> recvset = new HashMap<Long, Vote>();
// 存储合法选举之外的投票结果
Map<Long, Vote> outofelection = new HashMap<Long, Vote>();
// 一次选举的最大等待时间,默认值是 0.2s
int notTimeout = minNotificationInterval;
// 每发起一轮选举, logicalclock++
// 在没有合法的 epoch数据之前,都使用逻辑时钟代替
synchronized (this) {
// 更新逻辑时钟,每进行一次选举,都需要更新逻辑时钟
logicalclock.incrementAndGet();
// 更新选票
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
......
// 广播发送选票信息
sendNotifications();
SyncedLearnerTracker voteSet;
// 一轮一轮的选举 直到选举成功
while ((self.getPeerState() == ServerState.LOOKING) && (!stop)) {
......
}
return null;
}
......
}// FastLeaderElection
private void sendNotifications() {
// 遍历投票参与者,给每台服务器发送选票
for (long sid : self.getCurrentAndNextConfigVoters()) {
QuorumVerifier qv = self.getQuorumVerifier();
// 向外发送的相关信息
ToSend notmsg = new ToSend(
ToSend.mType.notification,
proposedLeader,
proposedZxid,
logicalclock.get(),
QuorumPeer.ServerState.LOOKING,
sid,
proposedEpoch,
qv.toString().getBytes());
// 发送消息到消息队列
sendqueue.offer(notmsg);
}
}// QuorumCnxManager
public void toSend(Long sid, ByteBuffer b) {
// 如果是发送给自己,添加到自己的recvQueue
if (this.mySid == sid) {
b.position(0);
addToRecvQueue(new Message(b.duplicate(), sid));
} else {
BlockingQueue<ByteBuffer> bq = queueSendMap.computeIfAbsent(sid, serverId -> new CircularBlockingQueue<>(SEND_CAPACITY));
// 否则连接到对应服务器并发送
addToSendQueue(bq, b);
connectOne(sid);
}
}// QuorumCnxManager
private boolean startConnection(Socket sock, Long sid) throws IOException {
......
// 如果对方的Sid大于自己的Sid,说明说自己没资格当leader了,直接放弃连接
if (sid > self.getId()) {
LOG.info("Have smaller server identifier, so dropping the connection: (myId:{} --> sid:{})", self.getId(), sid);
closeSocket(sock);
// Otherwise proceed with the connection
} else {
LOG.debug("Have larger server identifier, so keeping the connection: (myId:{} --> sid:{})", self.getId(), sid);
// 否则发送相关消息
SendWorker sw = new SendWorker(sock, sid);
RecvWorker rw = new RecvWorker(sock, din, sid, sw);
sw.setRecv(rw);
SendWorker vsw = senderWorkerMap.get(sid);
if (vsw != null) {
vsw.finish();
}
senderWorkerMap.put(sid, sw);
queueSendMap.putIfAbsent(sid, new CircularBlockingQueue<>(SEND_CAPACITY));
sw.start();
rw.start();
return true;
}
return false;
}2.4 Leader和Follow状态同步源码
当选举结束后,每个节点都需要根据自己的角色更新自己的状态。选举出的Leader更新自己状态为 Leader,其他节点更新自己状态为 Follower。
Leader更新状态入口: leader.lead()
Follower更新状态入口: follower.followerLeader()
follower必须要让 leader知道自己的状态: epoch、 zxid、 sid
必须要找出谁是leader
发起请求连接leader
发送自己的信息给leader
leader接收到信息,必须要返回对应的信息给 follower。
当 leader得知 follower的状态了,就确定需要做何种方式的数据同步 DIFF、 TRUNC、SNAP
执行数据同步
当 leader接收到超过半数 follower的 ack之后,进入正常工作状态,集群启动完成了
同步策略:
DIFF咱两一样,不需要做什么
TRUNC follower的 zxid比 leader的 zxid大,所以 Follower要回滚
COMMIT leader的 zxid比 follower的 zxid大,发送 Proposal给 follower提交执行
如果 follower并没有任何数据,直接使用 SNAP的方式来执行数据同步(直接把数据全部序列到 follower)

// Leader
void lead() throws IOException, InterruptedException {
......
try {
self.setZabState(QuorumPeer.ZabState.DISCOVERY);
self.tick.set(0);
zk.loadData();
leaderStateSummary = new StateSummary(self.getCurrentEpoch(), zk.getLastProcessedZxid());
// 等待其他 follower节点向 leader节点发送同步状态
cnxAcceptor = new LearnerCnxAcceptor();
cnxAcceptor.start();
long epoch = getEpochToPropose(self.getId(), self.getAcceptedEpoch());
......
