

1 JUC概述
1.1 什么是JUC
JUC(java.util.concurrent)在并发编程中使用的工具类

1.2 进程和线程
是程序的⼀次执⾏,是系统进⾏资源分配和调度的独⽴单位,每⼀个进程都有它⾃⼰的内存空间和系统资源
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。程序是指令、数据及其组织形式的描述,进程是程序的实体。
进程具有的特征:
动态性:进程是程序的一次执行过程,是临时的,有生命期的,是动态产生,动态消亡的
并发性:任何进程都可以同其他进行一起并发执行
独立性:进程是系统进行资源分配和调度的一个独立单位
结构性:进程由程序,数据和进程控制块三部分组成
1.3 线程状态
1. 新建状态(New): 线程对象被创建后,就进入了新建状态。
2. 就绪状态(Runnable): 也被称为“可执行状态”。线程对象被创建后,其它线程调用了该对象的start()方法,从而来启动该线程。例如,thread.start()。处于就绪状态的线程,随时可能被CPU调度执行。
3. 运行状态(Running): 线程获取CPU权限进行执行。需要注意的是,线程只能从就绪状态进入到运行状态。
4. 阻塞状态(Blocked): 阻塞状态是线程因为某种原因放弃CPU使用权,暂时停止运行。直到线程进入就绪状态,才有机会转到运行状态。阻塞的情况分三种:
等待阻塞 -- 通过调用线程的wait()方法,让线程等待某工作的完成。
同步阻塞 -- 线程在获取synchronized同步锁失败(因为锁被其它线程所占用),它会进入同步阻塞状态。
其他阻塞 -- 通过调用线程的sleep()或join()或发出了I/O请求时,线程会进入到阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。
5. 死亡状态(Dead): 线程执行完了或者因异常退出了run()方法,该线程结束生命周期。
public enum State {
// 新建
NEW,
// 准备就绪
RUNNABLE,
// 阻塞
BLOCKED,
// 不见不散
WAITING,
// 过时不候
TIMED_WAITING,
// 终结
TERMINATED;
}1.4 start方法
public static void main(String[] args) {
Thread t1 = new Thread(() ->{
},"t1");
t1.start();
}点开start方法,底层调用的是start0方法
public synchronized void start() {
/**
* This method is not invoked for the main method thread or "system"
* group threads created/set up by the VM. Any new functionality added
* to this method in the future may have to also be added to the VM.
*
* A zero status value corresponds to state "NEW".
*/
if (threadStatus != 0)
throw new IllegalThreadStateException();
/* Notify the group that this thread is about to be started
* so that it can be added to the group's list of threads
* and the group's unstarted count can be decremented. */
group.add(this);
boolean started = false;
try {
start0();
started = true;
} finally {
try {
if (!started) {
group.threadStartFailed(this);
}
} catch (Throwable ignore) {
/* do nothing. If start0 threw a Throwable then
it will be passed up the call stack */
}
}
}start0是一个native方法,native方法表示调用了本地方法
1.5 用户线程和守护线程
线程的daemon属性为
true表示是守护线程
false表示是用户线程。
用户线程是系统的工作线程,它会完成这个程序需要完成的业务操作
守护线程是一种特殊的线程,为其他线程服务的,在后台默默地完成一些系统性的服务,比如垃圾回收线程。
public class DaemonDemo
{
public static void main(String[] args)
{
Thread t1 = new Thread(() -> {
System.out.println(Thread.currentThread().getName()+"\t 开始运行,"+(Thread.currentThread().isDaemon() ? "守护线程":"用户线程"));
while (true) {
}
}, "t1");
//线程的daemon属性为true表示是守护线程,false表示是用户线程
//---------------------------------------------
t1.setDaemon(true);
//-----------------------------------------------
t1.start();
//3秒钟后主线程再运行
try { TimeUnit.SECONDS.sleep(3); } catch (InterruptedException e) { e.printStackTrace(); }
System.out.println("----------main线程运行完毕");
}
}未加t1.setDaemon(true);,默认是用户线程,他会继续运行,所以灯亮着
加了t1.setDaemon(true);是守护线程,当用户线程main方法结束后自动退出了
守护线程作为一个服务线程,没有服务对象就没有必要继续运行了,如果用户线程全部结束了,意味着程序需要完成的业务操作已经结束了,系统可退出了。假如当系统只剩下守护线程的时候,java虚拟机会自动退出。
setDaemon(true)方法必须在start()之前设置,否则报IIIegalThreadStateException异常
在构造方法中实现了Callable接口(有返回值、可抛出异常)和Runnable接口
2 集合类不安全
2.1 ArrayList
List<String> list=new ArrayList<>();首先我们拓展几个知识点,ArrayList底层是Object类型的数组,初始容量是10(jdk7之前,jdk8之后是空引用,到add之后会变成10,类似于懒加载的机制),其扩容的方式是每次扩容为之前的一半,比如10会扩容成15,15扩容成22,扩容用到的方法时Arrays的copyof方法。
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
// 初始容量为10
private static final int DEFAULT_CAPACITY = 10;
// 添加
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
}private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
// 扩容1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}我们通过Lambda表达式来生成几个线程
for (int i = 0; i < 30; i++) {
new Thread(() -> {
list.add(UUID.randomUUID().toString().substring(0, 8));
System.out.println(list);
}, String.valueOf(i)).start();
}
// Exception in thread "3" Exception in thread "2" Exception in thread "8" java.util.ConcurrentModificationExceptionjava.util.ConcurrentModificationException并发修改异常
导致原因:多线程并发争抢统一资源,且没加锁
解决方法:
Vector
List<String> list = new Vector<>();Vector集合,底层给add方法加了synchronized(重锁),同一时间段只有一个个线程,效率低,所以这就是为什么集合安全效率低的原因。
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}synchronizedList
Collections.synchronizedList(new ArrayList<>());public static <T> List<T> synchronizedList(List<T> list) {
return (list instanceof RandomAccess ?
new SynchronizedRandomAccessList<>(list) :
new SynchronizedList<>(list));
}他底层维护了一个互斥锁
public boolean add(E e) {
synchronized (mutex) {return c.add(e);}
}CopyOnWriteArrayList
List<String> list = new CopyOnWriteArrayList<>();这个JUC包的类,实现了List接口。其add方法里面加了锁ReentrantLock:
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}CopyOnWriteArrayList读的时候不加锁,写的时候先获取锁,类似于先获得签名表,拷贝一份,然后写上自己的名字,跟大家说用这个版本,然后放回签名表
2.2 Set
Set<String> set = new HashSet<>();扩展点知识点,HashSet底层数据结构是HashMap
public HashSet() {
map = new HashMap<>();
}大家可能会奇怪,hashmap不是键值对嘛,set的add方法只插入一个值
其实add中添加的为hashmap的键,值为一个常量
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}这里设置成常量而不是为null的原因是:hashmap的put方法放回的是值
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }如果设置成空的话,那么return的表达式就永远为true了
跟list一样,当多线程访问set的时候,同样会报并发读写异常
public static void main(String[] args) {
Set<String> set = new HashSet<>();
for (int i = 0; i < 30; i++) {
new Thread(() -> {
set.add(UUID.randomUUID().toString().substring(0, 8));
System.out.println(set);
}, String.valueOf(i)).start();
}
}
// Exception in thread "13" java.util.ConcurrentModificationException解决方案
synchronizedSet
Set<String> set=Collections.synchronizedSet(new HashSet<>());和list一样,维护了一个互斥锁
public boolean add(E e) {
synchronized (mutex) {return c.add(e);}
}CopyOnWriteArraySet
Set<String> set=new CopyOnWriteArraySet();你点开源码,你会很神奇的发现
public CopyOnWriteArraySet() {
al = new CopyOnWriteArrayList<E>();
}??好家伙,说好的set呢
底层添加:
private boolean addIfAbsent(E e, Object[] snapshot) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] current = getArray();
int len = current.length;
if (snapshot != current) {
// Optimize for lost race to another addXXX operation
int common = Math.min(snapshot.length, len);
for (int i = 0; i < common; i++)
if (current[i] != snapshot[i] && eq(e, current[i]))
return false;
if (indexOf(e, current, common, len) >= 0)
return false;
}
Object[] newElements = Arrays.copyOf(current, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}实际上就是从arraylist的copyof变成了一个个遍历,然后如果中间发现了有相同元素,就返回false
2.3 Map
HashMap(无序无重复)底层是数组+链表(单向)+红黑树,HashMap存的是node,node里面存的是Key-Value,HashMap初始容量为16,负载因子为0.75(到16*0.75的时候扩容),初始容量和负载因子可以通过构造器来改,每次扩容为原值得一倍。
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final float DEFAULT_LOAD_FACTOR = 0.75f;
}首先put方法接收到key和value时会根据put的key值进行hash运算得到key对应的哈希值;
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
// 链表
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 先是通过获取的哈希值与(数组长度-1)进行与运算得到一个数组下标;
// 然后判断此下标位置是不是空着,如果空着,则直接把key和value封装为一个Node对象并存入此数组位置;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 如果此下标位置元素非空,说明此位置上存在Node对象
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 那么则判断该Node对象是不是一个红黑树节点,如果是,则将key和value封装成一个红黑树节点,并添加到红黑树上去
// 在这个过程还会判断红黑树中是否存在当前key,如果存在则更新相应的value;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 如果此位置上的Node对象时链表节点,则将key和value封装为一个链表的节点并插入到链表中去;
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// 插入到链表后,会判断链表的节点个数是不是超过了8个,如果超过了8个则把当前位置的链表转化为红黑树;
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 插入链表使用的是尾插法,所以需要遍历链表,在这个过程中会判断key是否存在,如果存在则更新相应的value。
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 最后判断当前HashMap是否超过阈值,如果超过,则进行扩容操作。
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}按照之前。。。
Map<String, String> map = new HashMap<>();
for (int i = 0; i < 30; i++) {
new Thread(() -> {
map.put(Thread.currentThread().getName(), UUID.randomUUID().toString().substring(0, 8));
System.out.println(map);
}, String.valueOf(i)).start();
}
// Exception in thread "8" Exception in thread "12" Exception in thread "13" java.util从这里就可以看出封装的好处了,连 报的错都是一样的
解决方法:ConcurrentHashMap
根据hashMap的数据结构可以直观的看到,如果以整个容器为一个资源进行锁定,那么就变为了串行操作。而根据hash表的特性,具有冲突的操作只会出现在同一槽位,而与其它槽位的操作互不影响。基于此种判断,那么就可以将资源锁粒度缩小到槽位上,这样热点一分散,冲突的概率就大大降低,并发性能就能得到很好的增强。

ConcurrentHashMap使用JUC包中通过直接操作内存中的对象,将比较与替换合并为一个原子操作的乐观锁形式(CAS)来进行简单的值替换操作,对于一些含有复杂逻辑的流程对Node节点对象使用synchronize进行同步。
Map<String, String> map = new ConcurrentHashMap();HashMap,其中Node节点类型包含两种,第一种链表,第二种红黑树。而在ConcurrentHashMap中节点类型在上述两种的基础上扩展了,两种分别是ForwardingNode和 ReservationNode。
ForwardingNode:用于解决当进行扩容的时候,进行查询的问题。
ReservationNode:用于解决当进行计算时,计算的对象为空的问题。
synchronized (f) {