} finally {
zk.unregisterJMX(this);
}
}class LearnerCnxAcceptorHandler implements Runnable {
......
LearnerCnxAcceptorHandler(ServerSocket serverSocket, CountDownLatch latch) {
this.serverSocket = serverSocket;
this.latch = latch;
}
@Override
public void run() {
try {
Thread.currentThread().setName("LearnerCnxAcceptorHandler-" + serverSocket.getLocalSocketAddress());
while (!stop.get()) {
acceptConnections();
}
} catch (Exception e) {
LOG.warn("Exception while accepting follower", e);
if (fail.compareAndSet(false, true)) {
handleException(getName(), e);
halt();
}
} finally {
latch.countDown();
}
}
private void acceptConnections() throws IOException {
Socket socket = null;
boolean error = false;
try {
// 等待接收连接
socket = serverSocket.accept();
socket.setSoTimeout(self.tickTime * self.initLimit);
socket.setTcpNoDelay(nodelay);
BufferedInputStream is = new BufferedInputStream(socket.getInputStream());
// 一旦接收到 follower的请求,就创建 LearnerHandler对象,处理请求
LearnerHandler fh = new LearnerHandler(socket, is, Leader.this);
fh.start();
}
......
}
}// Follower
void followLeader() throws InterruptedException {
.......
try {
self.setZabState(QuorumPeer.ZabState.DISCOVERY);
// 找到集群中谁是Leader
QuorumServer leaderServer = findLeader();
try {
// 找到Leader后连接到Leader
connectToLeader(leaderServer.addr, leaderServer.hostname);
connectionTime = System.currentTimeMillis();
// 注册,告诉自己的状态
long newEpochZxid = registerWithLeader(Leader.FOLLOWERINFO);
if (self.isReconfigStateChange()) {
throw new Exception("learned about role change");
}
long newEpoch = ZxidUtils.getEpochFromZxid(newEpochZxid);
if (newEpoch < self.getAcceptedEpoch()) {
......
throw new IOException("Error: Epoch of leader is lower");
}
long startTime = Time.currentElapsedTime();
try {
self.setLeaderAddressAndId(leaderServer.addr, leaderServer.getId());
self.setZabState(QuorumPeer.ZabState.SYNCHRONIZATION);
syncWithLeader(newEpochZxid);
self.setZabState(QuorumPeer.ZabState.BROADCAST);
completedSync = true;
}
......
if (self.getObserverMasterPort() > 0) {
LOG.info("Starting ObserverMaster");
om = new ObserverMaster(self, fzk, self.getObserverMasterPort());
om.start();
} else {
om = null;
}
// create a reusable packet to reduce gc impact
QuorumPacket qp = new QuorumPacket();
while (this.isRunning()) {
readPacket(qp);
processPacket(qp);
}
}
......
} finally {
......
}
}// LearnerHandler
@Override
public void run() {
try {
learnerMaster.addLearnerHandler(this);
// 心跳处理
tickOfNextAckDeadline = learnerMaster.getTickOfInitialAckDeadline();
ia = BinaryInputArchive.getArchive(bufferedInput);
bufferedOutput = new BufferedOutputStream(sock.getOutputStream());
oa = BinaryOutputArchive.getArchive(bufferedOutput);
QuorumPacket qp = new QuorumPacket();
// 获取到对应的消息
ia.readRecord(qp, "packet");
......