//double check,如果槽位里面的数据发生变更则重新走流程
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}3 生产者消费者
两个线程操作一个变量,实现两个线程对同一个资源一个进行加1操作,另外一个进行减1操作,且需要交替实现,变量的初始值为0。即两个线程对同一个资源进行加一减一交替操作。
3.1 传统解决方法
//资源类
class Resource {
private int number = 0;
public synchronized void up() throws InterruptedException {
//1.判断
if(number != 0) {
this.wait();
}
//2.干活
number++;
System.out.println(Thread.currentThread().getName() + "\t" + number);
this.notifyAll();
}
public synchronized void down() throws InterruptedException {
if(number == 0) {
this.wait();
}
number--;
System.out.println(Thread.currentThread().getName() + "\t" + number);
this.notifyAll();
}
}
public class ThreadWaitNotifyDemo {
public static void main(String[] args) {
Resource resource = new Resource();
new Thread(() -> {
for (int i = 0; i < 10; i++) {
try {
resource.up();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "A").start();
new Thread(() -> {
for (int i = 0; i < 10; i++) {
try {
resource.down();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "B").start();
}
}这里我们通过Lambda表达式来通过匿名内部类来创建线程并启动,可以看到一个线程up方法,另外一个线程进行down方法,首先比如线程A先判断是否为0,不为0,那么此时进行加1操作,同一时刻的B线程此时判断的是number等于0,那么就进行等待操作,这个时候A线程加完了,然后通过notifyAll()方法来唤醒其他的线程,所以就完成了减的操作。
可以看到两个线程是正常的,但我们多加几个线程呢,有的为3了
举个例子,A,C线程是进行加操作,B,D是进行减操作,此时如果是0,那么B,和D线程是被wait了的对吧,A和C因为up方法被加了锁,所以只有一个方法进行加,如果此时A进行完操作,然后再notifyall,那么此时C线程也会进行up操作,因为C线程在if(number!=0){this.wait();}这里被唤醒后继续进行其他的操作了,没有继续判断number的情况,同理B,D线程也是如此,这就是因为我们是没有重新进行判断
更改方法很简单,将if改为where就可以
while (number != 0) {
this.wait();
}3.2 synchronized与Lock的区别
首先synchronized是java内置关键字,在jvm层面,Lock是个java类;
javap可以看出
synchronized底层用的是monitorenter,monitorexit
第一个monitorexit表示正常退出,第二个monitorexit表示保险,异常退出
ReentrantLock是new出来的
javap.exe" -c com.adrainty.Sample
Code:
0: new #2 // class java/lang/Object
3: dup
4: invokespecial #1 // Method java/lang/Object."<init>":()V
7: dup
8: astore_1
9: monitorenter
10: aload_1
11: monitorexit
12: goto 20
15: astore_2
16: aload_1
17: monitorexit
18: aload_2
19: athrow
20: new #3 // class java/util/concurrent/locks/ReentrantLock
23: dup
24: invokespecial #4 // Method java/util/concurrent/locks/ReentrantLock."<init>":()V
27: pop
28: return
Exception table:
from to target type
10 12 15 any
15 18 15 anysynchronized无法判断是否获取锁的状态,Lock可以判断是否获取到锁;
synchronized会自动释放锁(a 线程执行完同步代码会释放锁 ;b 线程执行过程中发生异常会释放锁),Lock需在finally中手工释放锁(unlock()方法释放锁),否则容易造成线程死锁;
用synchronized关键字的两个线程1和线程2,如果当前线程1获得锁,线程2线程等待。如果线程1阻塞,线程2则会一直等待下去,而Lock锁就不一定会等待下去,如果尝试获取不到锁,线程可以不用一直等待就结束了;
synchronized的锁可重入、不可中断、非公平,而Lock锁可重入、可判断、可公平(两者皆可)
Lock锁适合大量同步的代码的同步问题,synchronized锁适合代码少量的同步问题。
3.3 使用Lock
class Resource {
private int number = 0;
private Lock lock = new ReentrantLock(); //可重入锁
private Condition condition = lock.newCondition();
public void up() throws InterruptedException{
lock.lock();
try {
while (number != 0) {
condition.await(); //相当于wait
}
number++;
System.out.println(Thread.currentThread().getName()+"\t"+number);
condition.signalAll(); //相当于notifyAll
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public void down() throws InterruptedException{
lock.lock();
try {
while (number == 0) {
condition.await();
}
number--;
System.out.println(Thread.currentThread().getName()+"\t"+number);
condition.signalAll();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}3.4 精确唤醒
private Lock lock = new ReentrantLock();
private Condition condition1 = lock.newCondition();
private Condition condition2 = lock.newCondition();
private Condition condition3 = lock.newCondition();
public void printf5() {
lock.lock();
try {
//判断
while (number != 1) {
condition1.await();
}
//干活
for (int i = 1; i <= 5; i++) {
System.out.println(Thread.currentThread().getName() + "\t" + i);
}
//通知
number = 2; //此时B、C一直在wait状态中
condition2.signal(); //精确打击 唤醒B
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}4 锁的时机
先了解一个概念:synchronized 锁的是这个方法所在的资源类,就是这个对象,也就是同一时间段不可能有两个线程同时进到这个资源类,同一时间段,只允许有一个线程访问资源类里面的其中一个synchronized 方法!
class Phone {
public synchronized void sendEmail() throws Exception {
System.out.println("----sendEmail");
}
public synchronized void sendSMS() throws Exception {
System.out.println("----sendSMS");
}
}4.1 标准访问
写一下方法,请问是先打印邮件还是先大于短信?
public class Lock8 {
public static void main(String[] args) {
Phone phone = new Phone();
new Thread(() -> {
try {
phone.sendEmail();
} catch (Exception e) {
e.printStackTrace();
}
}, "A").start();
new Thread(() -> {
try {
phone.sendSMS();
} catch (Exception e) {
e.printStackTrace();
}
}, "B").start();
}
}虽然先执行的sendEmail,但其实是不一定的,看cpu的调度,被 synchronized 修饰的方式,锁的对象是方法的调用者,因为这两个方法锁的是同一个对象,所以先调用的先执行。
4.2 暂停
现在邮件暂停4秒,现在先打印那个?
class Phone {
public synchronized void sendEmail() throws Exception {
Thread.sleep(4000);
System.out.println("----sendEmail");
}
public synchronized void sendSMS() throws Exception {
System.out.println("----sendSMS");
}
}虽然先执行的(等待4s)sendEmail,然后接着sendSMS,但其实是不一定的,看cpu的调度,被 synchronized 修饰的方式,锁的对象是方法的调用者,因为这两个方法锁的是同一个对象,所以先调用的先执行,即先等待4s后sendEmail出现,接着sendSMS。
一个对象里面如果有多个synchronized 方法,某一时刻内,只要有一个线程去调用synchronized 方法了,那么其他的线程只能够等待,换句话说,某一时刻只能够有一个线程去访问这些synchronized方法,锁的是当前对象this,被锁定后,其他对象都不能进入到当前对象的其他synchronized 方法
4.3 普通方法
新增一个普通方法hello(),请问先打印邮件还是hello?
class Phone {
public synchronized void sendEmail() throws Exception {
Thread.sleep(4000);
System.out.println("----sendEmail");
}
public synchronized void sendSMS() throws Exception {
System.out.println("----sendSMS");
}
public void hello() {
System.out.println("----hello");
}
}结果是先打印hello,其次4s后再sendEmail,因为hello没有被synchronized 修饰。
普通方法和同步锁无关
4.4 两个资源类
两部手机,请问先打印邮件还是短信
public class Lock8 {
public static void main(String[] args) {
Phone phone = new Phone();
Phone phone1 = new Phone();
new Thread(() -> {
try {
phone.sendEmail();
} catch (Exception e) {
e.printStackTrace();
}
}, "A").start();
new Thread(() -> {
try {
phone1.sendSMS();
} catch (Exception e) {
e.printStackTrace();
}
}, "B").start();
}
}先打印的phone1的sendSMS,4s后再打印phone的sendemail,因为资源对象是不同的。
两个对象,就不是同一把锁了。
4.5 静态同步方法
两个静态同步方法,同一部手机,请问先打印邮件还是短信?
class Phone {
public static synchronized void sendEmail() throws Exception {
Thread.sleep(4000);
System.out.println("----sendEmail");
}
public static synchronized void sendSMS() throws Exception {
System.out.println("----sendSMS");
}
public void hello() {
System.out.println("----hello");
}
}4s过后先打印sendEmail,接着打印sendSMS。
此时锁的不是对象了,而是类!即锁的是phone.class!锁的是模板,Phone phone=new Phone() 锁的就是这个Phone。因为phone和phone1都是Phone的实例对象,而锁的是Phone,所以说,当phone正在执行的时候,phone1就得等着,因为锁的是模板。
4.6 同步方法加静态方法
class Phone {
public static synchronized void sendEmail() throws Exception {
Thread.sleep(4000);
System.out.println("----sendEmail");
}
public synchronized void sendSMS() throws Exception {
System.out.println("----sendSMS");
}
public void hello() {
System.out.println("----hello");
}
}先打印的sendSMS,接着4s后打印的sendEmail。原因:因为sendEmail锁的是模板的(加[static),sendSMS锁的是类的,两者是不冲突的。
5 Callable接口
5.1 利用Callable接口创建线程
//Runnable接口
class MyThreadRunnable implements Runnable {
@Override
public void run() {
}
}
//Callable
class MyThreadCallable implements Callable<Integer> {
@Override
public Integer call() throws Exception {
System.out.println("******come in here");
return 1024;
}
}对比Runnable接口和Callable接口可以看到Callable存在泛型,以及返回值,这是对原来的老技术的增强,因为存在了返回值,提高了线程的细粒度。
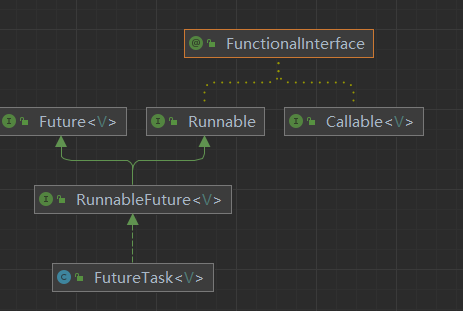
怎么通过Callable接口创建线程呢,首先Thread的构造方法并没有Callable的构造器,我们想要和一个人搭上线,最好的方法就是找一个人认识双方的,找类也一样,我们通过api文档可以看到一个类FutureTask
public FutureTask(Callable<V> callable) {
if (callable == null)
throw new NullPointerException();
this.callable = callable;
this.state = NEW; // ensure visibility of callable
}
public FutureTask(Runnable runnable, V result) {
this.callable = Executors.callable(runnable, result);
this.state = NEW; // ensure visibility of callable
}
}
创建线程:
public class CallableDemo {
public static void main(String[] args) {
FutureTask futureTask = new FutureTask(new MyThreadCallable());
new Thread(futureTask, "A").start();
System.out.println(futureTask.get());// 1024 通过get方法来获取返回值
}
}同时,callable是一个函数式接口,因此可以用作lambda表达式或方法引用的赋值对象。
Callable<Integer> callable = () -> {return 1024;};
new Thread(new FutureTask<>(callable)).start();5.2 FutureTask
在主线程中需要执行比较耗时的操作时,但又不想阻塞主线程时,可以把这些作业交给Future对象在后台完成,当主线程将来需要时,就可以通过Future对象获得后台作业的计算结果或者执行状态。一般FutureTask多用于耗时的计算,主线程可以在完成自己的任务后,再去获取结果。仅在计算完成时才能检索结果;如果计算尚未完成,则阻塞 get 方法。一旦计算完成,就不能再重新开始或取消计算。get方法而获取结果只有在计算完成时获取,否则会一直阻塞直到任务转入完成状态,然后会返回结果或者抛出异常。 只计算一次get方法放到最后
public class Sample {