learnerMaster.registerLearnerHandlerBean(this, sock);
// 读取 Follower发送过来的 lastAcceptedEpoch
// 选举过程中,所使用的 epoch,其实还是上一任 leader的 epoch
long lastAcceptedEpoch = ZxidUtils.getEpochFromZxid(qp.getZxid());
long peerLastZxid;
StateSummary ss = null;
long zxid = qp.getZxid();
// 创建新的EpochId
long newEpoch = learnerMaster.getEpochToPropose(this.getSid(), lastAcceptedEpoch);
long newLeaderZxid = ZxidUtils.makeZxid(newEpoch, 0);
if (this.getVersion() < 0x10000) {
// we are going to have to extrapolate the epoch information
long epoch = ZxidUtils.getEpochFromZxid(zxid);
ss = new StateSummary(epoch, zxid);
// fake the message
learnerMaster.waitForEpochAck(this.getSid(), ss);
} else {
byte[] ver = new byte[4];
ByteBuffer.wrap(ver).putInt(0x10000);
// 发送新的EpochId给follower
QuorumPacket newEpochPacket = new QuorumPacket(Leader.LEADERINFO, newLeaderZxid, ver, null);
oa.writeRecord(newEpochPacket, "packet");
messageTracker.trackSent(Leader.LEADERINFO);
bufferedOutput.flush();
QuorumPacket ackEpochPacket = new QuorumPacket();
ia.readRecord(ackEpochPacket, "packet");
messageTracker.trackReceived(ackEpochPacket.getType());
if (ackEpochPacket.getType() != Leader.ACKEPOCH) {
LOG.error("{} is not ACKEPOCH", ackEpochPacket.toString());
return;
}
ByteBuffer bbepoch = ByteBuffer.wrap(ackEpochPacket.getData());
ss = new StateSummary(bbepoch.getInt(), ackEpochPacket.getZxid());
learnerMaster.waitForEpochAck(this.getSid(), ss);
}
peerLastZxid = ss.getLastZxid();
boolean needSnap = syncFollower(peerLastZxid, learnerMaster);
boolean exemptFromThrottle = getLearnerType() != LearnerType.OBSERVER;
/* if we are not truncating or sending a diff just send a snapshot */
if (needSnap) {
syncThrottler = learnerMaster.getLearnerSnapSyncThrottler();
syncThrottler.beginSync(exemptFromThrottle);
ServerMetrics.getMetrics().INFLIGHT_SNAP_COUNT.add(syncThrottler.getSyncInProgress());
try {
long zxidToSend = learnerMaster.getZKDatabase().getDataTreeLastProcessedZxid();
oa.writeRecord(new QuorumPacket(Leader.SNAP, zxidToSend, null, null), "packet");
messageTracker.trackSent(Leader.SNAP);
bufferedOutput.flush();
// Dump data to peer
learnerMaster.getZKDatabase().serializeSnapshot(oa);
oa.writeString("BenWasHere", "signature");
bufferedOutput.flush();
} finally {
ServerMetrics.getMetrics().SNAP_COUNT.add(1);
}
} else {
syncThrottler = learnerMaster.getLearnerDiffSyncThrottler();
syncThrottler.beginSync(exemptFromThrottle);
ServerMetrics.getMetrics().INFLIGHT_DIFF_COUNT.add(syncThrottler.getSyncInProgress());
ServerMetrics.getMetrics().DIFF_COUNT.add(1);
}
LOG.debug("Sending NEWLEADER message to {}", sid);
if (getVersion() < 0x10000) {
QuorumPacket newLeaderQP = new QuorumPacket(Leader.NEWLEADER, newLeaderZxid, null, null);
oa.writeRecord(newLeaderQP, "packet");
} else {
QuorumPacket newLeaderQP = new QuorumPacket(Leader.NEWLEADER, newLeaderZxid, learnerMaster.getQuorumVerifierBytes(), null);
queuedPackets.add(newLeaderQP);
}
bufferedOutput.flush();
// Start thread that blast packets in the queue to learner
startSendingPackets();
qp = new QuorumPacket();
ia.readRecord(qp, "packet");
messageTracker.trackReceived(qp.getType());
if (qp.getType() != Leader.ACK) {
LOG.error("Next packet was supposed to be an ACK, but received packet: {}", packetToString(qp));
return;
}
LOG.debug("Received NEWLEADER-ACK message from {}", sid);
learnerMaster.waitForNewLeaderAck(getSid(), qp.getZxid());
syncLimitCheck.start();
// sync ends when NEWLEADER-ACK is received
syncThrottler.endSync();
if (needSnap) {
ServerMetrics.getMetrics().INFLIGHT_SNAP_COUNT.add(syncThrottler.getSyncInProgress());
} else {
ServerMetrics.getMetrics().INFLIGHT_DIFF_COUNT.add(syncThrottler.getSyncInProgress());
}
syncThrottler = null;
// now that the ack has been processed expect the syncLimit
sock.setSoTimeout(learnerMaster.syncTimeout());
/*
* Wait until learnerMaster starts up