public synchronized static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask<Integer> futureTask = new FutureTask<>(()->{
System.out.println(Thread.currentThread().getName()+" come in callable");
TimeUnit.SECONDS.sleep(4);
return 1024;
});
FutureTask<Integer> futureTask2 = new FutureTask<>(()->{
System.out.println(Thread.currentThread().getName()+" come in callable");
TimeUnit.SECONDS.sleep(4);
return 2048;
});
new Thread(futureTask,"zhang3").start();
new Thread(futureTask2,"li4").start();
System.out.println(futureTask.get());
System.out.println(Thread.currentThread().getName()+" come over");
}
}注意,get方法具有阻塞效果
6 JUC辅助类
6.1 CountDownLatch减少计数
CountDownLatch主要有两个方法,当一个或多个线程调用await方法时,这些线程会阻塞。 其它线程调用countDown方法会将计数器减1(调用countDown方法的线程不会阻塞), 当计数器的值变为0时,因await方法阻塞的线程会被唤醒,继续执行。
public class Sample {
public static void main(String[] args) throws ExecutionException, InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(6);
for (int i = 1; i <=6; i++) { //6个上自习的同学,各自离开教室的时间不一致
new Thread(() -> {
System.out.println(Thread.currentThread().getName()+"\t 号同学离开教室");
countDownLatch.countDown();
}, String.valueOf(i)).start();
}
countDownLatch.await();
System.out.println(Thread.currentThread().getName()+"\t****** 班长关门走人,main线程是班长");
}
}6.2 CyclicBarrier循环栅栏
CyclicBarrier的字面意思是可循环(Cyclic)使用的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞, 直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。线程进入屏障通过CyclicBarrier的await()方法。
public class Sample {
private static final int NUMBER = 7;
public static void main(String[] args) throws ExecutionException, InterruptedException {
//CyclicBarrier(int parties, Runnable barrierAction)
CyclicBarrier cyclicBarrier = new CyclicBarrier(NUMBER, ()->{
System.out.println("*****集齐7颗龙珠就可以召唤神龙");
});
for (int i = 1; i <= 7; i++) {
new Thread(() -> {
try {
System.out.println(Thread.currentThread().getName()+"\t 星龙珠被收集 ");
cyclicBarrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}}, String.valueOf(i)).start();
}
}
}6.3 Semaphore信号灯
在信号量上我们定义两种操作:
acquire(获取)当一个线程调用acquire操作时,它要么通过成功获取信号量(信号量减1),要么一直等下去,直到有线程释放信号量,或超时。
release(释放)实际上会将信号量的值加1,然后唤醒等待的线程。
信号量主要用于两个目的,一个是用于多个共享资源的互斥使用,另一个用于并发线程数的控制。
public class Sample {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Semaphore semaphore = new Semaphore(3);//模拟3个停车位
for (int i = 1; i <=6; i++) { //模拟6部汽车
new Thread(() -> {
try {
semaphore.acquire();
System.out.println(Thread.currentThread().getName()+"\t 抢到了车位");
TimeUnit.SECONDS.sleep(new Random().nextInt(5));
System.out.println(Thread.currentThread().getName()+"\t------- 离开");
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
semaphore.release();
}
}, String.valueOf(i)).start(); }
}
}7 ReentrantReadWriteLock读写锁
多个线程同时读一个资源类没有任何问题,所以为了满足并发量,读取共享资源应该可以同时进行。 但是,如果有一个线程想去共享资源类,就不应该再有其他线程可以对该资源进行读或写。
public class Sample {
public static void main(String[] args) throws ExecutionException, InterruptedException {
MyCache myCache = new MyCache();
for (int i = 1; i <= 5; i++) {
final int num = i;
new Thread(() -> {
myCache.put(num + "", num + "");
}, String.valueOf(i)).start();
}
for (int i = 1; i <= 5; i++) {
final int num = i;
new Thread(() -> {
myCache.get(num + "");
}, String.valueOf(i)).start();
}
}
}
class MyCache{
private volatile Map map = new HashMap<>();
private ReadWriteLock rwLock = new ReentrantReadWriteLock();
public void put(String key,Object value) {
rwLock.writeLock().lock();
try {
System.out.println(Thread.currentThread().getName() + "\t 正在写" + key);
//暂停一会儿线程
try {TimeUnit.MILLISECONDS.sleep(300); } catch (InterruptedException e) { e.printStackTrace(); }
map.put(key, value);
System.out.println(Thread.currentThread().getName() + "\t 写完了" + key);
} catch (Exception e) {
e.printStackTrace();
} finally {
rwLock.writeLock().unlock();
}
}
public Object get(String key) {
rwLock.readLock().lock();
Object result = null;
try {
System.out.println(Thread.currentThread().getName() + "\t 正在读" + key);
try { TimeUnit.MILLISECONDS.sleep(300); } catch (InterruptedException e) { e.printStackTrace();}
result = map.get(key);
System.out.println(Thread.currentThread().getName() + "\t 读完了" + result);
} catch (Exception e) {
e.printStackTrace();
} finally {
rwLock.readLock().unlock();
} return result;
}
}可以看到我们对写保持了一致性,读保证了可并发读,防止了在写的时候进行了读的操作,所以这就是读写锁的作用 。
读读共存 读写不共存 写写不共存
8 BlockingQueue阻塞队列
BlockingQueue(阻塞队列)是什么?
当队列为空时,从队列中获取元素将阻塞。
当队列为满时,从队列中添加元素将阻塞。
因为是队列,所以我们理应想到先进先出。
在多线程领域:所谓阻塞,在某些情况下会挂起线程(即阻塞),一旦条件满足,被挂起的线程又会自动被唤起为什么需要BlockingQueue好处是我们不需要关心什么时候需要阻塞线程,什么时候需要唤醒线程,因为这一切BlockingQueue都给你一手包办了在concurrent包发布以前,在多线程环境下,我们每个程序员都必须去自己控制这些细节,尤其还要兼顾效率和线程安全,而这会给我们的程序带来不小的复杂度。
BlockingQueue架构上分为
ArrayBlockingQueue:由数组结构组成的有界阻塞队列。
LinkedBlockingQueue:由链表结构组成的有界(但大小默认值为integer.MAX_VALUE)阻塞队列。
PriorityBlockingQueue:支持优先级排序的无界阻塞队列。
DelayQueue:使用优先级队列实现的延迟无界阻塞队列。
SynchronousQueue:不存储元素的阻塞队列,也即单个元素的队列。
LinkedTransferQueue:由链表组成的无界阻塞队列。
LinkedBlockingDeque:由链表组成的双向阻塞队列。
在方法上分为抛出异常、特殊值、阻塞和超时四种
异常:
当阻塞队列满时,插入会报
IllegalStateException:Queue full当阻塞队列空时,移除会报
NoSuchElementException
特殊值:
插入方法,成功true,失败false
移除方法,成功返回队列元素,没有就返回null
阻塞:
当队列满时,put会阻塞直到可以put或中断退出
当队列空时,take会阻塞直到队列可用
超时退出:当队列满时,队列会阻塞生产者线程一定时间,超过时限后会执行拒绝策略
public class BlockingQueueDemo {
public static void main(String[] args) {
BlockingQueue<String> blockingQueue=new ArrayBlockingQueue<>(3);
System.out.println(blockingQueue.add("a"));
System.out.println(blockingQueue.add("b"));
System.out.println(blockingQueue.add("c"));
System.out.println(blockingQueue.add("x"));
}
}9 ThreadPool线程池
9.1 线程池的优点
线程池的优势:线程池做的工作只要是控制运行的线程数量,处理过程中将任务放入队列,然后在线程创建后启动这些任务,如果线程数量超过了最大数量,超出数量的线程排队等候,等其他线程执行完毕,再从队列中取出任务来执行。
它的主要特点为:线程复用;控制最大并发数;管理线程。
第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的销耗。第二:提高响应速度。当任务到达时,任务可以不需要等待线程创建就能立即执行。第三:提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会销耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
9.2 线程池的三种方法
Java中的线程池是通过Executor框架实现的,该框架中用到了Executor,Executors,ExecutorService,ThreadPoolExecutor这几个类
Executors创建线程的三种方法:
ExecutorService threadPool = Executors.newFixedThreadPool(5); //固定容量
ExecutorService threadPool = Executors.newSingleThreadExecutor(); //单例的、单个线程的线程池
ExecutorService threadPool = Executors.newCachedThreadPool(); //缓存的 即超出就自动创建线程的newFixedThreadPool:执行长期任务性能好,创建一个线程池,一池有N个固定的线程,有固定线程数的线程
newSingleThreadExecutor:一个任务一个任务的执行,一池一线程
newCachedThreadPool:执行很多短期异步任务,线程池根据需要创建新线程,但在先前构建的线程可用时将重用它们。可扩容,遇强则强
9.3 线程池的七大参数
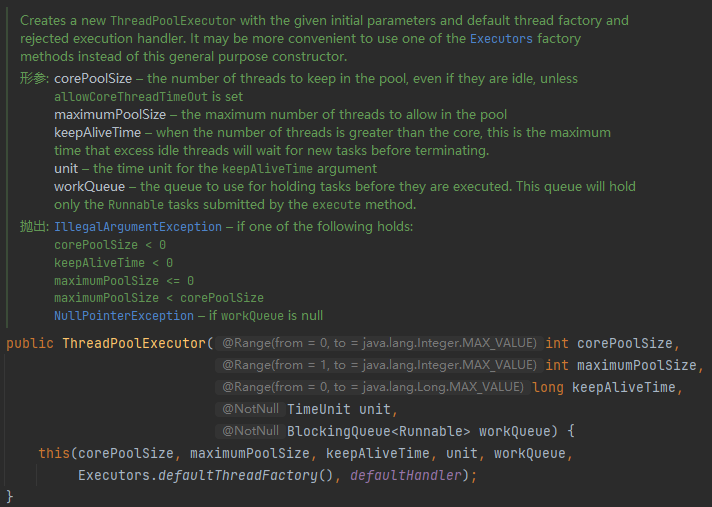
corePoolSize:线程池中的常驻核心线程数
maximumPoolSize:线程池中能够容纳同时执行的最大线程数,此值必须大于等于1
keepAliveTime:多余的空闲线程的存活时间。当前池中线程数量超过corePoolSize时,当空闲时间达到keepAliveTime时,多余线程会被销毁直到只剩下corePoolSize个线程为止
unit:keepAliveTime的单位
workQueue:任务队列,被提交但尚未被执行的任务,是一个阻塞队列
threadFactory:表示生成线程池中工作线程的线程工厂,用于创建线程,一般默认的即可
handler:拒绝策略,表示当队列满了,并且工作线程大于等于线程池的最大线程数(maximumPoolSize)时如何来拒绝请求执行的runnable的策略
9.4 JDK内置的拒绝策略
拒绝策略:等待队列已经排满了,再也塞不下新任务了同时,线程池中的max线程也达到了,无法继续为新任务服务。这个是时候我们就需要拒绝策略机制合理的处理这个问题。
AbortPolicy(默认):直接抛出RejectedExecutionException异常阻止系统正常运行
CallerRunsPolicy:“调用者运行”一种调节机制,该策略既不会抛弃任务,也不 会抛出异常,而是将某些任务回退到调用者,从而降低新任务的流量。