*/
learnerMaster.waitForStartup();
LOG.debug("Sending UPTODATE message to {}", sid);
queuedPackets.add(new QuorumPacket(Leader.UPTODATE, -1, null, null));
while (true) {
qp = new QuorumPacket();
ia.readRecord(qp, "packet");
messageTracker.trackReceived(qp.getType());
long traceMask = ZooTrace.SERVER_PACKET_TRACE_MASK;
if (qp.getType() == Leader.PING) {
traceMask = ZooTrace.SERVER_PING_TRACE_MASK;
}
if (LOG.isTraceEnabled()) {
ZooTrace.logQuorumPacket(LOG, traceMask, 'i', qp);
}
tickOfNextAckDeadline = learnerMaster.getTickOfNextAckDeadline();
packetsReceived.incrementAndGet();
ByteBuffer bb;
long sessionId;
int cxid;
int type;
switch (qp.getType()) {
case Leader.ACK:
if (this.learnerType == LearnerType.OBSERVER) {
LOG.debug("Received ACK from Observer {}", this.sid);
}
syncLimitCheck.updateAck(qp.getZxid());
learnerMaster.processAck(this.sid, qp.getZxid(), sock.getLocalSocketAddress());
break;
case Leader.PING:
// Process the touches
ByteArrayInputStream bis = new ByteArrayInputStream(qp.getData());
DataInputStream dis = new DataInputStream(bis);
while (dis.available() > 0) {
long sess = dis.readLong();
int to = dis.readInt();
learnerMaster.touch(sess, to);
}
break;
case Leader.REVALIDATE:
ServerMetrics.getMetrics().REVALIDATE_COUNT.add(1);
learnerMaster.revalidateSession(qp, this);
break;
case Leader.REQUEST:
bb = ByteBuffer.wrap(qp.getData());
sessionId = bb.getLong();
cxid = bb.getInt();
type = bb.getInt();
bb = bb.slice();
Request si;
if (type == OpCode.sync) {
si = new LearnerSyncRequest(this, sessionId, cxid, type, bb, qp.getAuthinfo());
} else {
si = new Request(null, sessionId, cxid, type, bb, qp.getAuthinfo());
}
si.setOwner(this);
learnerMaster.submitLearnerRequest(si);
requestsReceived.incrementAndGet();
break;
default:
LOG.warn("unexpected quorum packet, type: {}", packetToString(qp));
break;
}
}
}
......
}// LearnerHandler
boolean syncFollower(long peerLastZxid, LearnerMaster learnerMaster) {
try {
......
if (forceSnapSync) {
// Force learnerMaster to use snapshot to sync with follower
LOG.warn("Forcing snapshot sync - should not see this in production");
} else if (lastProcessedZxid == peerLastZxid) {
// DIFF: 咱两一样,不需要做什么
queueOpPacket(Leader.DIFF, peerLastZxid);
needOpPacket = false;
needSnap = false;
} else if (peerLastZxid > maxCommittedLog && !isPeerNewEpochZxid) {
// TRUNC follower的 zxid比 leader的 zxid大,所以 Follower要回滚
queueOpPacket(Leader.TRUNC, maxCommittedLog);
currentZxid = maxCommittedLog;
needOpPacket = false;
needSnap = false;
} else if ((maxCommittedLog >= peerLastZxid) && (minCommittedLog <= peerLastZxid)) {
// COMMIT leader的 zxid比 follower的 zxid大,发送 Proposal给 follower提交执行
LOG.info("Using committedLog for peer sid: {}", getSid());
Iterator<Proposal> itr = db.getCommittedLog().iterator();
currentZxid = queueCommittedProposals(itr, peerLastZxid, null, maxCommittedLog);
needSnap = false;
} else if (peerLastZxid < minCommittedLog && txnLogSyncEnabled) {
long sizeLimit = db.calculateTxnLogSizeLimit();
Iterator<Proposal> txnLogItr = db.getProposalsFromTxnLog(peerLastZxid, sizeLimit);
if (txnLogItr.hasNext()) {
// 两阶段提交 先提交提案
currentZxid = queueCommittedProposals(txnLogItr, peerLastZxid, minCommittedLog, maxCommittedLog);
if (currentZxid < minCommittedLog) {
// Clear out currently queued requests and revert
// to sending a snapshot.
currentZxid = peerLastZxid;
queuedPackets.clear();
needOpPacket = true;
} else {
LOG.debug("Queueing committedLog 0x{}", Long.toHexString(currentZxid));
Iterator<Proposal> committedLogItr = db.getCommittedLog().iterator();
currentZxid = queueCommittedProposals(committedLogItr, currentZxid, null, maxCommittedLog);
needSnap = false;
}
}
// closing the resources
if (txnLogItr instanceof TxnLogProposalIterator) {
TxnLogProposalIterator txnProposalItr = (TxnLogProposalIterator) txnLogItr;
txnProposalItr.close();
}
}
......