DiscardOldestPolicy:抛弃队列中等待最久的任务,然后把当前任务加人队列中 尝试再次提交当前任务。
DiscardPolicy:该策略默默地丢弃无法处理的任务,不予任何处理也不抛出异常。 如果允许任务丢失,这是最好的一种策略。
以上内置拒绝策略均实现了RejectedExecutionHandle接口
9.5 线程池的工作原理
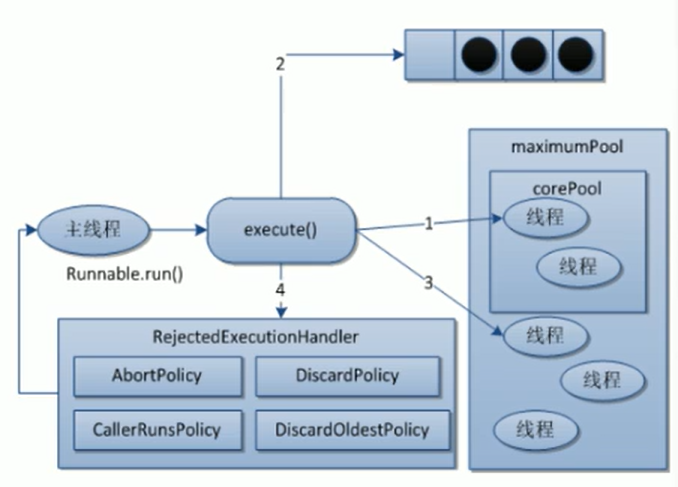
看上图以及参数解析对照我们可以知道maximumPool包含corePool,maximumPool表示最多能放的线程数,而corePool表示的就是线程的常驻数,可以理解为银行的有最多有5个受理窗口,但是常用的却只有2个,而候客区就相当于我们的阻塞队列(BlockingQueue),那当我们的阻塞队列满了之后,handle拒绝策略出来了,相当于银行门口立了块牌子,上面写着不办理后面的业务了!然后当客户都办理的差不多了,此时多出来(在corePool的基础上扩容的窗口)的窗口在经过keepAliveTime的时间后就关闭了,重新恢复到corePool个受理窗口。
首先线程池接收到任务,先判断核心线程数是否满了,没有满接客,满了就放到阻塞队列,如果阻塞队列没满,这些任务放在阻塞队列,如果满了,就扩容线程数到最大线程数,如果最大线程数也满了,就是我们的拒绝策略。这就是线程池四大步骤。 接客、放入队列,扩容线程,拒绝策略!
9.6 创建线程池
实际开发中,我们不能通过Executor框架创建线程池
//这是Single的
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
}
//点进去LinkedBlockQueue
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
//这是Cahed的
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());Executor返回线程池弊端:
允许请求队列长度为Integer.MAX_VALUE,可能会堆积大量请求,导致OOM
允许创建的线程数量为Integer.MAX_VALUE,可能会创建大量线程,导致OOM
因此,实际开发中我们需要通过自定义ThreadPoolExecutor方式创建线程池
public class Sample {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService threadPool = new ThreadPoolExecutor(2,5,2L, TimeUnit.SECONDS,
new ArrayBlockingQueue(3), Executors.defaultThreadFactory(), new ThreadPoolExecutor.DiscardOldestPolicy()
);
//10个顾客请求
try {
for (int i = 1; i <= 10; i++) {
threadPool.execute(() -> {
System.out.println(Thread.currentThread().getName() + "\t 办理业务");
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
threadPool.shutdown();
}
}
}10 volatile关键字
volatile是java虚拟机提供的轻量级的同步机制
volatile的三个特性:
保证可见性
不保证原子性
禁止指令重排
10.1 保证可见性
10.1.1 JMM
JMM(Java Memory Model,JMM)内存模型,本身是一种抽象的概念并不真实存在,它描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式,JMM关于同步的规定:
线程解锁前,必须把共享变量的值刷新回内存
线程加锁前,必须读取主内存最新的值到自己的工作内存
加锁解锁是用一把锁
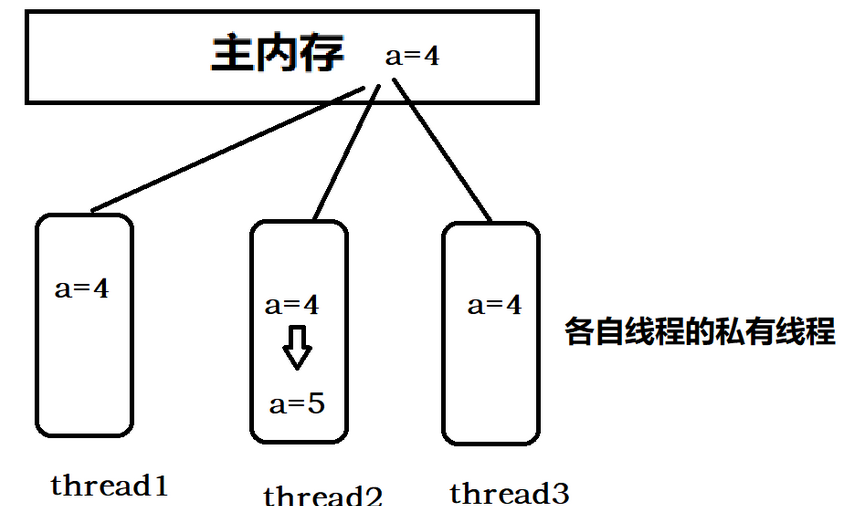
由于JVM运行内存的实体是线程,而每个线程创建的时候JVM都会为其创建一个工作内存(栈空间),工作内存是每个线程的私有区域,而Java内存模型中规定所有变量都存储在主内存,主内存是共享内存区域,所有线程都可以访问,但线程对变量的操作(读取赋值等)必须在工作内存中进行,首先要将变量从主内存中拷贝到自己的工作内存空间,然后对变量进行操作,操作完成后再将变量写会主内存,不能直接操作主内存中的变量,各个线程中的工作内存中存储着主内存中的变量副本拷贝,因此不同的线程间无法访问对方的工作内存,线程间的通信(传值)必须通过主内存完成。
而当变量使用了volatile关键字后,就能够保证当前线程一旦修改了从主内存拷贝过来的值后(此时值拷贝到了当前线程的私有内存),能够马上被其他拷贝了主内存的值的线程知道。(保证每个线程都能从主内存中取最新的值(该变量被volatile修饰))
10.1.2 可见性验证
class Data {
int number = 0;
public void add() {
this.number = 60;
}
}
public class VolatileDemo {
public static void main(String[] args) {
Data data = new Data();
//线程thread1
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "\t come in");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
data.add();
System.out.println(Thread.currentThread().getName() + "\t update number");
}, "thread1").start();