if (needSnap) {
currentZxid = db.getDataTreeLastProcessedZxid();
}
LOG.debug("Start forwarding 0x{} for peer sid: {}", Long.toHexString(currentZxid), getSid());
leaderLastZxid = learnerMaster.startForwarding(this, currentZxid);
} finally {
rl.unlock();
}
if (needOpPacket && !needSnap) {
// This should never happen, but we should fall back to sending
// snapshot just in case.
LOG.error("Unhandled scenario for peer sid: {} fall back to use snapshot", getSid());
needSnap = true;
}
return needSnap;
}// Follower
protected void processPacket(QuorumPacket qp) throws Exception {
switch (qp.getType()) {
case Leader.PING:
ping(qp);
break;
case Leader.PROPOSAL:
// 收到提案
ServerMetrics.getMetrics().LEARNER_PROPOSAL_RECEIVED_COUNT.add(1);
TxnLogEntry logEntry = SerializeUtils.deserializeTxn(qp.getData());
TxnHeader hdr = logEntry.getHeader();
Record txn = logEntry.getTxn();
TxnDigest digest = logEntry.getDigest();
if (hdr.getZxid() != lastQueued + 1) {
LOG.warn(
"Got zxid 0x{} expected 0x{}",
Long.toHexString(hdr.getZxid()),
Long.toHexString(lastQueued + 1));
}
lastQueued = hdr.getZxid();
if (hdr.getType() == OpCode.reconfig) {
SetDataTxn setDataTxn = (SetDataTxn) txn;
QuorumVerifier qv = self.configFromString(new String(setDataTxn.getData()));
self.setLastSeenQuorumVerifier(qv, true);
}
fzk.logRequest(hdr, txn, digest);
if (hdr != null) {
long now = Time.currentWallTime();
long latency = now - hdr.getTime();
if (latency >= 0) {
ServerMetrics.getMetrics().PROPOSAL_LATENCY.add(latency);
}
}
if (om != null) {
final long startTime = Time.currentElapsedTime();
om.proposalReceived(qp);
ServerMetrics.getMetrics().OM_PROPOSAL_PROCESS_TIME.add(Time.currentElapsedTime() - startTime);
}
break;
case Leader.COMMIT:
// 收到Leader的一阶段提交提案
ServerMetrics.getMetrics().LEARNER_COMMIT_RECEIVED_COUNT.add(1);
fzk.commit(qp.getZxid());
if (om != null) {
final long startTime = Time.currentElapsedTime();
om.proposalCommitted(qp.getZxid());
ServerMetrics.getMetrics().OM_COMMIT_PROCESS_TIME.add(Time.currentElapsedTime() - startTime);
}
break;
case Leader.COMMITANDACTIVATE:
// get the new configuration from the request
Request request = fzk.pendingTxns.element();
SetDataTxn setDataTxn = (SetDataTxn) request.getTxn();
QuorumVerifier qv = self.configFromString(new String(setDataTxn.getData()));
// get new designated leader from (current) leader's message
ByteBuffer buffer = ByteBuffer.wrap(qp.getData());
long suggestedLeaderId = buffer.getLong();
final long zxid = qp.getZxid();
boolean majorChange = self.processReconfig(qv, suggestedLeaderId, zxid, true);
// commit (writes the new config to ZK tree (/zookeeper/config)
fzk.commit(zxid);
if (om != null) {
om.informAndActivate(zxid, suggestedLeaderId);
}
if (majorChange) {
throw new Exception("changes proposed in reconfig");
}
break;
case Leader.UPTODATE:
LOG.error("Received an UPTODATE message after Follower started");
break;
case Leader.REVALIDATE:
if (om == null || !om.revalidateLearnerSession(qp)) {
revalidate(qp);
}
break;
case Leader.SYNC:
fzk.sync();
break;
default:
LOG.warn("Unknown packet type: {}", LearnerHandler.packetToString(qp));
break;
}
}2.5 服务端Leader启动
// Leader
private synchronized void startZkServer() {
......
zk.startup();
......