//线程main
while (data.number == 0) {
//当number的值一直为0则死循环
}
System.out.println(Thread.currentThread().getName() + "\t mission is down main get number:" + data.number);
}
}首先资源类Date定义了一个变量number,暴露了一个方法来修改这个值,接着看我们的main,main是一个线程,接着有个新的线程thread1,main线程死循环,当data的值变成60之前一直卡着,同时thread1线程修改这个data的值,但是修改完之后,main线程依旧卡在while循环里面。
通过上面介绍的JMM内存模型与可见性,我们可以知道,主线程拷贝的那份数据一直为0,没有因为thread1线程的修改这个值后而发生改变。
10.2 不保证原子性
原子性就是不可分割,完整性,也即某个线程正在做某个具体业务的时,中间不可以被加塞或者被分割,需要整体完整。要么同时成功,要么同时失败。
根据JMM的介绍,这就可能存在一个线程A修改了共享变量x的值但还未写回主内存时,另外一个线程BBB又对主内存中同一个共享变量x进行操作,但此时AAA线程工作内存中共享变量x对线程B来说并不可见,这种工作内存与主内存同步延迟现象就造成了可见性问题。(即将数据取出来加一再塞回主内存这一个操作不是原子操作)
class Data {
volatile int number = 0;
public void addPlus() {
number++;
}
}
public class VolatileDemo {
public static void main(String[] args) {
Data data = new Data();
for (int i = 1; i <= 10; i++) {
new Thread(() -> {
for(int j=0;j<1000;j++){
//上面为验证原子性 下面为使用AtomicInteger来保证原子性的操作
data.addPlus();
}
}, "Thread" + i).start();
}
//需要等待上面20个线程都全部计算完成后,再用main线程取得最终的结果值看是多少
// 一个是main线程 一个是gc线程
while (Thread.activeCount()>2){
Thread.yield();
}
System.out.println(Thread.currentThread().getName()+"线程获取的number值为"+data.number);
}
}由上述代码我们可以知道,10个线程,每个线程都对资源进行了1000次的自增操作,并且加上了volatile保证了可见性,但是结果却少于10000,这就验证了原子性并不能够保证,存在工作内存与主内存同步延迟现象。
解决这种原子可见性的问题
第一种办法自然是加上synchronized
class Data {
volatile int number = 0;
public synchronized void addPlus() {
number++;
}
}但是杀鸡焉用牛刀,这里可以用另一种办法。即使用原子类,JUC下的AtomicInteger
class Data {
/**
* 原子类
*/
AtomicInteger atomicInteger=new AtomicInteger(0);
/**
* 原子的自增操作
*/
public void addAtomicInteger(){
atomicInteger.getAndIncrement();
}
}可以看到底层用的是Unsafe类
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}Java 不能直接访问操作系统底层,而是通过本地方法来访问。Unsafe 类提供了硬件级别的原子操作。
10.3 指令重排
编写的代码在JVM执行的时候,为了提高性能,编译器和处理器都会对代码编译后的指令进行重排序。分为3种:
编译器优化重排:编译器的优化前提是在保证不改变单线程语义的情况下,对重新安排语句的执行顺序。
指令并行重排:如果代码中某些语句之间不存在数据依赖,处理器可以改变语句对应机器指令的顺序
处理器和主内存之间还存在一二三级缓存。这些读写缓存的存在,使得程序的加载和存取操作,可能是乱序无章的。
在单线程的条件下,指令重排不会影响到最终的结果,也就是数据的一致性可以得到保证;但是再多线程的条件下,各种线程交替执行,两个线程间使用的变量能否保证一致性就不能得到保证。
10.4 volatile例子
DCL(Double Check Lock双端检锁机制) 双重锁校验
public class SingletonDemo {
/**
* 排除指令重排的情况
*/
private volatile static SingletonDemo instance = null;
private SingletonDemo() {
System.out.println("初始化构造器!");
}
/**
* 双重锁校验 加锁前和加锁后都进行判断
*/
public static SingletonDemo getInstance() {
if (null == instance) {
synchronized (SingletonDemo.class) {
if (null == instance) {
instance = new SingletonDemo();
}
}
}
return instance;
}
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
new Thread(new Runnable() {
@Override
public void run() {
SingletonDemo.getInstance();
}
}, i + "").start();
}
}
}我们可以看到构造器仅仅初始化了一次,就说明这是个线程拿到的都是单例的。
评论