}// ZooKeeperServer
private void startupWithServerState(State state) {
if (sessionTracker == null) {
createSessionTracker();
}
startSessionTracker();
setupRequestProcessors();
startRequestThrottler();
registerJMX();
startJvmPauseMonitor();
registerMetrics();
setState(state);
requestPathMetricsCollector.start();
localSessionEnabled = sessionTracker.isLocalSessionsEnabled();
notifyAll();
}// ZooKeeperServer
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
RequestProcessor syncProcessor = new SyncRequestProcessor(this, finalProcessor);
((SyncRequestProcessor) syncProcessor).start();
firstProcessor = new PrepRequestProcessor(this, syncProcessor);
((PrepRequestProcessor) firstProcessor).start();
}
public ZooKeeperServerListener getZooKeeperServerListener() {
return listener;
}@Override
public void run() {
LOG.info(String.format("PrepRequestProcessor (sid:%d) started, reconfigEnabled=%s", zks.getServerId(), zks.reconfigEnabled));
try {
while (true) {
ServerMetrics.getMetrics().PREP_PROCESSOR_QUEUE_SIZE.add(submittedRequests.size());
Request request = submittedRequests.take();
ServerMetrics.getMetrics().PREP_PROCESSOR_QUEUE_TIME
.add(Time.currentElapsedTime() - request.prepQueueStartTime);
long traceMask = ZooTrace.CLIENT_REQUEST_TRACE_MASK;
if (request.type == OpCode.ping) {
traceMask = ZooTrace.CLIENT_PING_TRACE_MASK;
}
if (LOG.isTraceEnabled()) {
ZooTrace.logRequest(LOG, traceMask, 'P', request, "");
}
if (Request.requestOfDeath == request) {
break;
}
request.prepStartTime = Time.currentElapsedTime();
pRequest(request);
}
} catch (Exception e) {
handleException(this.getName(), e);
}
LOG.info("PrepRequestProcessor exited loop!");
}protected void pRequest(Request request) throws RequestProcessorException {
// LOG.info("Prep>>> cxid = " + request.cxid + " type = " +
// request.type + " id = 0x" + Long.toHexString(request.sessionId));
request.setHdr(null);
request.setTxn(null);
try {
// 根据不同的请求类型进行处理
switch (request.type) {
case OpCode.createContainer:
case OpCode.create:
case OpCode.create2:
CreateRequest create2Request = new CreateRequest();
pRequest2Txn(request.type, zks.getNextZxid(), request, create2Request, true);
break;
case OpCode.createTTL:
CreateTTLRequest createTtlRequest = new CreateTTLRequest();
pRequest2Txn(request.type, zks.getNextZxid(), request, createTtlRequest, true);
break;
case OpCode.deleteContainer:
case OpCode.delete:
DeleteRequest deleteRequest = new DeleteRequest();
pRequest2Txn(request.type, zks.getNextZxid(), request, deleteRequest, true);
break;
case OpCode.setData:
SetDataRequest setDataRequest = new SetDataRequest();
pRequest2Txn(request.type, zks.getNextZxid(), request, setDataRequest, true);
break;
case OpCode.reconfig:
ReconfigRequest reconfigRequest = new ReconfigRequest();
ByteBufferInputStream.byteBuffer2Record(request.request, reconfigRequest);
pRequest2Txn(request.type, zks.getNextZxid(), request, reconfigRequest, true);
break;
case OpCode.setACL:
SetACLRequest setAclRequest = new SetACLRequest();
pRequest2Txn(request.type, zks.getNextZxid(), request, setAclRequest, true);
break;
case OpCode.check:
CheckVersionRequest checkRequest = new CheckVersionRequest();
pRequest2Txn(request.type, zks.getNextZxid(), request, checkRequest, true);
break;
case OpCode.multi:
MultiOperationRecord multiRequest = new MultiOperationRecord();
try {
ByteBufferInputStream.byteBuffer2Record(request.request, multiRequest);
} catch (IOException e) {
request.setHdr(new TxnHeader(request.sessionId, request.cxid, zks.getNextZxid(), Time.currentWallTime(), OpCode.multi));
throw e;
}
List<Txn> txns = new ArrayList<Txn>();
//Each op in a multi-op must have the same zxid!
long zxid = zks.getNextZxid();
KeeperException ke = null;
//Store off current pending change records in case we need to rollback
Map<String, ChangeRecord> pendingChanges = getPendingChanges(multiRequest);
request.setHdr(new TxnHeader(request.sessionId, request.cxid, zxid,
Time.currentWallTime(), request.type));
......
}2.6 服务端Follower启动
这块上面有,不提了
评论